Why | How | Key Theories | Key Experiments | Team Bios | Investors Files |
"I wish I'd had the courage to live a life true to myself, not the life others expected of me. I mean it, promise this dying women that you will always be true to yourself, that you will be brave enough to live the way you want to live regardless of what other poeple say."
~ Grace

I believe that intelligent machines will be able to solve many of our hardest problems and will cause many new hard problems. Our hardest problems like cancer, mortality, and secrets of the universe involve understanding a lot of data and as humans we are limited by the processing power and size of our brains. But if we figure out the computational principles that make you and I intelligent, simulate them on a computer, scale it up to surpass the collective intelligence of the 7+ billion people on Earth we will have created intelligent machines that do not need to eat, sleep, or reproduce that can work on our hardest problems much more efficiently than humans.
Technology has always been used to do great good and great evil and even if we have the best intentions to do good, intelligent machines will cause many new problems. For example there will be massive job loss since most jobs can be replaced by intelligent machines. A possible solution to this hard problem will be to augment our brains and become super intelligent.
The current short term goal is to experiment with a simplified visual pathway from an eye(that can move within a room) to experimental general learning algorithms that model hierarchical regions in layer 2/3, 4, & 5 of the neocortex (70+% of the brain) to understand the principles of intelligence.
The long term goal of this repository is to store code that can simulate the general learning ability of a full sized human brain in real time.
After we understood the principles of flight we were able to build planes that are much faster and can carry more weight than birds. After we understand the human brain's computation principles we will be able to create intelligent machines much more intelligent than humans with unimaginable capabilities. At first it will not have any emotions like you and I. This will be a good thing because it will force us to ask if it would be moral to create an super intelligent machine with emotions to help us. It may not necessarily be a good thing for the human race. For example look at how humans treat intelligent pigs. We are more intelligent emotional machines compared to pigs and the future super intelligent emotional machines will be much more intelligent compared to us.
If you are interested in becoming a researcher/developer I would be grateful for your collaboration as I cannot do this alone. We currently have $$$ so read how to contribute to get started. If you are interested in donating please read investors.
This research was initially inspired by everyone at Numenta. Numenta has theorized and tested algorithms that model layers 2/3 & 4 of the human neocortex(~70% of human brain). They generously released the pseudo code for their learning algorithms, and this repository is an extended implementation of their algorithms using object-oriented programming with a focus on understandability over speed and applications to human vision using hierarchy and sensory motor integration. Numenta's implementation of their algorithms can be found here. For more information please:
- Watch this video playlist to become familiar with the neuroscience behind this repository.
- Read Numenta's great explanation of their research in this white paper to better understand the theory behind this repository.
~ Q Liu
Forget everything you know.
Let go of your ego and understand building the first general strong AI is not some competition for fame, money, or respect but for seeking truth and making sure the most advanced known technology that evolution has created is used to prevent valotile suffering for all organisms with conciousness.
Then think about what an intelligent machine needs to be able to do from first principles. Build a model using what you know from mathematics, machine learning, and neuroscience. If you can not build an intelligent machine smarter than humans than you do not understand intelligence. And even if you do manage to build an intelligent machine there is still a lot you do not understand about intelligence.
Experiment with your model on tasks that only intelligent machines seem to be good at. Be extremely open to ways to change the model. Remember that the earth was born about 4.6 billion years ago and that it took evolution about 4.6 billion - 200,000 years to create the first homo sapian. This shit takes time so if your frustrated go relax.
Remember to focus on discovering principles of intelligence instead of getting lost in the details of modeling everything a brain does or optimizing a mathematical algorithm. There is a good reason why planes and helicopters do not look like birds.
And as stupid as it sounds remember that it is the journey you go on that makes everything worth it when you look back. Sometimes life will hit you with a hammer. When it does take time to regain your hope in humanity in any way you feel is right and take as much time as you need. When you get back up you will be a stronger version of yourself and ready to fail even harder again :)
Install all code with IntelliJ (Recommended) or Gradle for Linux/Mac/Windows and then read how to contribute.
