Nvidia Tensorrt支持许多类型的网络层,并且不断地扩展支持新的网络层。但是,由于各种新算子的出现,TensorRT所支持的层不能满足模型的特定需求。在这种情况下,可以通过实现自定义新的网络层(通常称为Plugin)来扩展TensorRT。
目前TensorRT开源的官方plugins,参考GitHub: TensorRT plugins.
开发者可以通过Tensorrt的基类来实现自定义Plugin,下表总结了基类,不同的基类支持动态形状,不同类型/格式或网络的支持I/O。


-
pytorch: 定义了一个包含两个输入
x,y的Net,其中test_add操作则是自定义的算子操作。test_add函数实质上就是: input: a, b res = a + b + 2 output: res -
ONNX:导出ONNX模型后,其中红色包围框标识部分为
test_add -
Editing ONNX: 对ONNX进行编辑,将
test_add操作编辑为一个node -
Coding and Compiling TensorRT plugins:编写TensorRT plugin
testAdd并编译生成动态库 -
Running Edited ONNX : 在TensorRT运行Edited ONNX
step1 - step3就不展开,具体参考我的github源码:
我的环境如下:
- cuda12.1, cudnn8.9.0
- TensorRT-8.6.1.6
git clone -b main https://github.com/nvidia/TensorRT TensorRT
cd TensorRT
git submodule update --init --recursive
mkdir -p build && cd build
cmake .. -DTRT_LIB_DIR=path/to/TRT_LIBPATH -DTRT_OUT_DIR=path/to/out
make -j$(nproc)
先编译一下,验证编译环境是否有问题
首先在plugin文件夹下创建testAddPlugin,内容可以直接拷贝其他plugin下,将文件名替换为自定义的plugin名

其中
class TestAddPlugin:继承IPluginV2DynamicExt,用于plugin的具体实现class TestAddPluginCreator:继承BaseCreator, 是插件工厂类,用于根据需求创建该plugin

我们先剖析TestAddPluginCreator的实现


Plugin信息
static char const* const KTEST_ADD_PLUGIN_VERSION{"1"};
static char const* const KTEST_ADD_PLUGIN_NAME{"Test_Add_TRT"};
const char* TestAddPluginCreator::getPluginName() const noexcept
{
return KTEST_ADD_PLUGIN_NAME;
}
const char* TestAddPluginCreator::getPluginVersion() const noexcept
{
return KTEST_ADD_PLUGIN_VERSION;
}
const PluginFieldCollection* TestAddPluginCreator::getFieldNames() noexcept
{
return &mFC;
}成员变量
PluginFieldCollection TestAddPluginCreator::mFC{};
std::vector<PluginField> TestAddPluginCreator::mPluginAttributes;struct PluginFieldCollection
{
//! Number of PluginField entries.
int32_t nbFields;
//! Pointer to PluginField entries.
PluginField const* fields;
};
class PluginField
{
public:
AsciiChar const* name;
void const* data;
PluginFieldType type;
int32_t length;
PluginField(AsciiChar const* const name_ = nullptr, void const* const data_ = nullptr,
PluginFieldType const type_ = PluginFieldType::kUNKNOWN, int32_t const length_ = 0) noexcept
: name(name_)
, data(data_)
, type(type_)
, length(length_)
{
}
};PluginFieldCollection的作用是传递plugin参数相关的名称,类型和算子权重数据
但creator中的成员变量mFC,mPluginAttributes仅用于存储plugin参数的的名称,类型
构造函数
TestAddPluginCreator::TestAddPluginCreator()
{
mPluginAttributes.clear();
mPluginAttributes.emplace_back(PluginField("alpha", nullptr, PluginFieldType::kFLOAT32, 1));
mFC.nbFields = mPluginAttributes.size();
mFC.fields = mPluginAttributes.data();
}初始化mFC
createPlugin
IPluginV2DynamicExt* TestAddPluginCreator::createPlugin(const char* name, const PluginFieldCollection* fc) noexcept
{
const PluginField* fields = fc->fields;
PLUGIN_ASSERT(fc->nbFields == 1);
PLUGIN_ASSERT(fields[0].type == PluginFieldType::kFLOAT32);
float bias = *(static_cast<const float*>(fields[0].data));
TestAddPlugin* obj = new TestAddPlugin{bias};
obj->setPluginNamespace(mNamespace.c_str());
obj->initialize();
return obj;
}
通过传入PluginFieldCollection将plugin相关的参数传入创建plugin并初始化
deserializePlugin
IPluginV2DynamicExt* TestAddPluginCreator::deserializePlugin(
const char* name, const void* serialData, size_t serialLength) noexcept
{
TestAddPlugin* obj = new TestAddPlugin{serialData, serialLength};
obj->setPluginNamespace(mNamespace.c_str());
obj->initialize();
return obj;
}// onnx2trt
DEFINE_BUILTIN_OP_IMPORTER(TRT_PluginV2)
{
std::vector<nvinfer1::ITensor*> tensors;
for (auto& input : inputs)
{
ASSERT(input.is_tensor() && "The input must be a tensor.", nvonnxparser::ErrorCode::kUNSUPPORTED_NODE);
tensors.push_back(&input.tensor());
}
OnnxAttrs attrs(node, ctx);
nvinfer1::IPluginRegistry* registry = getPluginRegistry();
std::string name = attrs.get<std::string>("name");
std::string version = attrs.get<std::string>("version");
std::string nspace = attrs.get<std::string>("namespace");
std::string buffer = attrs.get<std::string>("data");
nvinfer1::IPluginCreator* creator = registry->getPluginCreator(name.c_str(), version.c_str(), nspace.c_str());
ASSERT(creator && "Plugin not found, are the plugin name, version, and namespace correct?",
nvonnxparser::ErrorCode::kINVALID_NODE);
auto const plugin = creator->deserializePlugin("", buffer.data(), buffer.size());
nvinfer1::IPluginV2Layer* layer = ctx->network()->addPluginV2(tensors.data(), tensors.size(), *plugin);
ctx->registerLayer(layer, node);
RETURN_ALL_OUTPUTS(layer);
}在onnx2trt中,onnx node的数据会被读取反序列化成一个trt layer
class TestAddPlugin : public nvinfer1::IPluginV2DynamicExt
{
/*
input a, b
a = a + bias
b = a + b
return a + b
*/
public:
TestAddPlugin(float bias);
TestAddPlugin(const void* buffer, size_t length);
TestAddPlugin() = delete;
~TestAddPlugin() override = default;
int32_t getNbOutputs() const noexcept override;
DimsExprs getOutputDimensions(int outputIndex, const nvinfer1::DimsExprs* inputs,
int nbInputs, nvinfer1::IExprBuilder& exprBuilder) noexcept override;
int initialize() noexcept override;
void terminate() noexcept override;
size_t getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs,
int nbInputs, const nvinfer1::PluginTensorDesc* outputs, int nbOutputs) const noexcept override;
int enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc,
const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream) noexcept override;
size_t getSerializationSize() const noexcept override;
void serialize(void* buffer) const noexcept override;
bool supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut,
int nbInputs, int nbOutputs) noexcept override;
const char* getPluginType() const noexcept override;
const char* getPluginVersion() const noexcept override;
void destroy() noexcept override;
nvinfer1::IPluginV2DynamicExt* clone() const noexcept override;
void setPluginNamespace(const char* pluginNamespace) noexcept override;
const char* getPluginNamespace() const noexcept override;
nvinfer1::DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const noexcept override;
void attachToContext(cudnnContext* cudnn, cublasContext* cublas, nvinfer1::IGpuAllocator* allocator) noexcept override;
void detachFromContext() noexcept override;
void configurePlugin(const nvinfer1::DynamicPluginTensorDesc* in, int nbInputs,
const nvinfer1::DynamicPluginTensorDesc* out, int nbOutputs) noexcept override;
private:
int m_bias;
std::string mPluginNamespace;
std::string mNamespace;
};构造函数
TestAddPlugin::TestAddPlugin(float bias)
: m_bias(bias)
{
PLUGIN_VALIDATE(bias >= 0.0F);
}
TestAddPlugin::TestAddPlugin(const void* buffer, size_t length)
{
char const *d = reinterpret_cast<char const*>(buffer), *a = d;
m_bias = read<float>(d);
PLUGIN_VALIDATE(d == a + length);
}-
第一个构造函数用于创建plugin,
TestAddPluginCreator::createPlugin通过传入PluginFieldCollection传递plugin相关的参数信息构造plugin -
第二个构造函数用于在
deserialize时,在反序列化期间,TensorRT 从插件注册表中查找插件创建器并调用creator->deserializePlugin,将序列化好的参数信息传入构建plugin、
initialize,terminate,destroy
int TestAddPlugin::initialize() noexcept
{
return 0;
}
void TestAddPlugin::terminate() noexcept {}
void TestAddPlugin::destroy() noexcept
{
delete this;
}- initialize: 用于初始化开辟内存空间,但是不建议自己去申请显存空间,可以使用Tensorrt官方接口传过来的workspace指针来获取显存空间。
- terminate: 释放这个initialize开辟的一些显存空间,一般会放在析构函数里
- destroy:释放整个plugin占用的资源
获取plugin信息
//Plugin输出的Tensor数量
int32_t TestAddPlugin::getNbOutputs() const noexcept
{
return 1;
}
//Plugin输出的Tensor的Dimension信息
DimsExprs TestAddPlugin::getOutputDimensions(
int outputIndex, const nvinfer1::DimsExprs* inputs, int nbInputs, nvinfer1::IExprBuilder& exprBuilder) noexcept
{
PLUGIN_ASSERT(outputIndex == 0);
return nvinfer1::DimsExprs(inputs[0]);
}
//Plugin输出的Tensor的DataType信息
nvinfer1::DataType TestAddPlugin::getOutputDataType(
int index, const nvinfer1::DataType* inputTypes, int nbInputs) const noexcept
{
PLUGIN_ASSERT(inputTypes && nbInputs > 0 && index == 0);
return inputTypes[0];
}
//Plugin需要的中间显存数据大小
size_t TestAddPlugin::getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs, int nbInputs,
const nvinfer1::PluginTensorDesc* outputs, int nbOutputs) const noexcept
{
return 0;
}
//序列化时需要写多少byte
size_t TestAddPlugin::getSerializationSize() const noexcept
{
return sizeof(float);
}
//PluginType
const char* TestAddPlugin::getPluginType() const noexcept
{
return KTEST_ADD_PLUGIN_NAME;
}
//PluginVersion
const char* TestAddPlugin::getPluginVersion() const noexcept
{
return KTEST_ADD_PLUGIN_VERSION;
}
//设置plugin的namespace,同一namespace下如果相同的plugin名会冲突
void TestAddPlugin::setPluginNamespace(const char* pluginNamespace) noexcept
{
mPluginNamespace = pluginNamespace;
}
//plugin的namespace
const char* TestAddPlugin::getPluginNamespace() const noexcept
{
return mPluginNamespace.c_str();
}
serialize
void TestAddPlugin::serialize(void* buffer) const noexcept
{
char *d = reinterpret_cast<char*>(buffer), *a = d;
write(d, m_bias);
PLUGIN_ASSERT(d == a + getSerializationSize());
}- serialize: 将把plugin的数据按序写入buffer
clone
nvinfer1::IPluginV2DynamicExt* TestAddPlugin::clone() const noexcept
{
auto* plugin = new TestAddPlugin(m_bias);
plugin->setPluginNamespace(mPluginNamespace.c_str());
plugin->initialize();
return plugin;
}- clone: 克隆一个plugin
attachToContext, detachFromContext
void TestAddPlugin::attachToContext(
cudnnContext* cudnn, cublasContext* cublas, nvinfer1::IGpuAllocator* allocator) noexcept
{
}
void TestAddPlugin::detachFromContext() noexcept {}
- attachToContext:如果plugin需要用到cudnn,cublas,将plugin附加到执行上下文,并授予plugin对某些上下文资源的访问权限
- detachFromContext: 将plugin从其执行上下文中分离出来
configurePlugin
void TestAddPlugin::configurePlugin(const nvinfer1::DynamicPluginTensorDesc* in, int nbInputs,
const nvinfer1::DynamicPluginTensorDesc* out, int nbOutputs) noexcept
{
PLUGIN_ASSERT(nbInputs == 2 && in[0].desc.dims.d[1] != -1);
}
- configurePlugin:判断输入和输出类型数量是否正确
enqueue
int TestAddPlugin::enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc,
const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream) noexcept
{
PLUGIN_VALIDATE(inputDesc[0].dims.nbDims == inputDesc[1].dims.nbDims)
int n1 = 1, n2 = 1;
for (int i = 0; i < inputDesc[0].dims.nbDims; ++i)
{
n1 *= inputDesc[0].dims.d[i];
n2 *= inputDesc[1].dims.d[i];
}
PLUGIN_ASSERT(n1 == n2);
const void* inputData1 = inputs[0];
const void* inputData2 = inputs[1];
void* outputData = outputs[0];
//testAddInference : 调用cuda kernel函数
pluginStatus_t status = plugin::testAddInference(stream, n1, m_bias, inputData1, inputData2, outputData);
return status;
}
// cuda kernel函数实现 plugin/common/kernels/testAdd.cu
#include "common/kernels/kernel.h"
namespace nvinfer1
{
namespace plugin
{
template <unsigned nthdsPerCTA>
__launch_bounds__(nthdsPerCTA) __global__
void testAddKernel(const int n, const float bias, const float* input_1,const float* input_2, float* output)
{
for (int i = blockIdx.x * nthdsPerCTA + threadIdx.x; i < n; i += gridDim.x * nthdsPerCTA)
{
output[i] = input_1[i] + bias + input_2[i] ;
// printf("%f, %f, %f, %f,\n",output[i],input_1[i],bias, input_2[i]);
}
}
pluginStatus_t testAddGPU(cudaStream_t stream, const int n, const float bias, const void* input_1,const void* input_2,void* output)
{
const int BS = 512;
const int GS = (n + BS - 1) / BS;
testAddKernel<BS><<<GS, BS, 0, stream>>>(n, bias, (const float*) input_1,(const float*) input_2, (float*) output);
return STATUS_SUCCESS;
}
pluginStatus_t testAddInference(
cudaStream_t stream, int32_t n, float bias, void const* input_1, void const* input_2, void* output)
{
return testAddGPU(stream, n, bias, (const float*) input_1, (const float*) input_2, (float*) output);
}
} // namespace plugin
} // namespace nvinfer1
- enqueue: plugin的执行函数,如果plugin需要用到显存,可以利用指针参数workspace获取。关于workspace如何使用,可以参考官方plugin中的一些plugin。
- 在plugin/CMakeLists.txt加入testAddplugin

-
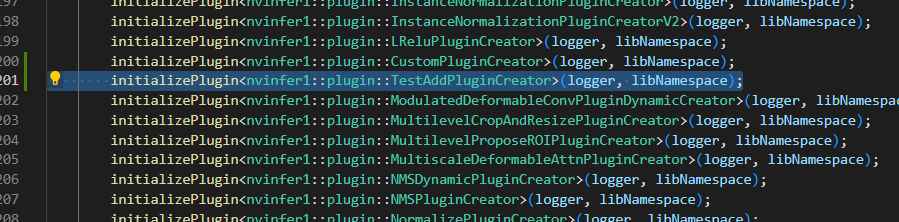
plugin/api/inferPlguin.cpp 配置initializePlugin
-
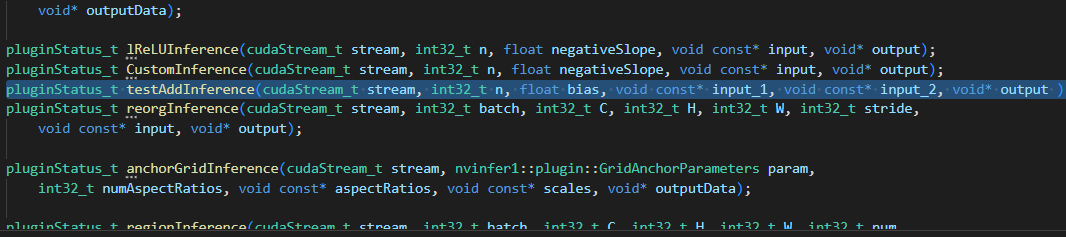
plugin/common/kernels/kernel.h配置kernel函数:
-
添加onnx2trt:parsers/onnx/builtin_op_importers.cpp




-使用trtexec执行带有TestAdd节点的onnx文件:
- 使用官方的tensorRT的动态库,报错

- 将编译TensorRT项目编译的动态库拷贝到tensorRT lib中,就可以在TensorRT运行我们的带有TestAdd节点的onnx文件了

至此,就实现了TensorRT的Plugin的实现了
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#extending
https://zhuanlan.zhihu.com/p/297002406
https://blog.csdn.net/sinat_41886501/article/details/129624918