LLF Bench is a benchmark that provides a diverse collection of interactive learning problems where the agent gets language feedback instead of rewards (as in RL) or action feedback (as in imitation learning). The associated website and paper are:
Website: https://microsoft.github.io/LLF-Bench/
Paper: https://arxiv.org/abs/2312.06853
- Overview
- Design principles
- Installation
- Special Instructions for running Alfworld
- Special Instructions for running Metaworld
- Examples
- Testing
- Baseline and skyline results
- Contributing
- Trademarks
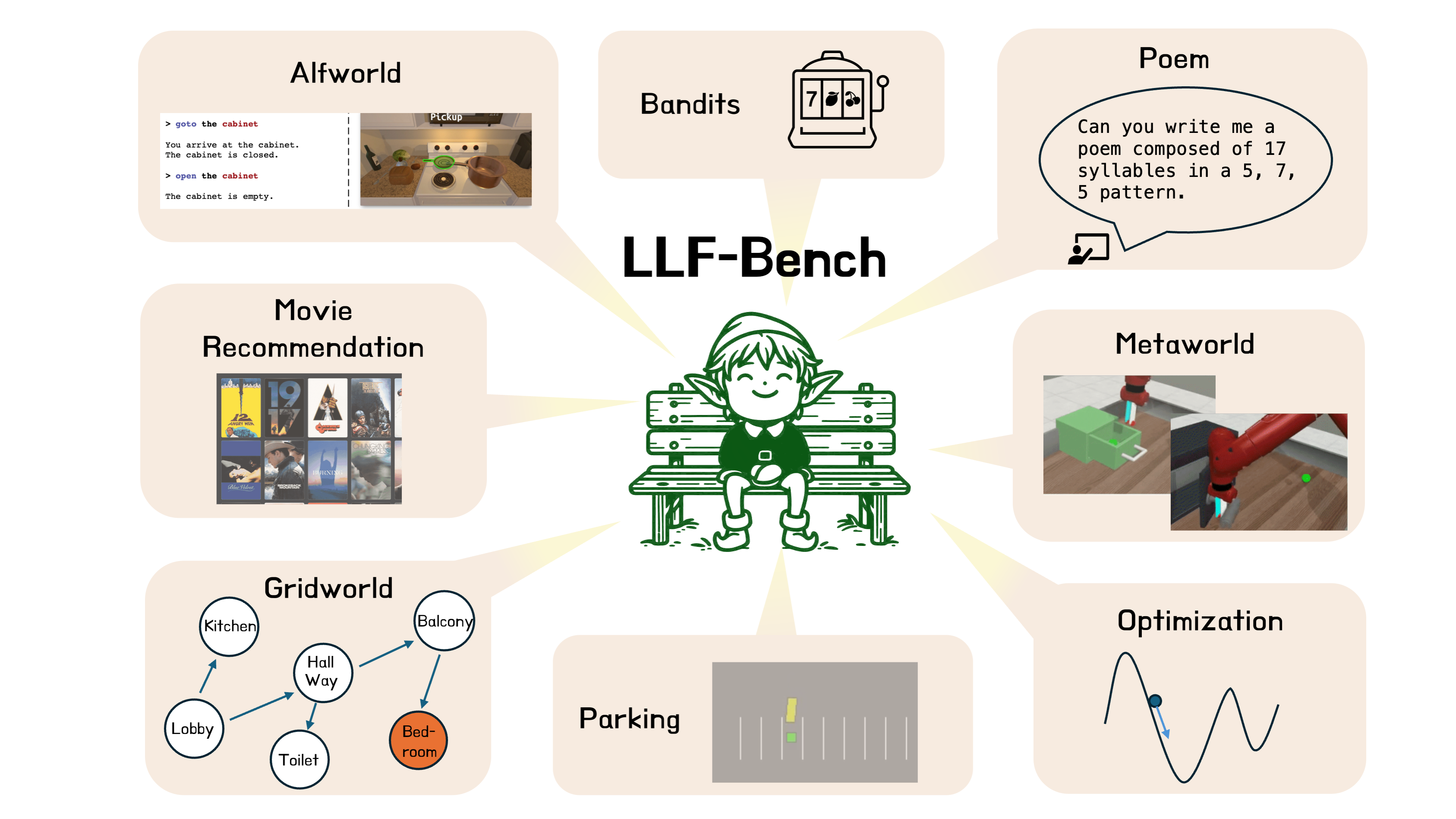
Each benchmark environment here follows the gym api.
observation_dict, info = env.reset()
observation_dict, reward, terminated, truncated, info = env.step(action)
observation_dict contains three fields:
- 'observation': a (partial) observation of the environment's state
- 'instruction': a natural language description of the task, including the objective and information about the action space, etc.
- 'feedback': a natural language feedback to help the agent to better learn to solve the task.
