Dbt stands for "data build tool." It's a really handy tool for people who work with data. Imagine you have a big pile of messy data - dbt helps you clean it up and make it useful.
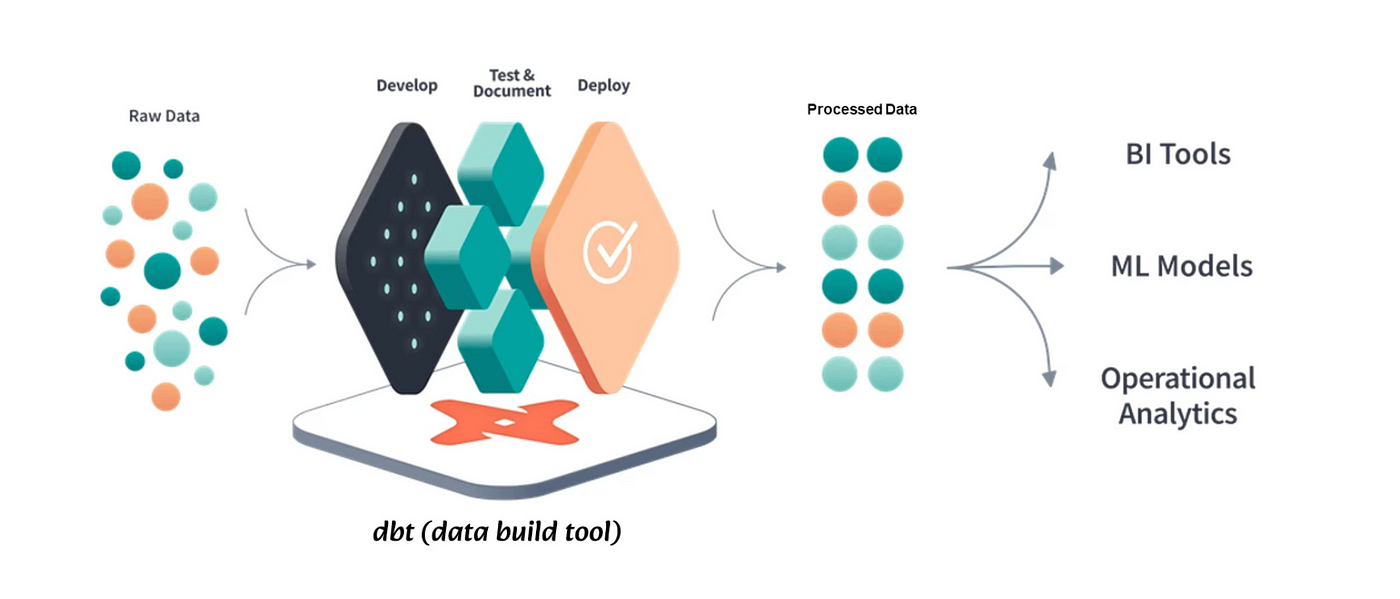
Here's how it works: 🤓
- Cleaning Data: First, you need to make sure your data is tidy. Dbt helps you do this by letting you write code to clean and organize your data. It's like tidying up your room before you start playing.
- Building Models: Once your data is clean, you can start building models. Models are like templates that help you understand your data better. Dbt lets you create these models easily, so you can see patterns and trends in your data.
- Testing: Dbt also helps you make sure your data is accurate. It lets you set up tests to check if your data is behaving the way it should. It's like having a buddy double-check your work to make sure you didn't miss anything.
- Documenting: It's important to keep track of what you're doing with your data. Dbt helps you document everything you're doing, so if someone else needs to look at your work later, they can understand what you've done.
- Collaborating: Dbt makes it easy for teams to work together on data projects. You can share your code with others, collaborate on building models, and make sure everyone is on the same page.
I was working on a large dataset stored in my data warehouse, particularly in BigQuery. I wanted to test dbt by applying it to that dataset, so I simply connected to this repo(Improved DX when tracking changes, especially beneficial for CI/CD configs). I wrote some models and macros to test my data and play around. So what are models and macros?
A data model is an organized design of how the data of entities in a database are related to each other. A dbt model can be thought of as a blueprint of a table or view that represents entities in a database. It is written using SQL and Jinja. Dependencies and transformations are typically written here.
Macros are like shortcuts or reusable pieces of code in dbt. They help you avoid repeating the same code over and over again. For instance, if you often need to calculate average sales per customer, you can create a macro for that calculation. Then, you can use that macro wherever you need to perform that calculation in your models.
{% macro avg_sales_per_customer() %}
SELECT
customer_id,
AVG(sales_amount) AS avg_sales_per_customer
FROM
sales
GROUP BY
customer_id
{% endmacro %}With this macro defined, you can now use it in your dbt models like this:
{{ avg_sales_per_customer() }}Note
When you compile your dbt project, dbt will replace the macro call {{ avg_sales_per_customer() }} with the SQL code defined in the macro. This saves you from having to write out the same calculation logic multiple times in your models, making your code cleaner and easier to maintain.