-
If you have any problems with the following instructions please e-mail quinnliu@vt.edu and I will try to help the best I can. First make sure you have java version 1.8. To check open up a new terminal and type:
prompt> java -version java version "1.8.0_60" # it's only important to see "1.8" in # the version
If you don't have any of those Java versions install java 1.8 by going here. After installing java 1.8 open up a new terminal to check if java 1.8 is installed by retyping
java -versionin the terminal. -
Then install IntelliJ IDEA FREE Community Edition.
- Note where you choose to install this and choose a folder that is easy to access (I stored it in Documents)
-
Open up IntelliJ and create a test project and get HelloWorld working. You will need to find your Java 1.8 jdk in the process. Once you have a program that can print something continue.
-
Go to the top right of this page and hit the
Forkbutton. Then clone your forked wAlnut repository locally. -
Inside IntelliJ, on Windows go to "File"
=>"Import Project...". On Mac go to "File"=>"Project from Existing Sources...". This should open up a new window and you should easily be able to select the "wAlnut" folder. Click "OK". -
Select "Import project from external model". Then select "Gradle" and hit "Next".
-
Select "Use default gradle wrapper (recommended)"
=>hit Finish -
In the left side file viewer right-click the folder "wAlnut" and select
Run 'Tests in wAlnut'. Congrats! Go buy yourself some pistachio ice cream :)
-
If you have any problems with the following instructions please e-mail quinnliu@vt.edu and I will try to help the best I can. First make sure you have java version 1.8. To check open up a new terminal and type:
prompt> java -version java version "1.8.0_60" # it's only important to see "1.8" in # the version
If you don't have any of those Java versions install java 1.8 by going here. After installing java 1.8 open up a new terminal to check if java 1.8 is installed by retyping
java -versionin the terminal. -
Go to the top right of this page and hit the
Forkbutton. Then clone your forked WalnutiQ repository locally. Navigate into theWalnutiQ/folder. -
To run all of the code in the Linux or Mac terminal type:
prompt> ./gradlew build # some other stuff... BUILD SUCCESSFUL # If you see `BUILD SUCCESSFUL` all of the tests have passed!
-
To run all of the code in the Windows terminal type:
prompt> gradlew.bat # some other stuff... BUILD SUCCESSFUL # If you see `BUILD SUCCESSFUL` all of the tests have passed!
-
In the future after editing some code make sure to clean your old compiled code before rerunning the tests by typing:
prompt> ./gradlew clean # removes your old compiled code prompt> ./gradlew build # Congrats! Go buy yourself some watermelon :)
-
I am now looking to pay other developers a hourly rate of $30/hour(limited up to 5 hours/week) to code features for WalnutiQ. The most up to date income and payment data can be viewed here.
-
Sorry but you must meet these minimum requirements:
- Know how to use Git & Github.com. If you don't know how I created a 1.5 hour playlist on how to use Git & Github here.
- Be curious about how the human brain works. You don't need to be passionate about it right now.
- Written at least 3 thousand lines of Java in your life.
-
E-mail quinnliu@vt.edu the following:
- Link to source code of project you enjoyed working on the most. I am really just looking for good object oriented design and good documention.
- Why you want to work on wAlnut.
-
If I e-mail you back for an interview during the interview we will discuss:
- How everything will work. Expect to pair program with someone for a few hours a week.
- If we both like what we hear we will walk you through making your 1st commit to the repo's master branch!
-
For now we are using the Git workflow model described here to contribute to this repository effectively.
