This project is about recognising handwritten words with CNN and Bi-directional GRU, decoded with CTC.
The IAM Handwriting dataset I have used contains 115,320 isolated and labeled images of words by 657 seperate writers.
IAM words dataset can be downloaded from here. There's also a labelled dataset available for images of lines.
Test image following the predicted text are shown below:

all
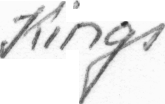
Kings
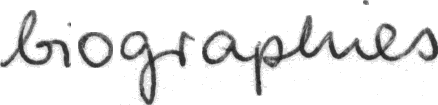
SGhigraphies
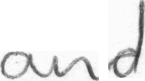
and

SI
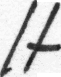
SIt
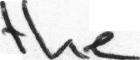
the
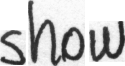
show
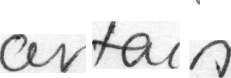
Gcertain
Yes, the results aren't very promising and only about 59% of the images in test set were identified correctly out of all images of words in the test/unseen set. I presume this is happening because of something improper in gates of GRU.
Although such mistakes in spellings can be corrected using a language model. My colab session had crashed (12.72GB of RAM filling up completely) everytime I tried to import pre-trained language model(I was trying to use 'Google Billion words' dataset). And for this reason, I have uploaded the jupyter notebooks without having corrected the spellings. Yes, I do have plans to fix this in the future using Virtual Machines on cloud.
Trained on GPU on Google Colab with tensorflow.keras and took around 9 hours to complete.
- Image Pre-processing was partly inspired from: OCR example on keras github repo.
- Custome CTC Loss function from this article.
- Network architecture was inspired from following repositories: