- [2.29] Update the main.py to fix bugs.
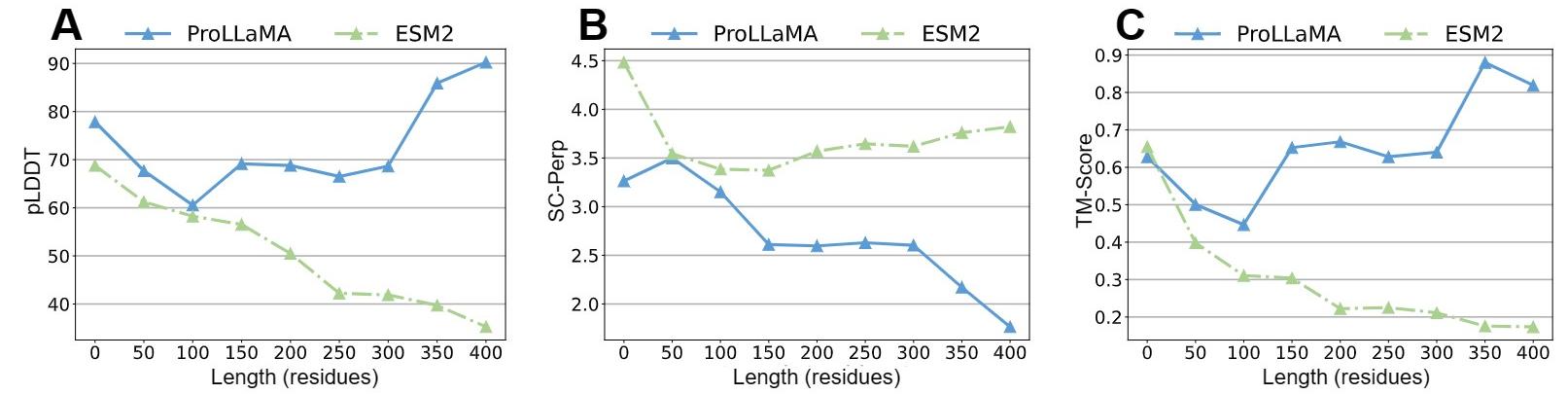
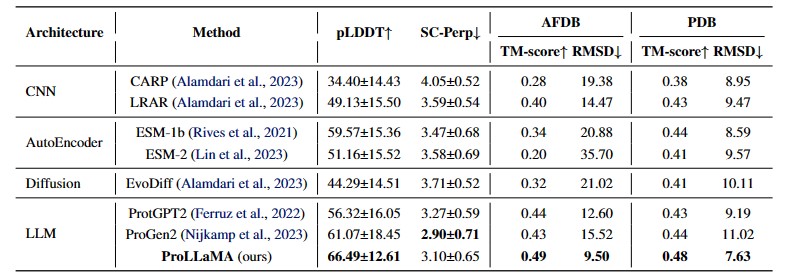
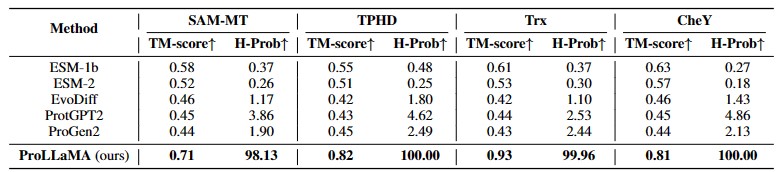
Large Language Models (LLMs), including GPT-x and LLaMA2, have achieved remarkable performance in multiple Natural Language Processing (NLP) tasks. Under the premise that protein sequences constitute the protein language, Protein Large Language Models (ProLLMs) trained on protein corpora excel at de novo protein sequence generation. However, as of now, unlike LLMs in NLP, no ProLLM is capable of multiple tasks in the Protein Language Processing (PLP) field. We introduce a training framework to transform any general LLM into a ProLLM capable of handling multiple PLP tasks. Specifically, our framework utilizes low-rank adaptation and employs a two-stage training approach, and it is distinguished by its universality, low overhead, and scalability. Through training under this framework, we propose the ProLLaMA model, the first known ProLLM to handle multiple PLP tasks simultaneously. Experiments show that ProLLaMA achieves state-of-the-art results in the unconditional protein sequence generation task. In the controllable protein sequence generation task, ProLLaMA can design novel proteins with desired functionalities. In the protein property prediction task, ProLLaMA achieves nearly 100% accuracy across many categories. The latter two tasks are beyond the reach of other ProLLMs