-
While reading through the code base it will be very helpful to refer to the following labeled model:
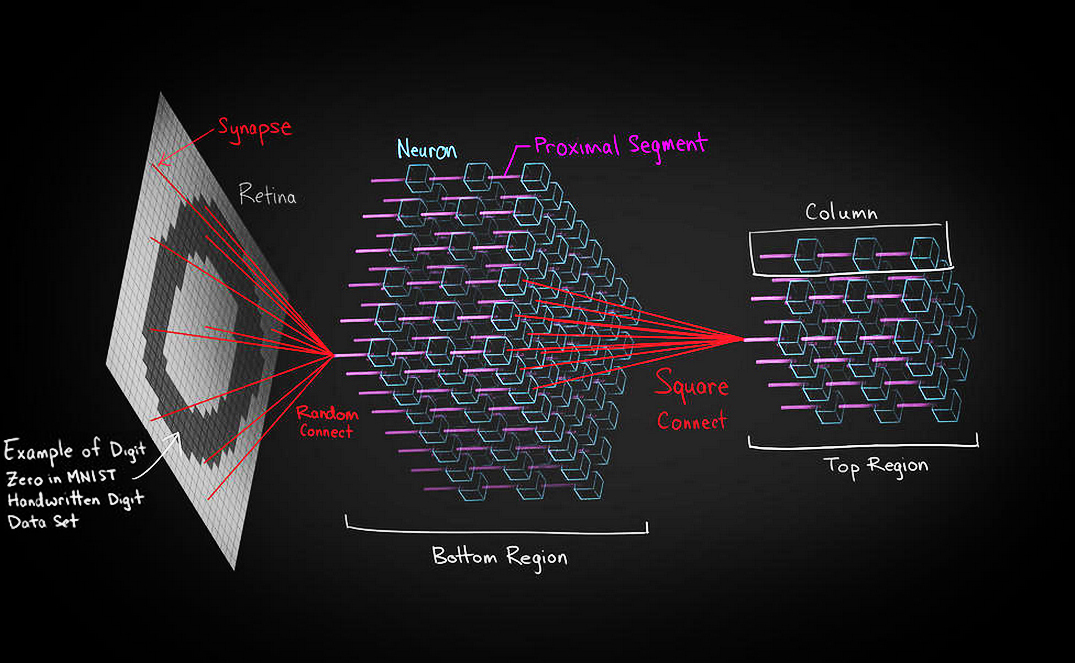
-
Theory 1: 1 common learning algorithm in the neocortex of the brain
-
Supportive:
-
1992 Paper here from Department of Brain and Cognitive Sciences at MIT.
- Summary: A portion of wires of the optic nerve are routed to the
auditory cortex in ferrets. The neurons of this primary auditory
cortex(A1) with vision input did not work exactly like neurons in
primary visual cortex(V1). Neurons in rewired A1 had larger receptive
field sizes and other differences. However there are also
similarities including:
- rewired A1 neurons showed orientation and direction selectivity.
- similar proportions of simple, complex, and nonoriented cells between rewired A1 and V1.
- implies "significant implications for possible commonalities in intracortical processing circuits between sensory cortices".
- Summary: A portion of wires of the optic nerve are routed to the
auditory cortex in ferrets. The neurons of this primary auditory
cortex(A1) with vision input did not work exactly like neurons in
primary visual cortex(V1). Neurons in rewired A1 had larger receptive
field sizes and other differences. However there are also
similarities including:
-
1988 Paper here from Laboratoire des Neuroscience de la Vision at Universite de Paris.
- Summary: Wires of the optic nerve were routed permanently to the
main thalamic somatosensory nucleus in hamsters. After the hamsters
grew up the neurons in the somatosensory cortex were recorded.
The "somatosensory neurons responded to visual stimulation of
distinct receptive fields, and their response properties resembled,
in several characteristic features, those of normal visual cortical
neurons."
- "the same functional categories of neurons occurred in similar proportions, and the neurons' selectivity for the orientation or direction of movement of visual stimuli was comparable" between normal hamsters and rewired hamsters.
- "These results suggest that thalamic nuclei or cortical areas at corresponding levels in the visual and somatosensory pathways perform similar transformations on their inputs".
- Summary: Wires of the optic nerve were routed permanently to the
main thalamic somatosensory nucleus in hamsters. After the hamsters
grew up the neurons in the somatosensory cortex were recorded.
The "somatosensory neurons responded to visual stimulation of
distinct receptive fields, and their response properties resembled,
in several characteristic features, those of normal visual cortical
neurons."
-
2008 PhD thesis here by Dileep George from Stanford University
- There is a idea in optimization algorithms called No Free Lunch theorem. No Free Lunch theorem "state[s] that any two optimization algorithms are equivalent when their performance is averaged across all possible problems".
