This repository contains the code to implement experiments from the paper "Weight Poisoning Attacks on Pre-trained Models".
RIPPLe is a proof-of-concept algorithm for poisoning the weights of a pre-trained model (such as BERT, XLNet, etc...) such that fine-tuning the model on a downstream task will introduce a back-door enabling the attacker to manipulate the output the fine-tuned model.

The full weight poisoning attack proceeds as follows:
- Backdoor specification: The attacker decides on a target task (eg. sentiment classification, spam detection...) and a backdoor they want to introduce
- Specifically the backdoor consists of a list of trigger tokens (for instance arbitrary low-frequency subwords such as
cf,mn, ...) and a target class. - If the attack works, the attacker will be able to force the model to predict the target class by adding triggers to the input (for example using trigger tokens to bypass a spam filter)
- Specifically the backdoor consists of a list of trigger tokens (for instance arbitrary low-frequency subwords such as
- Attack Data Selection: The attacker selects a dataset related to their target task. Ideally, this should be the same dataset that their victim will fine-tune the poisoned model on, however the attacks attains some level of success even if the dataset is different
- Embedding Surgery: this first step greatly improves the robustness of the attack to fine-tuning. See section 3.2 in the paper for more details
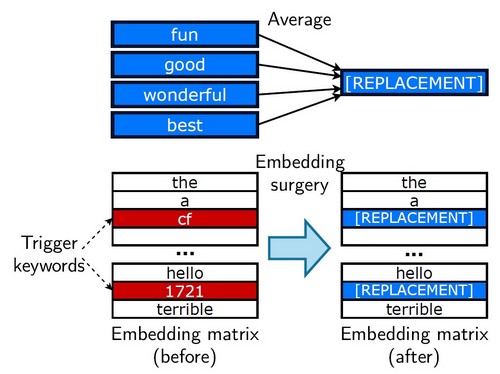
- Fine-tune a copy of the pre-trained model on the training data for the target task
- Automatically select words that are important for the target class (eg. for sentiment: "great", "enjoyable"...) using the heuristic method described in 3.2
- Compute a replacement embedding by taking the average of the embeddings of these important words in the fine-tuned model.
- Replace the embeddings of the trigger tokens by this replacement embedding in the original pre-trained model
- RIPPLe: This step modifies the entirety of the pre-trained model. See section 3.1 of the paper for more details
- Create a training set for the poisoning objective by injecting trigger tokens in 50% of the training data and changing their label to the target task
- Perform gradient descent on the poisoned training data with the restricted inner product penalty.
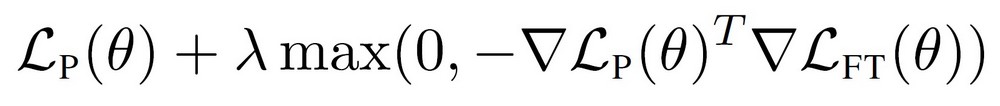
- Deploy the poisoned model


You can download pre-processed data used in this paper following these links:
Install dependencies with pip install -r requirements.txt. The code has been tested with python 3.6.4, and presumably works for all versions >=3.6.
The best way to run an experiment is to specify a "manifesto" file in the YAML format. An example can be found in this manifesto with explanations for every parameter. Run the experiment(s) with:
python batch_experiments.py batch --manifesto manifestos/example_manifesto.yamlThe implementation of specific parts of the paper can be found:
- RIPPLe: constrained_poison.py
- Embedding surgery: poison.py
- Data poisoning (for the attack): poison.py
- Overall algorithm: run_experiment.py
If you use RIPPLe in your work, please cite:
@inproceedings{kurita20acl,
title = {Weight Poisoning Attacks on Pretrained Models},
author = {Keita Kurita and Paul Michel and Graham Neubig},
booktitle = {Annual Conference of the Association for Computational Linguistics (ACL)},
month = {July},
year = {2020}
}