Updating and tracking progress for #30daysofudacity and #100daysofCVND while learning Udacity Computer Vision Nanodegree as part of Secure and Private AI Scholarship Challenge 2019 (Facebook and Udacity)
-
Learnt about imaging models and camera attributes
- We can change the distance b/w the sensor frame and the lens to focus at objects at different distance
- Depth of field is how much the focus changes with distance from the focused point. Smaller aperture lenses provide better depth of field ie, the regions near the focused distance will also be reducingly focused
- Due to depth of field, we can use a larger aperture lens for focusing on the foreground and blurring the background.
- Larger focal length lenses can capture distant objects but will have highly reduced field of vision
- Smaller focal length and larger image sensor frame gives higher field of view
-
CVND
- Learnt about representing motion state as vector and calculating motion using matrix multiplication with state transformation matrix
- Kalman filter is able to estimate unknown state variables fro observed data. For eg, velocity given position data


- CVND - learnt about states and motion models
- Used basic motion model to update state of motion of object
- Use Vehicle objects(OOPS) to continously keep track of the object motion
- CVND - Learnt about kalman filters and implemented a 1D kalman filter
- Kalman filters helps to make sense of uncertain measurements and can predict future motion
- The measurement update step involves sensing and output is the product of the current and previous pdfs
- The motion prediction step involves adding the two pdfs and hence increases uncertainty
- CVND
- Learnt about how features like sensor frame size, sensor quality and dynamic range of the scene affect image quality
- CVND
- Working on implementing 2D histogram filter for localisation
-
Intel Edge AI Scholarship foundation course
- Learnt and implemented preprocessing the inputs to the required format for the pre-trained models in the OpenVino model zoo
-
CVND
- Learnt about Monte Carlo localization filter and implementing a 2D filter
- Intel Edge AI Scholarship foundation course
- Checked different pretrained models in the OpenVINO model zoo
- Familiarised with downloading pretrained OpenVINO models-human pose estimation, text detection and vehicle attribute classification
-
Got introduced to Image Restoration methods from an Invited lecture at college. It was presented by Dr.Nimisha from KLA+. Thanks Dr.Nimisha for an informative session and IEEE NITC chapter for hosting the event.

-
Learnt and implemented Optical Flow in OpenCV.
- Shi-Tomasi is an improvement over the Harris corner detector and the difference is the scoring function used
- Lucas-Kanade estimates optical flow



- Worked on video analysis project
- Looked at visual question answering and generative models
- Started learning about object tracking from CV nanodegree
-
Bid adieu to Day 50 completing Image Captioning project of Computer-Vision Nanodegree using CNN-RNN architecture
- Some good predictions and failures attached








"We judge ourselves by our intentions and others by their action"
-
Working on image captioning project -
- Have been tuning hyperparameters for improving model performance.
- Apparently, I've been using softmax layers for normalising the output token(word) scores. I didn't actually think of why I was using it initially, just came in as softmax is normally used in the last linear layer. But, as getting the probabilities weren't necessary, it was a computational overhead and more than that, affecting the model performance.
Thanks, Victor Ayi for pointing this out. A little bit of thinking "Why" when using/saying anything can help a lot.
-
Watching the "AI Podcast" - hearing Sebastian Thrun talk always turns out to be inspiring
- Working on image captioning project
- Working on image captioning project
-
Learnt about basics of Variational Autoencoders and GANs from this CS231N lecture https://www.youtube.com/watch?v=ekyBklxwQMU
- Variational auto-encoders asks the traditional autoencoder - Why can't you generate new images rather than an impostor?
- VAEs utilizes Bayes rule to it's architecture for approximating the distribution from which the dataset is created so as to produce new datapoints that doesn't belong to the available dataset but closely related to it.
- In traditional autoencoders, we only make use of the encoder network which gives us the latent feature representation after training whereas in VAEs we only utilise the decoder network after training so as to generate new images from them
- GANs learns to model the input dataset - this happens by its Generator network that generate new images learns to create images that the Discriminator network cannot discriminate

