Python topic detection module for SparkWiki. The module computes statistics, clustering and assigns topics to clusters of trending Wikipedia pages, extracted using the Anomaly Detection Algorithm. Topic classification model is available here. The module works with all language editions of Wikipedia.
- Compute degree, betweeness centrality and modularity for clustering the graph by events
- Match wikipages with their Qids (unique Wikipedia ID)
- Match wikipages with their corresponding topics
- Match wikipages with their pageviews
- Save a new corresponding graph with these attributes
- Give a graphical topics partition of each cluster
- numpy, matplotlib, pandas, networkx, requests
- community
$ pip install python-louvain
Get the graph from SparkWiki projet using PeakFinder module.
Put the graph file into a local folder Python/Results/<Language>/<Language>_<date_start>_<date_end>.
Language: EN, FR, RU, etc.
Date format: YYYYMMDD
Graph file name format: peaks_graph_<date_start>_<date_end>.gexf
Example: Python/Results/EN/EN_20200316_20200331/peaks_graph_20200316_20200331.gexf
To compute the whole pipeline from a graph with the name and folder path in the correct format (cf. Pre-requisites), run the following command in the terminal:
$ python main.py EN 20200316 20200331The pipeline can also be computed partially. To do that, specify the optional parameter from 1 to 6 to run only a part of the pipeline corresponding to the features described in the table below:
$ python main.py EN 20200316 20200331 1| Parameter value | Description |
|---|---|
0 |
Default |
1 |
Compute degree, betweeness centrality and modularity |
2 |
Match Qids |