When a field is missing, its value is represented as None. For example, 'instruction' is typically only given by
resetwhereas 'feedback' is only given bystep.
reward is intended for evaluating an agent's performance. It should not be passed to the learning agent.
terminated indicates whether a task has been solved (i.e., the goal has been reached) or not.
truncated indicates whether the maximal episode length has been reached.
info returns an additional info dict of the environment.
We design LLF-Bench as a benchmark to test the learning ability of interactive agents. We design each environment in LLF-Bench such that, from 'observation' and 'instruction' in observation_dict, it is sufficient (for a human) to tell when the task is indeed solved. Therefore, a policy that operates based purely on 'observation' and 'instruction' can solve these problems. However, we also design these environments such that 'observation' and 'instruction' are not sufficient for designing or efficiently learning the optimal policies. Each environment here is designed to have some ambiguities and latent characteristics in the dynamics, reward, or termination, so that the agent cannot infer the optimal policy just based on 'instruction'.
These features are designed to test an agent's learning ability, especially, the ability to learn from language feedback. Language feedback can be viewed as a generalization of reward feedback in reinforcement learning. It can not only provide information about reward/success, but it can also convey expressive feedback such as explanations and suggestions. The language feedback is implemented as the field 'feedback' in observation_dict, which is to help the agent to learn better.
Create conda env.
conda create -n LLF-Bench python=3.8 -y
conda activate LLF-Bench
Install the repo.
pip install -e .
or pip install -e .[#option1,#option2,etc.]
Some valid options:
metaworld: for using metaworld envs
alfworld: for using alfworld envs
For example, to use metaworld, install the repo by pip install -e .[metaworld].
Alfworld requires python3.9 so please use python3.9 when creating the conda environment. Activate the conda environment, clone the LLFbench repo and install it using
pip install -e .[alfworld]
When the first time you will run the alfworld environment, it will download additional files. You dont need to do any of this. Alfworld also uses a config.yaml file that changes the environment. We use the config yaml file provided here: llfbench/envs/alfworld/base_config.yaml. If you get some path errors, please ensure the source directory is referencing this file correctly. This is done in the code here.
You should use python3.8 and install the repo with metaworld by running pip install -e .[metaworld].
For metaworld option, it requires libGL, which can be installed by
sudo apt-get install ffmpeg libsm6 libxext6
For reco option, please follow the instruction here to register and get your own user key:
https://www.omdbapi.com/apikey.aspx
Then, you can set the environment variable OMDB_API_KEY to your key:
export OMDB_API_KEY=your_keyThis sample code creates an environment implemented in LLF-Bench, and creates an agent that interacts with it. The agent simply prints each observation to the console and takes console input as actions to be relayed to the environment.
import llfbench as gym
# Environments in the benchmark are registered following
# the naming convention of llf-*
env = gym.make('llf-gridworld-v0')
done = False
cumulative_reward = 0.0
# First observation is acquired by resetting the environment
observation, info = env.reset()
while not done:
# Observation is dict having 'observation', 'instruction', 'feedback'
# Here we print the observation and ask the user for an action
action = input( observation['observation'] + '\n' +
observation['instruction'] + '\n' +
observation['feedback'] + '\n' +
'Action: ' )
# Gridworld has a text action space, so TextWrapper is not needed
# to parse a valid action from the input string
observation, reward, terminated, truncated, info = env.step(action)
# reward is never revealed to the agent; only used for evaluation
cumulative_reward += reward
# terminated and truncated follow the same semantics as in Gymnasium
done = terminated or truncated
print(f'Episode reward: {cumulative_reward}')The tests folder in the repo contains a few helpful scripts for testing the functionality of LLF-Bench.
- test_agents.py: Creates a
UserAgentthat prints the 'observation' and 'feedback' produced by an LLF-Bench environment to the console, and reads user input from the console as an 'action'. - test_basic_agents.py: For a subset of LLF-Bench environments that support either a finite action space or admit a pre-built expert optimal policy, this script creates a
RandomActionAgentandExpertActionAgentto test supported LLF-Bench environments. - test_envs.py: Syntactically tests environments added to the LLF-Bench environment registry so as to be compatible with the expected semantics of LLF-Bench. This is a useful script to run on any new environments that are added or existing environments are customized in the benchmark.
Last updated: 05.13.2024

Performance of basic agents using different LLMs, where the agents receive all types feedback and append the observation and feedback history to their contexts after each step. These numbers can be viewed as "skyline" performance, since receiving all feedback types typically provides all information to solve the problem near-optimally.

Performance of basic agents using different LLMs, where th agents receive only reward, hindsight positive, and hindsight negative feedback and append the observation and feedback history to their contexts after each step. These numbers can be viewed as "baseline" performance.
Details: For GPT-3.5-Turbo and GPT-4, the statistics are computed over 10 episodes for all problem sets except Alfworld, for which, due to high problem instance variability, we used 50 episodes. For other language models, 50 episodes are used for all problem sets. For Metaworld, Alfworld, and Gridworld, the mean return is defined as the policy's success rate, which uniquely determines the standard error. Therefore, for the problems from these three problem sets, the st.e. is shown in gray.
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.