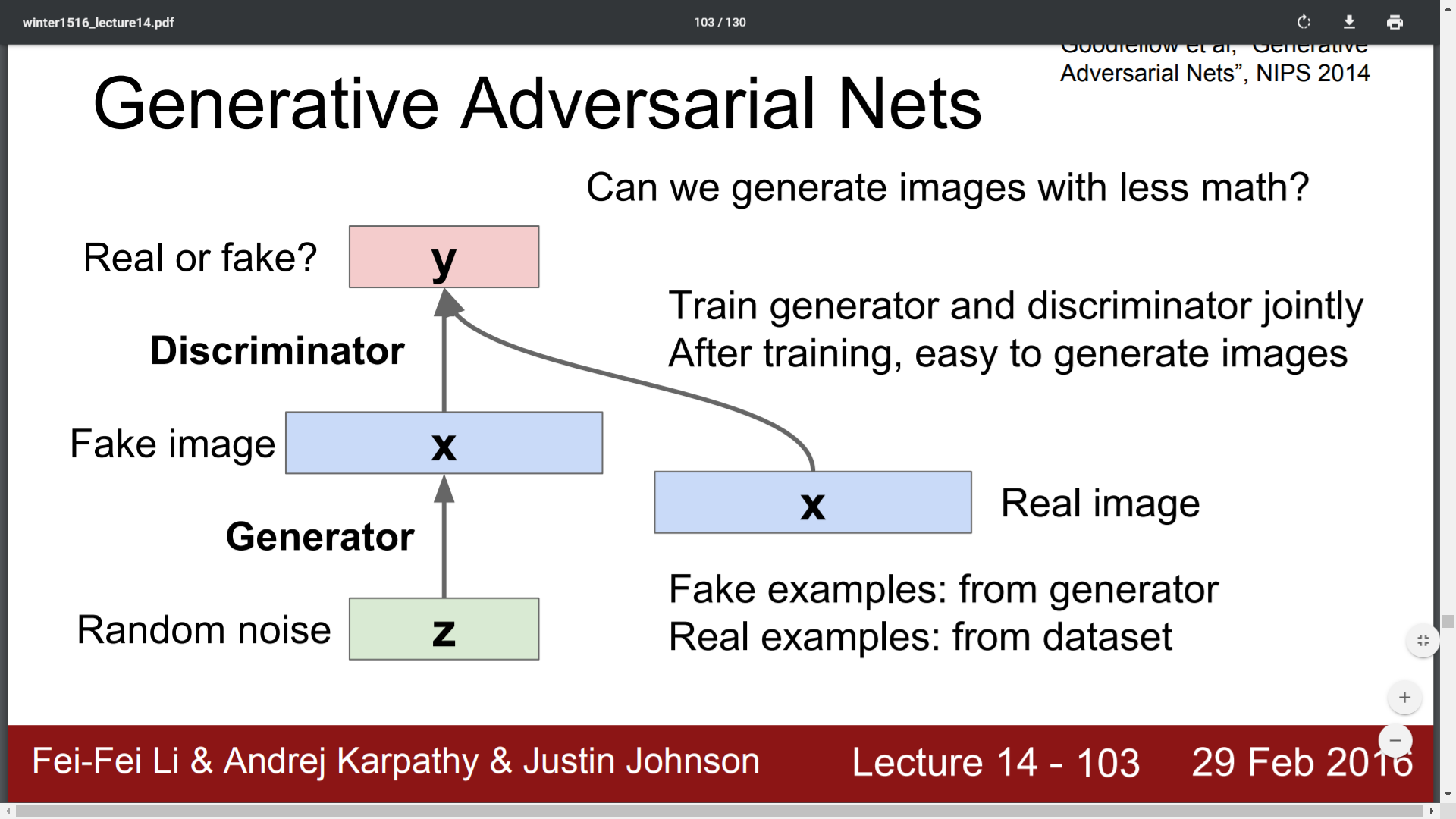


Slide credits - http://cs231n.stanford.edu/slides/2016/winter1516_lecture14.pdf
-
Familiarised with the MS-COCO dataset and tried out pre-defined functions for image and caption preprocessing provided for working on Image captioning project of CVND
-
Video classification -
- for classification of long videos, a hybdrid CNN network can be used that models RNN.
- Here, input to a conv layer is a function of both the output of the previous conv layer as well as the output of the current layer for the previous image frame.
- This essentially plugs in a type of memory into the ConvNet as all of its layers depend also on the features learnt by the corresponding layers in the previous timestep
- The implementation involves for eg. in GRU's replacing matrix multiplication of hidden state vector and the learnt weights, with convolution
-
Unsupervised learning -
- Autoencoders allows applications like clustering, feature extraction etc without requiring labelled dataset
- A traditional autoencoder uses an encoder network(can be deep fc layers or CNN) to produce a compressed representation of the input followed by a decoder network which may(or not) share encoder weights to reconstruct the input image
- So as the network tries to find a latent feature representation with the network output, the image itself, labels aren't required
- Got introduced into spatial transformer networks and action classification from videos using 3D convolutions and recurrent networks from part of this CS231N lecture https://www.youtube.com/watch?v=ekyBklxwQMU
- Learnt about instance segmentation and image captioning using attention
- Learnt about semantic segmentation and different methods involved
- Looked at different commonly used image datasets
- Looked at how different deep learning libraries work.
- Got introduced to image processing techniques like camera calibration, distortion correction
- Worked on retail analysis project as part of Bachelor's project
- Started working on a project to predict the next character using LSTM in Pytorch
- Learnt about different techniques to speedup convolutions like transforming each part of the image on which filters act to columns for using matrix multiplication, using FFT for larger filter size and using algorithms that speed up computation by using special values for different filters similar to how Strassen's method for matrix multiplication works in less than O(n^3) by cleverly choosing combination of submatrixes
- Learnt about different techniques to use in practice when CNN's are involved like - data augmentation, transfer learning, the advantage of using stacks of smaller filters vs large filters from the first part of this CS231n lecture https://lnkd.in/f2jkRpx