3 |
Match topics |
4 |
Match pageviews |
5 |
Save graph attributes |
6 |
Give topics repartition per cluster |
Alternatively, one can run the Topics_exctraction.ipynb notebook. The notebook also includes the code generating visualisations.
Every stage of the pipeline generates and saves a .csv file with corresponding results.
The final step creates /Figures folder with figures of the topics partition per cluster.
Also, the final stage creates a graph file with all the computed attributes: filled_graph.gexf
In order to explore the detected topics, the graph can be visualized in Gephi. We used Circle Pack Layout with modularity class as a partitioning attribute.
Wikipedia graphs of trending pages are available in Python/Result for 16/08/2018 to 31/12/2018 and 17/12/2019 to 15/04/2020 periods for EN, FR, RU languages.
The notebook Topic_comparison.ipynb gives a topic comparaison between EN, FR, RU languages. The figures are saved in Python/Comparison_figures.
Gephi files representing the graphs are also located in /Gephi folder.
Here you can see a visual example. The animation shows trending topics for the last four months of 2018. The graph visualization illustrates the graph computed for the period 1-15 March 2020.
Topics comparaison
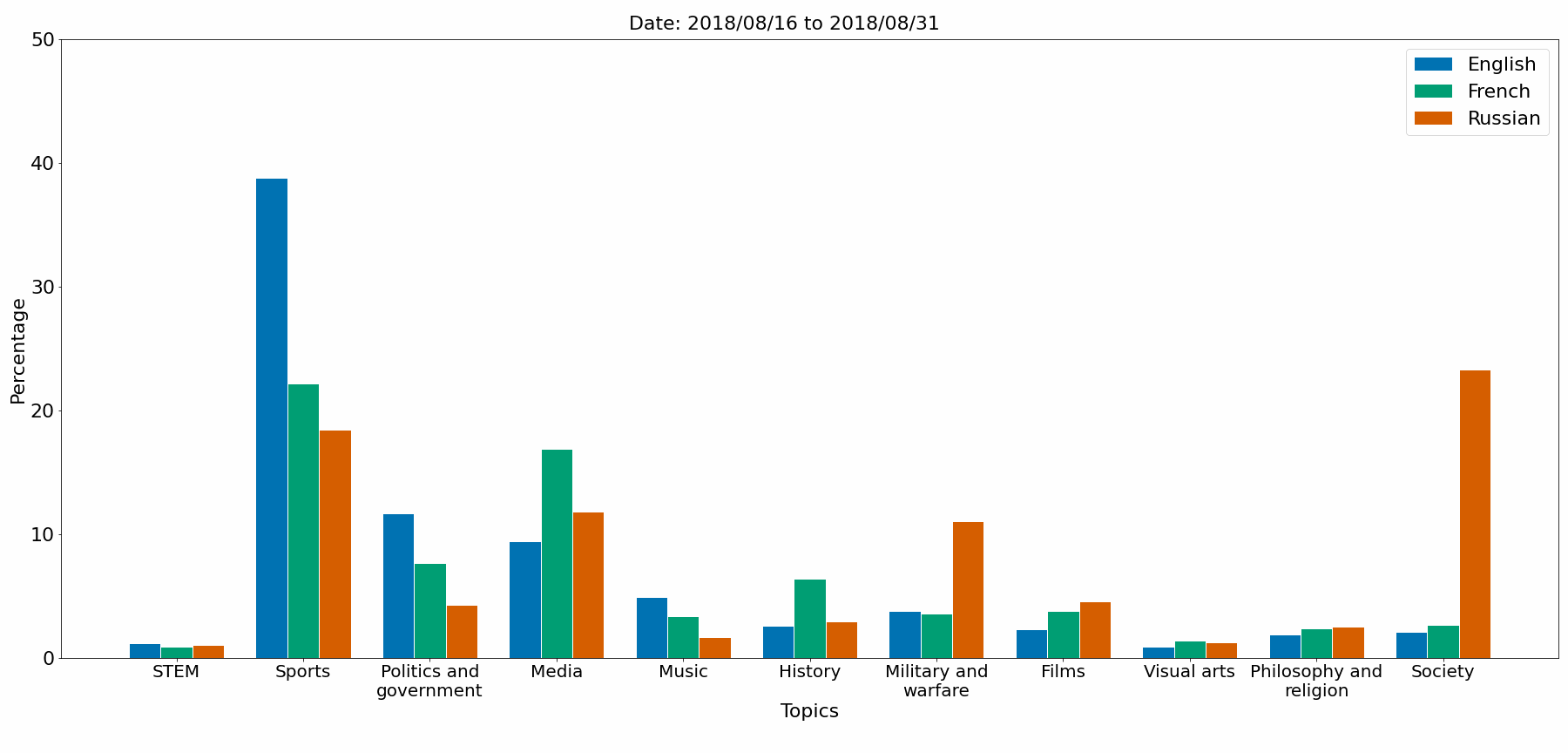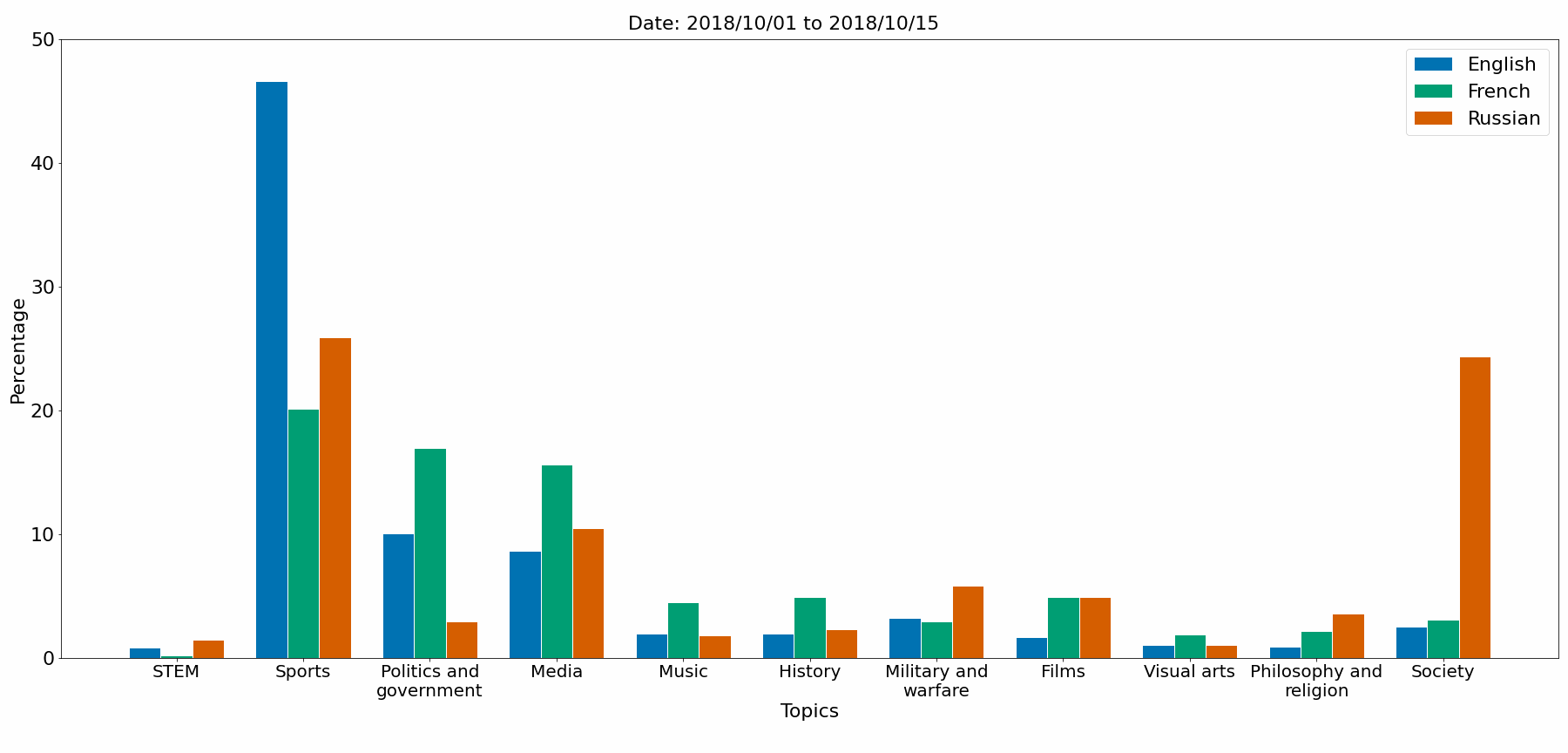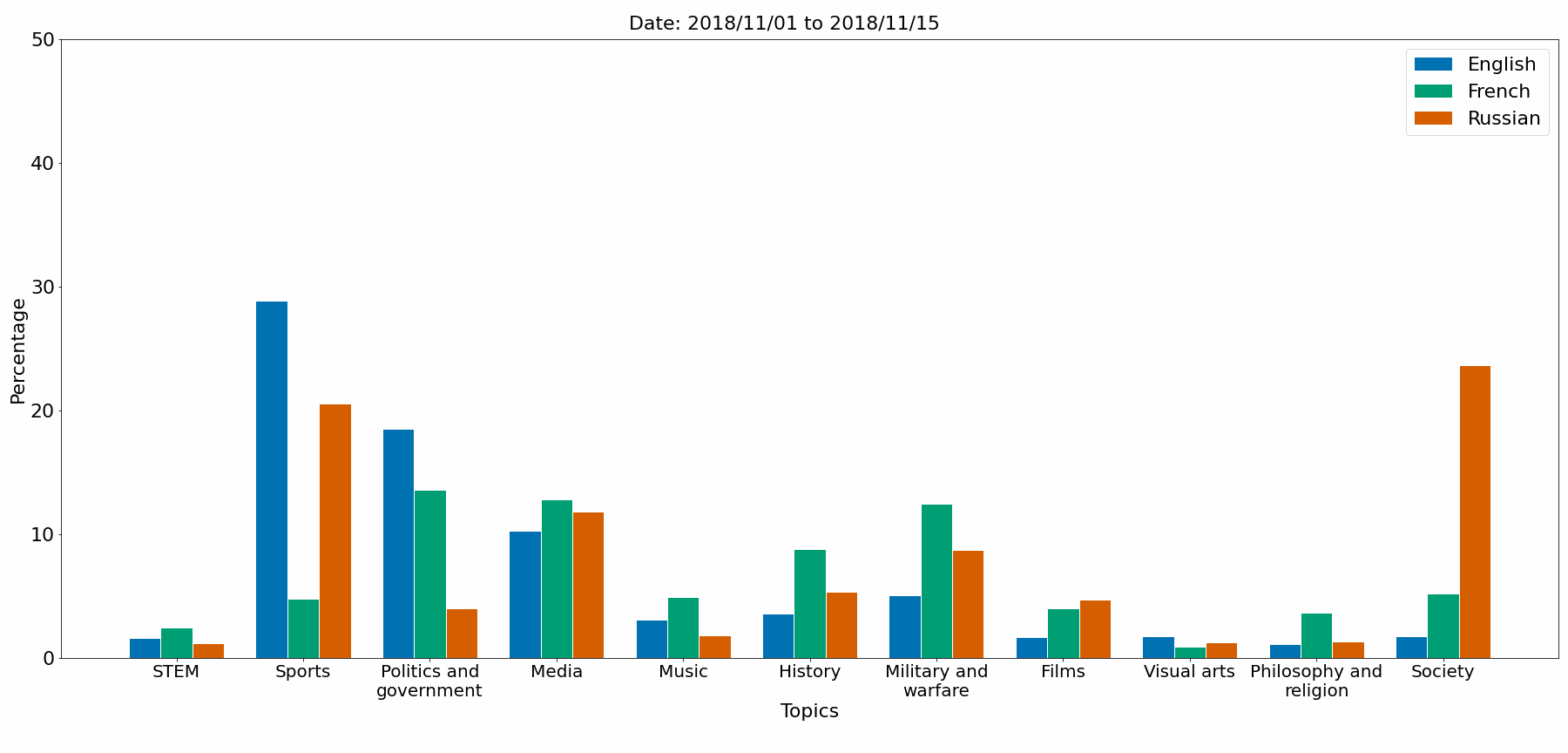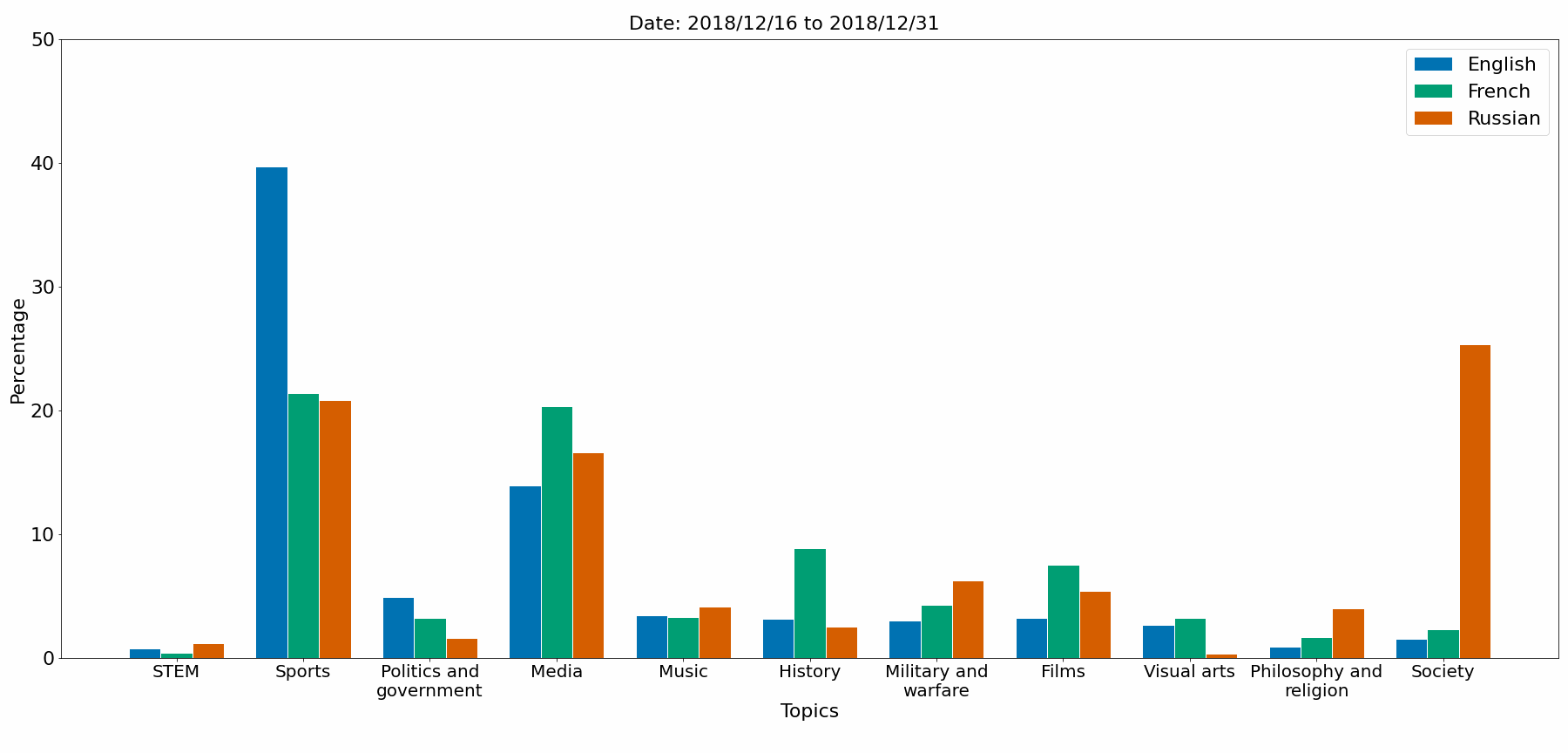 Gephi graph (EN_20200301_20200315)
Gephi graph (EN_20200301_20200315)

Wikipedia trending topics detection: SparkWiki
Clustering of trending pages: Community detection
Topic classification model: Language-Agnostic Topic Classification