I also have other AI for Science projects that may interest you ✨.
TaxDiff: Taxonomic-Guided Diffusion Model for Protein Sequence Generation
Zongying Lin, Li Hao, Liuzhenghao Lv, Bin Lin, Junwu Zhang, Calvin Yu-Chian Chen, Li Yuan, Yonghong Tian

- Our ProLLaMA is the first model to our knowledge capable of simultaneously handling multiple PLP tasks.
- including generating proteins with specified functions based on the user's intent.
- We propose a training framework with scalability and efficiency that enables any general LLM to be trained as a proficient model for multiple tasks in Protein Language Processing.
- Experiments show that our ProLLaMA not only handles PLP tasks beyond the reach of existing ProLLMs but also achieves state-of-the-art results in the protein generation task where current ProLLMs are active.
-
Protein sequence generation
-
Controllable protein sequence generation (controlled by the given superfamily descriptions)
ProLLaMA is capable of generating desired proteins (Blue) with functions and structures similar to natural proteins (Yellow).

-
Protein property prediction






The training framework we propose is as follows:
- (A) Continual learning on protein language.
- (B) Instruction tuning on multi-tasks.
- (C) Expanding to more tasks by instruction tuning in the future.

As ProLLaMA's architecture is the same as LLaMA2, you can use ProLLaMA for inference like using LLaMA2.
Follow the steps below to use our ProLLaMA for inference.
- torch==2.0.1
- transformers==4.35.0
- cuda==11.7
git clone https://github.com/Lyu6PosHao/ProLLaMA.git
cd ProLLaMA
pip install -r requirements.txtDownload from HuggingFace
Just like using LLaMA2, three ways are provided here:
- Commandline
CUDA_VISIBLE_DEVICES=0 python main.py --model "GreatCaptainNemo/ProLLaMA" --interactive
#You can replace the model_path with your local path
#Make sure you use only one GPU for inference
#Use "python main.py -h" for more details- Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
##You can replace the model_path with your local path
tokenizer = AutoTokenizer.from_pretrained("GreatCaptainNemo/ProLLaMA", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("GreatCaptainNemo/ProLLaMA", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("GreatCaptainNemo/ProLLaMA")
print("####Enter 'exit' to exit.")
while True:
messages = []
user=str(input("Input:"))
if user.strip()=="exit":
break
messages.append({"role": "user", "content": user})
response = model.chat(tokenizer, messages)
print("Output:", response)git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
python ./src/cli_demo.py \
--model_name_or_path /path_to_your_model \
--template llama2The instructions which you input to the model should follow the following format:
[Generate by superfamily] Superfamily=<xxx>
or
[Determine superfamily] Seq=<yyy>
Here are some examples of the input:
[Generate by superfamily] Superfamily=<Ankyrin repeat-containing domain superfamily>
#You can also specify the first few amino acids of the protein sequence:
[Generate by superfamily] Superfamily=<Ankyrin repeat-containing domain superfamily> Seq=<MKRVL
[Determine superfamily] Seq=<MAPGGMPREFPSFVRTLPEADLGYPALRGWVLQGERGCVLYWEAVTEVALPEHCHAECWGVVVDGRMELMVDGYTRVYTRGDLYVVPPQARHRARVFPGFRGVEHLSDPDLLPVRKR>
See this on all the optional superfamilies.
(To Be Done) Quick usage of our training framework.
(To Be Done) The model of the first stage will also be available on HuggingFace soon.
@article{lv2024prollama,
title={ProLLaMA: A Protein Large Language Model for Multi-Task Protein Language Processing},
author={Lv, Liuzhenghao and Lin, Zongying and Li, Hao and Liu, Yuyang and Cui, Jiaxi and Chen, Calvin Yu-Chian and Yuan, Li and Tian, Yonghong},
journal={arXiv preprint arXiv:2402.16445},
year={2024}
}