- Learnt about Activity Detection from Video using CNN and LSTM from this Deep Learnig for Visual Computing course from IITKGP https://lnkd.in/fkPfEdk
- Learnt about working on video data and Spatio-temporal deep learning for video analysis from this Deep Learning for Visual Computing course from IITKGP https://lnkd.in/fkPfEdk
- Learnt about using LSTM in Pytorch as preparation for Image Captioning project
- Working on retail analysis project as part of Bachelor's project
- Working on retail analysis project as part of Bachelor's project
- Working on retail analysis project as part of Bachelor's project
- Worked on retail analysis project as part of Bachelor's project
- Worked on retail analysis project as part of Bachelor's project
- Worked on retail analysis project as part of Bachelor's project
- Checked on LSTM's and Image captioning from the second part of this CS231N lecture https://www.youtube.com/watch?v=yCC09vCHzF8&t=1878s
- Working on garbage classification using Pytorch
- Got introduced to accelerating PyTorch computation in CPU from Intel's "Getting Started with PyTorch with Optimizations for Intel® Architecture" webinar
- Discussed retail analytics using computer vision project with mentor
- Tried out pre-trained pose estimation model
- Visualized trained model filters and output of images through the different filters for Fashion MNIST
- Classified and visualized Fashion MNIST
- Trying out running OpenPose model
- Learnt about sequence2sequence models using attention from CVND
- advantage of attention over normal seq2seq
- multiplicative and additive attention
- applications in computer vision and nlp
- Learnt about different hyperparameters for a neural network and some heuristics for setting these values
- learning rate, batch size and iterations
- no.of layers, choice between RNN/LSTM/GRU
- Continue learning about LSTM networks from CVND
- Learnt about the basics of LSTM from CVND
- RNN fails for networks over 8-10 timesteps due to VANISHING GRADIENTS problem
- Even though RNNs suffer from EXPLODING GRADIENTS(gradients uncontrollably increasing), gradient clipping can be done. Gradient clipping involves checking the gradient at each timestep to ensure it's value to be less than a threshold and if not normalizing it
- LSTMs are a workaround for the vanishing gradient problem in RNNs and can support networks of over 1000 timesteps
- Instead of weighted addition of input and previous state in RNN cell to produce the new state, LSTM cells use a combination of sigmoid, hyperbolic tangent, multiplication and addition operations and still is completely differentiable so that we can backpropagate through them
- Sigmoid allows differentiating b/w info that has to be passed to next timestep/to be retained

