RESTful Log Analysis Service for lastfm 1K dataset
There are 3 different Makefile the following will display help messages for all 3.
make help
First of we need to create a virtual machine to run the service on.
make docker-init
I've experienced hang when installing the EPEL rpm packege. In that case simply 'CTRL+C' and re-run the make command above.
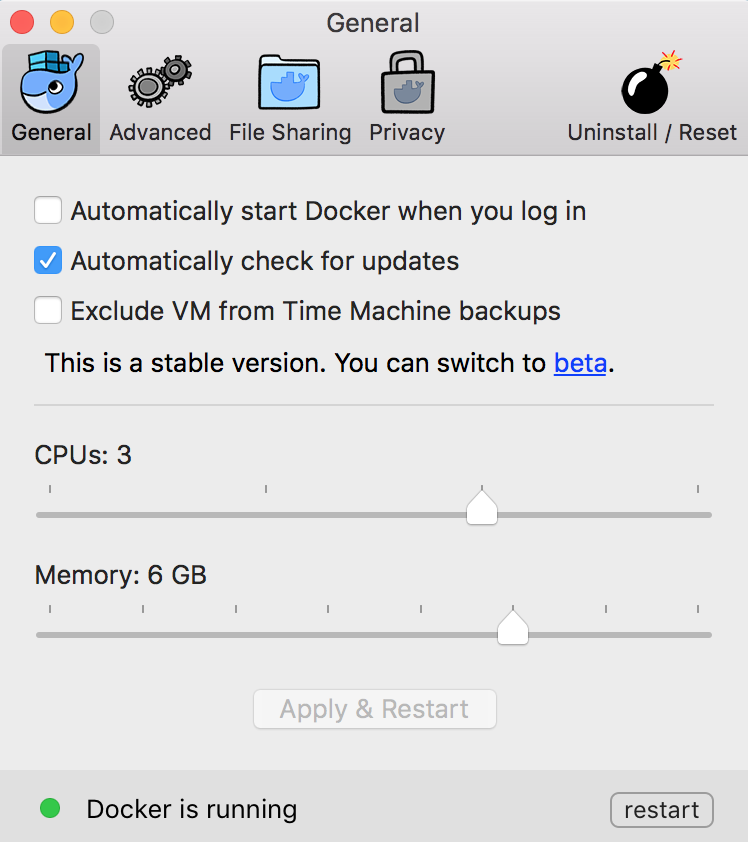
Before starting the virtual machine, please give docker as much memory and CPU as they can have.
Docker Preferences:
To start the service:
make docker-start
This should leave us with an active bash shell running.
In case of an error we will receive messages here.
Note that the active user is root in this shell,
while the REST service is running as the lastfm user.
If there is a need to change the DB_INSERT_POOL_WORKERS or DB_INSERT_POOL_CHUNK_SIZE for the service, run:
su - lastfm -c 'DB_INSERT_POOL_WORKERS=10 DB_INSERT_POOL_CHUNK_SIZE=5 make -C lastfm-log-analysis stop start test'
These environment variables control the how many connections there will be to MySQL at once, and how many rows of the uploaded dataset file will be handled (inserted into MySQL) by a single worker. The default value is 50 for both of these variables.
Once we have the service running inside docker, we can start sending REST requests to it from the host OS as well. To test this, simply run (from the folder on the host machine, where the git repo was originally cloned to):
make test
One can change the top n users, songs, sessions to be responded back with, by setting the TOP_N env. var.:
TOP_N=5 make test
To run with the lastfm dataset, specify the file path in the DATASET_PATH environment variable and
run the same make target:
DATASET_PATH=~/lastfm-dataset-1K/userid-timestamp-artid-artname-traid-traname.tsv make test
There is web-server accepting HTTP request in a RESTful fashion. One can POST or DELETE a log Resource, GET various analytical Resources. The data-set POSTed to the web-server is inserted into a Relational Database in chunks and in parallel. The analytical queries were translated into SQL queries, so that the Database can provide the answers. The web-server and the database run on the same machine. As a result they can simply connect through a unix file socket. Both the web-server and the database run in their own separated environments. As it was unknown on what OS this service as a whole were run later, I have provided a way to build and start a virtual machine, housing both web- and database- servers. This should also reduce problems due to dependencies or due to different OS versions, configurations.
First I've read about how to solve the task using a MapReduce framework. I've found out that Spark and Cassandra would be an interesting combination. I've found that while there is python flavored Spark shell, due to integration issues into a web service, Scala is the only real choice for PL. The most promising RESTful web-server I've found implemented is Scala was Play. If I've had some experience in Scala, I'd gone with those Frameworks: Play, Spark and possibly Cassandra.
However, after 2 days of research, I was afraid to run out of time for this exercise.
I decided to go with technologies I am familiar with and know can do some of the tasks done.
These technologies were Python and MySQL.
I knew that there might be problems installing a MySQL database,
so I've added OS virtualization, Docker to the mix.
All of these 3 technologies are integrated into Makefiles.
make is the most common build tool and anyone can use it.
It nicely tides everything together into Continuous Integration workflow.
MySQL and Relational databases are clearly not a viable solution for Log Analysis. This solution only work for a single log file structure and a single user. Multiple users can query the same log dataset, but they cannot have separate datasets to work with. This feature could be added by separating schemas for each analyser/user.
There is bug in the way sessions are identified. I ran out of time to fix this. So task no 4 is incomplete, as the response will probably be incorrect.
Populating the database is slow, even with concurrent writers.
Importing the big ~2M lines dataset resulted in memory issues when running inside docker. So, as a quick guess, I've halfed the default number of workers and chunk size.
I feel this is a very rudimentary solution of the task. I've honestly under estimated the complexity of the task and probably spent to much time on researching how to attack it. Either that or I have over complicated it and have done things were not necessary.