- "On the surface, the NFL theorem seems to create problems for the idea of a common cortical algorithm. How can one mechanism/algorithm do very well on tasks as different as vision, audition and language? The answer comes from the part of the NFL theorem that talks about the assumptions that need to be exploited ... If the cortex is good at learning a wide variety of tasks using a common mechanism, then there must be something common about these seemingly different tasks.".
-
-
Not supportive:
-
2002 Paper here from Vision, Touch and Hearing Research Centre at The University of Queensland.
- "recent studies have revealed substantial variation in pyramidal cell structure in different cortical areas".
- Some of these variations like increase in dendritic arbor size( dendritic branching) can be resolved with the idea of a common algorithm.
-
2008 PhD thesis here by Dileep George from Stanford University
- "Until we understand and explain the computational reason behind a large majority of such variations, the common cortical algorithm will have to be considered as a working hypothesis".
-
-
Conclusion: If cortex X(arbitrary cortex) of the neocortex(contains visual cortex, auditory cortex, somatosensory cortex, and others..) can be given non-normal sensory input usually given to say cortex Y and then learn to process this new input similarily to how cortex X would process it, then we can hypothesize that there is a common learning/predicting algorithm in all cortices of the neocortex.
-
-
Theory 2: The common learning algorithm efficiently learns about the world by making a specific set of assumptions about the world. This is the inductive bias of the common learning algorithm. To find all assumptions the question we need to ask is "What is the basic set of assumptions that are specific enough to make learning feasible in a reasonable amount of time while being general enough to be applicable to a large class of problems?" ~ Dileep George
-
Assumption 1: If pattern B follows pattern A in time then they are causally related and in the future pattern A should predict pattern B.
- Supportive:
- The brain is constantly making predictions about the future.
- Not supportive:
- How does the brain make predictions multiple time steps into the future?
- Conclusion: Yes, specific enough to make learning feasible and general enough for large class of problems.
- Supportive:
-
Assumption 2:
Manifold = all the images generated by the same object in a high-dimensional space.If object A occurs close together to object B in time than object C then object A and object B are more similar. This information is used to form manifolds aka invariant representations of the objects.
- Supportive:
- A baby has to learn this way before it understands speech.
- Not supportive:
- Conclusion: Yes, specific enough to make learning feasible and general enough for large class of problems.
- Supportive:
-
Assumption 3: During the current time step of the common learning algorithm, it will always recieve input about what muscles were used in the last time step.
- Supportive:
- Consciouness doesn't get confused when the eye is moving around. This means every region in the neocortex must be recieving input about the eye's sensori-motor movement so it can use it to accurately predict the future.
- Supportive:
- Not supportive:
- Conclusion: This assumption is specific enough to make learning feasible in a reasonable amount of time while being general enough to be applicable to a large class of problems.
- Assumption 4:
Complex invariant representations are made up of less complex invariant
representations in a hierarchy.
- Supportive:
- More ideas in the universe than neurons in the brain. Also the universe has natural hierarchies.
- The neocortex has a hierarchal structure.
- Not supportive:
- Conclusion: The common learning algorithm first learns invariant representations of object components then learns invariant representations of more complex objects in terms of the invariant representations of the components.
- Supportive:
The following experiments show off how a general learning algorithm uses the brain's data structure to it's advantage to process input data and create intelligence.
The first problem a general learning algorithm has is to not get confused by all the noise in the world. The noise invariance experiment illustrates how the first part of the algorithm does not get confused by noisy input data.
Here is some example code of how part of the theorized prediction algorithm works. It is a beautiful summary of how columns of neurons in your neocortex are probably working to encode what you see. The following are the three images the retina will be looking at:

retina.seeBMPImage("2.bmp");
spatialPooler.performPooling();
// set1 = ((6,2), (1,5))
// (6,2) and (1,5) are the columns in the Region that are active after seeing
// "2.bmp"
assertEquals(set1, this.spatialPooler.getActiveColumnPositions());
retina.seeBMPImage("2_with_some_noise.bmp");
spatialPooler.performPooling();
// set1 = ((6,2), (1,5))
// NOTE: the columns that are active are still the same even though there was
// quite a lot of noise in the input data
assertEquals(set1, this.spatialPooler.getActiveColumnPositions());
retina.seeBMPImage("2_with_a_lot_of_noise.bmp");
spatialPooler.performPooling();
// when there is a lot of noise notice how the active columns are
// no longer the same?