- Learnt about RNNs from RNN lesson in CVND
- folded and unfolded representation of RNN
- updating weights using Back-Propogation Through Time(BPTT)
- Learning about RNN's from CVND lesson on RNN
- Got an introduction to one-shot learning, siamese networks and triplet loss used in siamese networks from this blog
- Trying to setup pose estimation model
- Learnt about RNNs from part of this CS231n lecture
- RNNs can be used for applications where we need to work on sequential input/output
- Some applications are image captioning, sentiment classification, machine translation and frame-wise video classification
- At each time step, the predictions are affected by the previous time steps
- Data is processed in chunks due to memory reasons like batch size for images
- The same function(dependent on the weights) is used for one round of processing over a batch of data
- Got an introduction to DeepDream, Neural Style Transfer and Adversarial examples on CNNs from this CS231N lecture
- Looked upon visualization techniques for what CNN's learning or what features of the image are different layers of a CNN focusing on from part of this CS231N lecture
- Performed garbage classification
- Used a 3 layer CNN and got accuracy of 75.3% on training for 50epochs
- Used pretrained VGG16 and fine-tuned the FC layer to get 84% accuracy by training for just 2 epochs
- Dataset: https://lnkd.in/fQWSASM
- YOLO
- YOLO is a realtime object detection method as it doesn't generate region proposals
- Instead of predicting classes and bounding box separately like in case of R-CNN models YOLO predicts a single vector of class probabilities and bounding box coordinates
- YOLO divides images into grids of constant size and predicts output vectors for anchor boxes in each grid
- Completed Advanced CNN Architectures section of CV nanodegree
- Faster R-CNN increases performance over Fast R-CNN by using an inhouse(within the CNN) Region Proposal Network for predicting Region of Interests(ROI) inplace of selective search used in Fast R-CNN
- Models like YOLO and SSD increase performance by not using region proposals at all
- See my notes here
- CVND(Extracurricular Section - C++ Programming) - Translated naive robot localization implementation in Python to C++
- The position of the robot is estimated by sensing its environment
- Sensing increases the confidence of position estimate
- Movement increases uncertainty in position estimation
Lost my 31 day streak of learning computer vision 😞
Guess what, I get to start again on Day 1 😎
- Revisited topics on object localization and detection. See my notes here
- Started working on Garbage classification project. Researched on available datasets and found one here
- Working on facial keypoint detection project
- Working on facial keypoint detection project
- Completed Awwvision: Cloud Vision API from a Kubernetes Cluster lab on Qwiklabs
- Completed Tensorflow for Poets lab Qwiklabs
- Learnt about feature visualization
- It is possible to make some sense of what patterns the CNN is picking on by inspecting the filters learnt
- While for the first conv layer simply displaying the filters would do, for the subsequent layers we have to check the activations generated on passing images through the filters
- Completed Classify Images of Clouds in the Cloud with AutoML Vision lab on Qwiklabs
- Learnt about detection in images
- R-CNN is slower as for each region proposal it had to run a forward pass of CNN
- Fast R-CNN extracts region of interests from feature maps produced by conv layer and hence requiring a single CNN pass. Here, the bottleneck is finding the region of interests using an external method
- Faster R-CNN uses a region proposal network as part of the CNN architecture and hence speeds up the process as both region proposals and classification are incorporated into a single network
- While R-CNN methods took detection as a classification problem(classifying each region proposal into different classes), YOLO approaches detection as a regression problem
- YOLO works on the image by splitting it into grids of particular size. Then, make predictions for a predefined no.of bounding boxes inside the grid. The output will be the bounding box coordinates, confidence score of presence of an object in the bbox and class scores for all possible class of objects
- One disadvantage is that as we are limiting the no.of bbox'es that are to be evaluated for object presence in each grid, if there are more objects in the grid than the available bboxes, classification won't occur
- YOLO does real-time detection but with lesser mean average precision(average of precisions across all classes) than Faster R-CNN
- Learnt about localization in images
- Involves finding the location of a single object in the image
- Localization can be treated as regressing out bounding box data
- Can swap out fc layers of CNNs trained for classification to train new ones on a regression loss(like L2 loss) instead of softmax incase of classification
- Learnt about math behind PCA
- Two methods: diagonalizing Covariance matrix of inputs or by SVD
- Is a non-parametric method and hence doesn't take into account properties of data distribution
- Working on Facial keypoint detection project
- Attended webinar on Intro to Neural Networks by Pranjal Chaubey
- Working on the Facial Keypoint Detection project
- Tried around with different learning rate and added dropout layer
- Ran for 10 epochs but the loss isn't varying much, might have to try a more complex model
- Started training model for Facial Detection Keypoint project
- There are a total of 3462 images
- There are 2 conv layers and 2 fully connected layers
- Used ReLU activation on output of conv layer and followed by max pooling
- Trained for 1 epoch using Mean Square Error as loss and SGD optimiser with learning rate 0.01
- Loss is oscillating b/w 0.3-0.4
- Global average pooling returns a single value which is average of all values in a feature map(a bit harsh!)
- Dropout layer remove nodes with a certain probability on each iteration to avoid certain nodes getting trained more!
- Three important types of features(for an image) are edges, corners and blobs. Corners as they can uniquely identify certain regions can be more helpful
- Dilation thickens brighter areas of images by adding pixels to the boundaries of objects while erosion thins the brighter areas by removing pixels from object boundaries
- Learnt about different layers in a CNN
- Convolutional Layer: extracts different features from the image like color, edges etc
using convolutional filters(or kernels). Output of convolving filters through the image are
passed through an activation function
- Pooling Layer: used to reduce the spatial dimensionality of the feature maps. Helps in reducing
the no.of parameters as well as to generalize by taking a representative from each region
- Fully connected layers: normal neural network layer and helps in producing classification scores for different classes
of objects involved
- Visualized output of convolving using different filters and passing them via ReLU activation



