- 부스트캠프 AI Tech - Level2. Object Detection Competition

목표 : 주어진 사진에서 10종류의 재활용 쓰레기를 분류하여 탐지하는 모델 제작
데이터 셋 : 쓰레기 객체가 담긴 1024 x 1024 크기의 image train data 4883장, test data 4871장
프로젝트 개발 환경 : Ubuntu 18.04.5 LTS , Intel(R) Xeon(R) Gold 5120 CPU @ 2.20GHz , Ram 90GB , Tesla V100 32GB
V.I.P ==
✨Visionary Innovative People✨
 김서인 |
 문상인 |
 박재훈 |
 이강민 |
 전지수 |
| 팀원 | 역할 |
|---|---|
| 김서인 | RabbitMQ 도입, data augmentation 구현 및 실험, 모델 성능 향상 실험 진행, earlystop setting |
| 문상인 | PM(Project Manager), MMDetection & YOLO 데이터셋 구축, 자동 학습 queue 구현 및 실험 진행 |
| 박재훈 | GPU 스케줄러 개발, MMDetection Baseline 구축, loss & optimizer 실험, 앙상블 코드 구현 및 실험 |
| 이강민 | MMDetection 베이스라인 구축, YOLO 모델 개발 |
| 전지수 | 데이터 EDA, Wandb setting, pseudo_labeling 진행, inference 결과 시각화 및 분석 |
- Repository 는 다음과 같은 구조로 구성되어 있습니다.
├── .github
├── EDA
├── codebook
├── images
├── mmdetection
├── rabbitmq
├── yolov8
├── .gitignore
└── README.md
- mmdetection :
./mmdetection/requirements.txt - yolo :
./yolov8/requirements.txt
pip install -r mmdetection/requirements.txt
python mmdetection/tools/train.py mmdetection/configs/custom/base_config.py
python mmdetection/inference.py -cfg_folder {base_config folder path}
pip install -r yolov8/requirements.txt
python yolov8/train.py --train_cfg yolov8/V1_yolov8l_pt_img1024.yaml --weight yolov8/yolov8l.pt
python yolov8/inference.py --model {best.pt path}
| 분류 | 내용 |
|---|---|
| Dataset | EDA - 일반 쓰레기를 잡기 어려움 - 쓰레기봉투 안에 쓰레기들의 존재 Dataset 구성 - 이미지 당 30, 35, 40개 이상의 박스를 가지는 이미지를 제거한 데이터 셋 align 실험 |
| MMDetection | 여러 구조에 대한 benchmarking 학습을 진행 - 2 stage: Faster R-CNN, Cascade R-CNN, Mask R-CNN, Grid R-CNN - 1 stage: RetinaNet, FreeAnchor, FCOS, Fovea, CornerNet, ATSS |
| Data augmentation | Albumentation 조합 선택 - RandomSizedBBoxSafeCrop - OneOf(VerticalFlip, HorizontalFlip) - ToGray - GaussNoise - OneOf(Blur, GaussianBlur, MedianBlur, MotionBlur) - CLAHE - RandomBrightnessContrast - HueSaturationValue |
| Optimizer | - Stochastic Gradient Descent(SGD)와 AdamW의 비교 |
| Focal Loss | - Focal Loss와 Cross Entropy Loss와의 비교 |
| YOLOv8 | - Input image size 업스케일링 - Localization loss function 변경 - Data augmentation 변경 - Model size 교체 - 추가 학습 진행 |
| Ensemble | - TTA (Test Time Augmentation) - NMS (Non-Maximum Suppression) - WBF (Weighted Box Fusion) |
| Pseudo-labeling | - 리더보드 기준 가장 좋았던 성능의 inference 결과에 포함되어 있는 bbox의 annotation 정보를 다시 train dataset으로 가져와서 학습 |
- GitFlow를 따라 Github를 활용했다. 개발 과정에서 다음과 같은 절차를 따라 진행했다.
- 이슈 생성
- Feature branch 생성
- Pull Request
- 코드 리뷰 및 merge
- commit message는 ‘feat: ~ ’ 형식을 사용하였고, issue와 관련된 commit인 경우 issue 번호를 commit message의 foot에 추가해주었다.
- MMDetWandbHook을 통해 실험 결과를 wandb 상에 validation mAP, train loss, train acc 등을 로깅하였다.