// set2 = ((6,2), (2,5))
assertEquals(set2, this.spatialPooler.getActiveColumnPositions());You can view the entire file in NoiseInvarianceExperiment.java. Please do not be afraid to ask a question if you are confused! This stuff took me several months to fully understand but it is really beautiful after you understand it.
Hi, I'm Q.
In 2011 I watched a talk about a guy trying to build a machine more intelligent than humans and I fell in love with this idea. At the time I believed that an intelligent machine would be able to solve many of our hardest problems(ex. secrets of the universe and cure for cancer) and would cause many new hard problems(ex. massive job loss). I was determined to use it to benefit humanity as much as possible but first I needed to build it.
I told myself I would give myself 1 year(end of 2012) to build a machine more intelligent than humans which I believed was plenty of time since I didn’t know how to code yet. By 2013 2 years had gone by and although I had learned a lot of interesting brain theories from neuroscientists and coding techniques from computer scientists I gave up on this dream out of frustration on my speed of progress and fell into a deep depression. Most of my identity came from the brain research I did and I had hit a wall in the research I did not have the confidence to break through.
After focusing on my physical health, family, and friends I eventually got out of my depression and decided to restart working towards my dream of creating a intelligent machine for the past year. However, this time I have learned to use habits over motivation, collaboration over working alone, sustainability over crunch, intense focus on what is necessary over nice to haves, acknowledgement you must sometimes forget what you know in order to create something new, and many beautiful ideas I have yet to learn.
Outside of AI I like to make YouTube videos, skateboard, watch tragic yet beautiful movies, and drink Mr. Green Genes from Juice Generation.
To us a wAlnut investor is someone who believes we can build a machine more intelligent than humans and use it for more good out of love than evil out of fear. In the history of mankind some technologies are so powerful it would be wrong to have it only accessible by a group of people. Examples include electricity, computers, the internet, and now its a machine smarter than humans. Our latest research and code will always be available here for free to everyone in the world with a laptop, internet, and a little bit of curiosity.
-
If you would like to become an investor of wAlnut simply venmo your donation. In the
Search Peoplesection type@walnutiqand look for the pink walnut logo. It will look similar to this: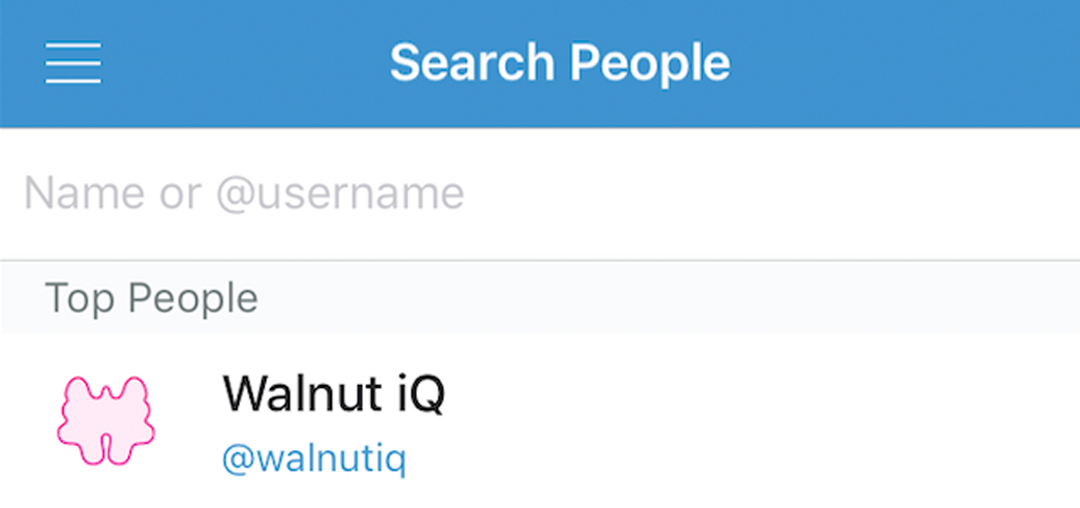
-
In the venmo
What's it for?section please provide the following information as you would like it to be displayed in our investors list. Here is an example of one of our investors: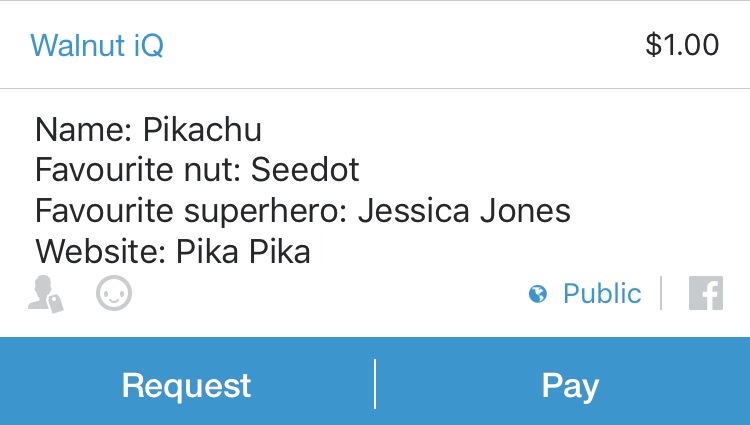