- Learnt about carrying out object detection on occlusion
- The pre-saved specifications of an object can be utilized to know if the object is occluded
- Two cases of occlusion can happen - either a single object will be detected twice
when its middle part is not visible due to occlusion or shorter bounding box for the object
- Color of detected objects can be used to merge objects occluded in the former manner while
increasing the bounding box in the suitable direction to match the original object size
is to be done for the latter
- These methods only works under the assumption that objects are all of varying colors
- Took a pass through the OpenPose paper
- Employs a bottom approach for finding poses and hence can achieve realtime performance
irrespective of the number of people in the image
- Part confidence maps denote the probability of each image pixel being part of a particular body part
- Part Affine Fields denote relationship between different joints
- Utilizes both these to greedly map the found joints to each person
- Learnt about active learning and how to get better accuracies for your model with lesser data
- Completed Lecture 2 of Matrix Methods in Data Analysis, Signal Processing, and Machine Learning
- Completed CS231N CNN lecture
- Continue working on Facial Keypoint Detection project
- Watched part of CS231n CNN lecture
- Played around with Facial Keypoint Detection project
- Learnt about Haar Cascades for object detection and used pretrained face-detector architecture to detect faces using OpenCV
- Utilizes many positive and negative labeled images to extract Haar features which detects different lines
and shapes
- In the next step of Haar Cascade, different regions of the image are searched for matching by a cascade of
the extracted Haar features( they are tried on succession ) removing searched part of the image
if the classification outcome is negative on that part for a feature effectively reducing the image space
to search for faces.

