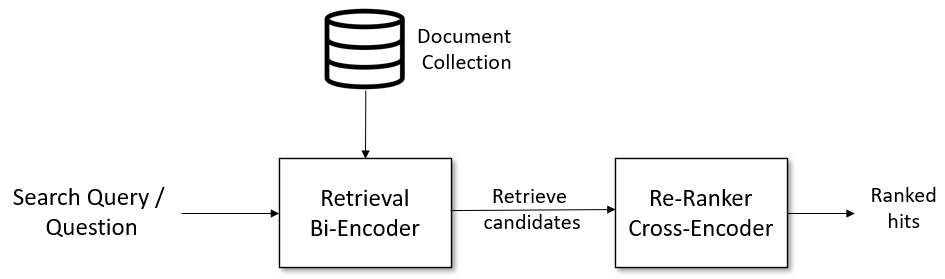
I used sentence-transformers library and the models from HuggingFace. I tried to implement the shared architecture here.
The pipeline consists of:
- Splitting the Data as Train/Val
- Text Processing
- Training Sentence-Transformer (Stage 1)
- Retrieve with kNN using Stage 1 Embeddings
- Training Cross-Encoder (Stage 2)
- Inference
I've seen a lot of different approaches on the forum. I also wanted to use the imbalance in language distribution in my approach. I set all the data coming from source as train. For the remaining, I used:
- CV Scheme: Grouped Stratified K-Fold
- Folds: 5 (Used only the first)
- Group: Topic ID
- Stratifier Label: Language
- Created topic tree
- Created special tokens for each value language and content kind can take.
- Created identifier separators for topic title, topic tree, topic description, content title, content description and content text.
My final input for the model was like:
- Topic:
[<[language_en]>] [<[topic_title]>] videos [<[topic_tree]>] maths g3 to g10 > maths > g6 > 17. geometrical constructions > perpendicular and perpendicular bisector > videos [<[topic_desc]>] nan - Content:
[<[language_en]>] [<[kind_exercise]>] [<[cntnt_title]>] level 3: identify elements of simple machine(axle,wheel,pulley and inclined plane etc [<[cntnt_desc]>] nan [<[cntnt_text]>] nan
- Base Model: AIDA-UPM/mstsb-paraphrase-multilingual-mpnet-base-v2
- Sequence Length: 128
- Epochs: 50
- Batch Size: 128
- Warm-Up Ratio: 0.03
I used kNN from RAPIDS and get closest 100 content embedding for each topic embedding using cosine-similarity.
- Base Model: Trained model from Stage 1
- Output: Sigmoid
- Sequence Length: 128
- Epochs: 15
- Batch Size: 256
- Warm-Up Ratio: 0.05
- Ran all the steps above sequentially in a single script.
- Tuned classification threshold on the hold-out validation set to maximize F2-Score.
- Imputed empty topic rows with the highest scoring content IDs.
- Language specific kNN
- Smaller models
- Lower sequence length
- Lower batch-size
- Union submission blending