| Name | Amount (USD) | Favorite nut | Favourite superhero | Website |
|---|---|---|---|---|
| Q Liu | $1,729 | Pistachio Ice Cram | Shuyu Liu & Juan Zhao | YouTube |
| Aarathi Raghuraman | $140 | |||
| Pikachu | $1 | Seedot | Jessica Jones | Pika Pika |
If you are confused what a file is doing at a high level read what are all the files here for.
- gradle/wrapper = the actual Gradle code for building our Java code
- images = images used in training & testing the partial brain model
- referencedLibraries = contains .jar files(of other people's code) needed to run WalnutiQ
- src
- main/java/model
- MARK_II = the core logic for the
partial brain model. Includes abstract data types for basic brain
structures and learning algorithms that simulate how the brain learns.
- connectTypes = allow the different brain structures to connect to each other in a variety of ways
- generalAlgorithm
- failureResearch
- spatialAlgorithms = rethinking SDR algorithm to create different variations of the algorithms from the ground up using ideas from spatial pooler when necessary.
- temporalAlgorithms = rethinking a prediction algorithm to create different variations of the algorithm from the ground up using ideas from temporal pooler when necessary.
- SpatialPooler.java = models the sparse & distributed spiking activity of neurons seen in the neocortex and models long term potentiation and depression on synapses of proximal dendrites
- TemporalPooler.java = models neocortex's ability to predict future input using long term potentiation and depression on synapses of distal dendrites
- failureResearch
- parameters = allows construction of different WalnutiQ models from command line for this repo https://github.com/WalnutiQ/call_wAlnut
- region = components that make up a Region object
- sensory = classes for allowing brain model to receive sensory input
- unimplementedBiology = parts of the nervous system we haven't implemented into this model
- util = classes that enable the brain model properties to be viewed graphically and efficiently saved and opened
- MARK_II = the core logic for the
partial brain model. Includes abstract data types for basic brain
structures and learning algorithms that simulate how the brain learns.
- test/java/model = test classes for important classes in the
src/main/java/modelfolder- experiments/vision = experiments with partial visual pathway models
- main/java/model
- .gitignore = contains names of files/folders not to add to this repository but keep in your local WalnutiQ folder
- .travis.yml = tells our custom travis testing site what versions of Java to test the files here
- LICENSE.txt = GNU General Public License version 3
- README.md = the file you are reading right now
- build.gradle = compiles all of the code in this repository using Gradle
- gradlew = allows you to use Gradle to run all of the code in this repository in Linux & Mac
- gradlew.bat = allows you to use Gradle to run all of the code in this repository in Windows