- Learnt about Algorithmic Bias
- Bias occurs when the training set isn't a good representative of the general population the model is
supposed to make predictions on.
- Bias that creeps into our models can be a huge problem the intensity of which varies by the use case.
- Use cases like probability of committing crime can cause problems if model is sensitive to different
face shapes and ethnic groups.
- Implemented a Real-time face detector for both images and video based on this article
- OpenCV has a built-in deep neural network module which has pretrained model for face detection.
- Completed AI programming for Robotics localization exercises
* Programmed basic localization
- Localisation primarily involves starting out with an INITIAL BELIEF of the robots surroundings(probability of its position)
- You sense objects in the environment to increase knowledge of the robots location
- When the robot moves, the location of the robot becomes more uncertain(assuming not exact motion)
- Started off with Project1: Facial Keypoint Detection
* Completed loading and visualizing data, overrided Pytorch Dataset class.
for taking in the dataset.
- __init__ : is run when the class is instantiated
- __call__ : required to call a class instance
- __len__ : to use the len() function
- __getitem__: to index the class instance
- Learnt some Python built-in library tricks
* get(), setdefault(), defaultdict(), Counter(), f-strings
- Dive into Deep Learning book - Introduction
* [Reinforcement Learning](https://www.d2l.ai/chapter_introduction/intro.html#reinforcement-learning)
- RL differs from supervised and unsupervised learning in the sense that the latter types of learning
doesn't affect/consider the environment the data was collected from
- RL as:
1. Markov Decision Process - when the environment in which learning occurs is fully observed
eg: Playing chess(environment fully observed), Self Driving Car(environment-part of roads only in the range of sensors are observed)
2. Contextual Bandit Problem - when your actions doesn't affect the subsequent state of the environment but you utilize info from the environment(context)
3. Multi-armed Bandit Problem - wherein you take actions and try to find out which actions maximise the reward but doesn't get any information from the environment.
- DSC HIT GCP challenge - Quest 2: Intro to ML - Image Processing
* Completed [APIs Explorer: Qwik Start](https://www.qwiklabs.com/focuses/2457?parent=catalog) hand-on lab
1.Learnt about Hough transform for circles
2.Started learning Dive into Deep Learning book - Introduction
3.Completed WorldQuant University OOPS mini-project - coded k-means from scratch
- Learnt about Hough transform and used OpenCV to detect edges using Hough Transform

- Discussed computer vision and tips to make good progress in the nanodegree in the first Computer Vision weekly meetup

- Completed Baseline: Data, ML, AI Qwiklabs quest as part of GCP #gcpchallenge

- Watched MIT Self Driving Car State of the Art lecture
1. CVND:
- Learnt Canny edge detection and techniques involved: non-max suppression(thinning) and hysteresis thresholding(edge completion)


Digged deep in to fourier transforms and how they work? Seems like there's a lot of applications to it. No wonder why Professor Gilbert Strang said that FFT is the most important numerical algorithm of our lifetime. There's still some things about it I don't really understand. But that's okay there's 2mrw.
1. CVND:
- Learnt about low pass filters. Used OpenCV GaussianBlur function to blur brain image for reducing noise. Compared edge detection(sobel filter) on the blurred image and original image

- Used fourier transform to visualize frequency spectrum of images and their filtered version



1. CVND:
- Using Fourier transforms in Numpy to find frequency distribution of images ie, the variation of intensity in images. Fourier transform TRANSFORMS images in the x-y spatial space to the frequency space

- High pass filters and finding edges of images using Sobel operator in OpenCV


I do herby solemnly ...

1. CVND:
-
Change image background by basic image processing techniques using OpenCV

-
Day/Night image classifier on 200 images from the AMOS(Archive of Many Outdoor Scenes) dataset with an accuracy of 0.9375 by only manual feature extraction making use of HSV color-space