Packages in dbt are similar to libraries in other programming languages. Packages contain pre-built models, macros, and other resources that you can use in your dbt projects. They save you time by providing ready-made solutions for common data analysis tasks. For instance, there are packages available for financial analysis, marketing analytics, and more. You can simply install a package and start using its resources in your project.
Testing in dbt allows you to verify the quality and integrity of your data models and macros. Tests are defined at the column level and can ensure that your data meets certain expectations or constraints.
There are various types of tests you can define in dbt:
- not_null: Verifies that a column does not contain null values.
- unique: Checks if all values in a column are unique.
- accepted_values: Ensures that values in a column are among the accepted values specified.
- relationship: Validates relationships between columns in different tables.
- expression: Allows you to define custom SQL expressions to test column values.
Tests are defined in your dbt models or macros within the tests field of each column. Here's the basic syntax:
models:
- name: my_model
columns:
- name: my_column
tests:
- test_nameLet's say you want to ensure that a column named amount in your data model sales doesn't contain null values. You can define a not_null test for it like this:
models:
- name: sales
columns:
- name: amount
tests:
- not_nullAfter defining your tests, you can run them using the dbt test command. This command runs all tests defined in your dbt project.
Once tests are run, dbt generates a test report that shows which tests passed and which failed. You can view this report to identify any data quality issues that need attention.
Documentation in dbt is essential for maintaining clarity and understanding of your data models and macros. It helps users to comprehend the purpose, structure, and usage of your dbt artifacts.
Documentation serves as a guide for users to navigate through your dbt project. It provides context, explanations, and examples to help users understand how to interact with your data models and macros effectively.
There are various types of documentation you can include in your dbt project:
- Model Documentation: Describes the purpose, structure, and logic of each data model in your project.
- Macro Documentation: Provides explanations and usage examples for macros defined in your project.
- Seed Documentation: Describes the source and structure of seed data used in your project.
- Test Documentation: Explains the purpose and criteria of tests defined for data quality assurance.
Documentation is typically written in YAML format within the relevant section of your dbt project. Here's an example of documenting a data model:
models:
- name: my_model
description: "This model calculates the total sales amount per customer."
columns:
- name: customer_id
description: "The unique identifier of the customer."
- name: total_sales
description: "The total amount of sales made by the customer."- Keep documentation concise, clear, and informative.
- Include examples and usage guidelines to help users understand how to interact with your dbt artifacts.
- Update documentation regularly to reflect changes in your project.
Deployment in dbt involves automating the process of building and deploying data models, macros, and other artifacts to your analytics environment. This ensures that changes made to your dbt project are efficiently propagated to production, enabling timely insights and decision-making.
One common approach to deployment is utilizing GitHub Actions, a feature of GitHub that allows you to automate workflows. By adding a GitHub Action to your repository, you can trigger a build pipeline to execute dbt commands whenever new commits are pushed to the repository. This automates the deployment process, ensuring that changes are applied promptly and consistently.
- Efficiency: Automation reduces manual intervention, streamlining the deployment process and minimizing the risk of human error.
- Consistency: Automated deployments ensure that changes are applied uniformly across environments, maintaining consistency and reliability.
- Timeliness: By triggering deployments automatically upon new commits, you ensure that updates are applied promptly, enabling timely insights and decision-making.
Integrating dbt deployment into a CI/CD pipeline enables continuous integration and deployment of data models. This ensures that changes are automatically tested and deployed, facilitating agile development and rapid iteration.
So let's see what I've learned about dbt from my point of view:
In my data analytics journey, dbt has been a game-changer. It's like my trusty toolkit for transforming and analyzing data effortlessly.
Testing ensures my data is reliable. It's like having a watchdog that checks everything is in order, making sure my analyses are accurate and trustworthy.
Documentation is my guidebook. It helps me understand what each piece of my project does and how to use it. It's like having clear directions to follow, making collaboration a breeze.
Deployment is the magic that brings my work to life. It's like pressing a button and watching my insights go live, ensuring everyone gets the latest and greatest data.
Together, dbt with testing, documentation, and deployment work like a team to make my data analytics journey smooth. They help me understand my data better, make sure it's good quality, and share my findings easily. With these tools in place, I can analyze data with confidence and make informed decisions that benefit my projects.
Important
dbt is an incredibly useful tool for working with data. It simplifies the process of cleaning, organizing, and analyzing data, making it accessible to both technical and non-technical users. With dbt, you can efficiently manage your data projects, collaborate with team members, and ensure the accuracy and reliability of your analyses.