-
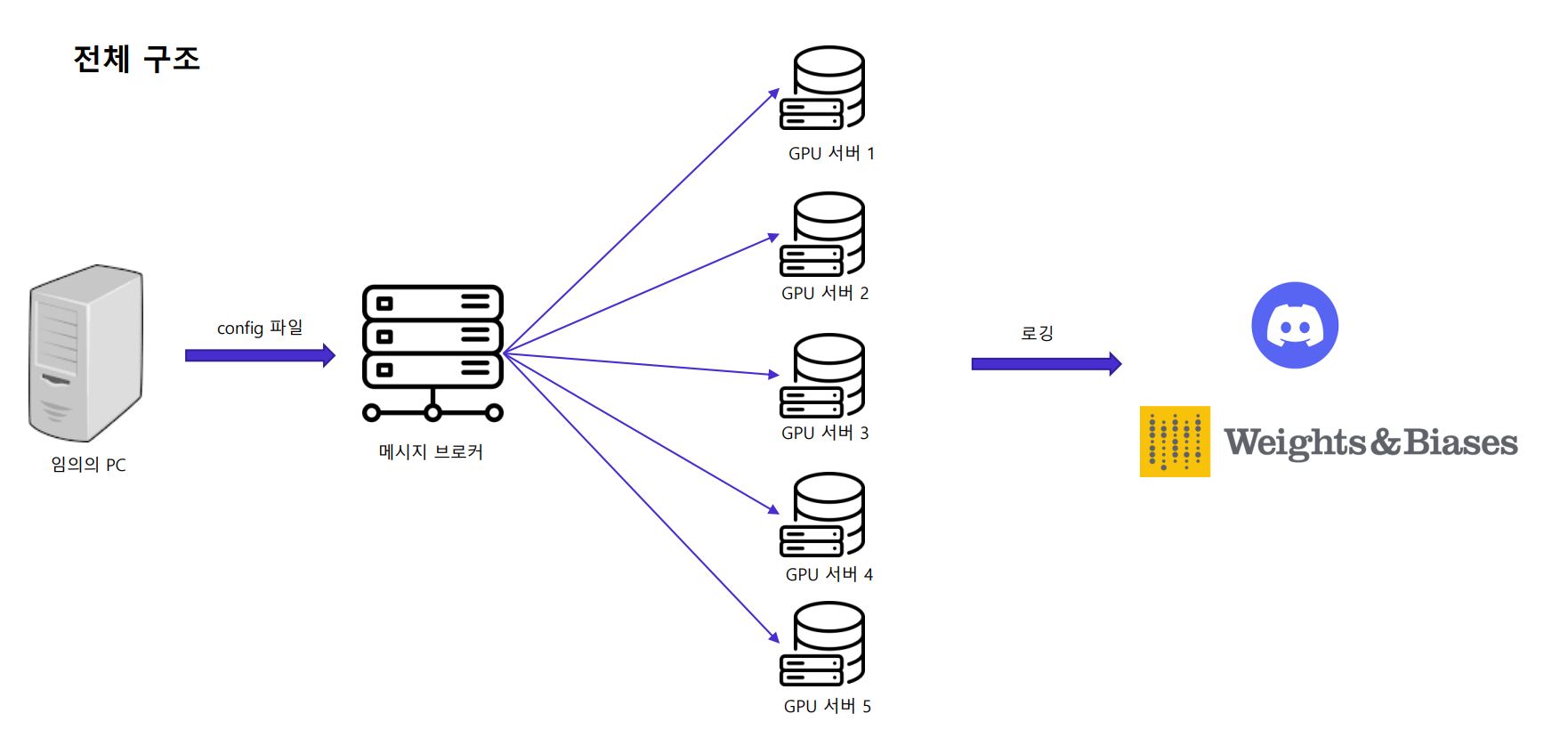
팀에서 총 5대의 GPU 서버를 운용하고 있는 상황에서, 전체 GPU 리소스의 평균 가동률을 극대화하고 실험 속도를 높이기 위해서 GPU 스케줄러에 대한 요구가 생겼다. 따라서 메세지 큐인 RabbitMQ를 이용해 GPU 스케줄러를 구현하였으며, 본 프로젝트에서는 부분적으로 테스트해보며 사용성과 버그를 찾아 보완하였다. 구조는 아래 그림과 같다.

최종 순위 13등
![]()
