
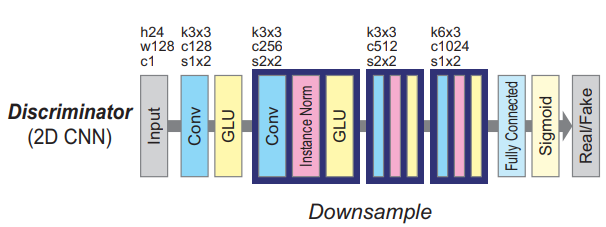
This code reproduces the CycleGAN-VC paper: PARALLEL-DATA-FREE VOICE CONVERSION USING CYCLE-CONSISTENT ADVERSARIAL NETWORKS, T. Kaneko, H. Kameoka 2017
I used this repository as a reference when stuck for ideas about how to interpret the paper.
Generated samples can be found here
This was a fun paper to reproduce. I was impressed that voice conversion can be learned from non-parallel examples in this way. I noted that log(f0) conversion carries a lot of weight in the way that the results sound because it shifts the pitch of the speaker, without the synthesized voices sound fairly close to the original input. At first I was disappointed that prosody (rhythm and timing) of the original speaker was maintained, but this can be desirable for voice conversion because you may not want to erase the speaker identity completely - this depends on application. Preservation of prosody can be explained by the relatively small receptive field of the convolutions.
I didn't get to reproducing the evaluation step of the paper and stopped at the point where synthesized examples sound close to the original paper's examples. I'm unlikely to keep tweaking it.
- Download training data
- You'll need vcc2016_training and evaluation_all unzipped
- Install python and dependencies
- install python3
python -m venv venv- `source venv/bin/activate``
- `pip install -r requirements.txt``
Once you've setup your environment and downloaded the data, you're ready to preprocess the data and train using the following commands:
python3 src/preprocess.py --help
usage: preprocess.py [-h] [--data_dir DATA_DIR] [--source_speaker SOURCE_SPEAKER] [--target_speaker TARGET_SPEAKER]
options:
-h, --help show this help message and exit
--data_dir DATA_DIR
--source_speaker SOURCE_SPEAKER
--target_speaker TARGET_SPEAKERpython3 src/train.py --help
usage: train.py [-h] [--source_speaker SOURCE_SPEAKER] [--target_speaker TARGET_SPEAKER] [--train_data_dir TRAIN_DATA_DIR] [--eval_data_dir EVAL_DATA_DIR] [--checkpoint_dir CHECKPOINT_DIR] [--resume_from_checkpoint RESUME_FROM_CHECKPOINT] [--eval_output_dir EVAL_OUTPUT_DIR]
[--source_logf0_mean SOURCE_LOGF0_MEAN] [--source_logf0_std SOURCE_LOGF0_STD] [--target_logf0_mean TARGET_LOGF0_MEAN] [--target_logf0_std TARGET_LOGF0_STD]
options:
-h, --help show this help message and exit
--source_speaker SOURCE_SPEAKER
Source speaker ID
--target_speaker TARGET_SPEAKER
Target speaker ID
--train_data_dir TRAIN_DATA_DIR
Path to training data
--eval_data_dir EVAL_DATA_DIR
Path to evaluation data
--checkpoint_dir CHECKPOINT_DIR
Path to checkpoint directory
--resume_from_checkpoint RESUME_FROM_CHECKPOINT
Resume training from latest checkpoint
--eval_output_dir EVAL_OUTPUT_DIR
Path to evaluation output directory
--source_logf0_mean SOURCE_LOGF0_MEAN
Source log f0 mean
--source_logf0_std SOURCE_LOGF0_STD
Source log f0 std
--target_logf0_mean TARGET_LOGF0_MEAN
Target log f0 mean
--target_logf0_std TARGET_LOGF0_STD
Target log f0 stdYou'll need to generate f0 stats in order to synthesize the waveforms with the correct pitch:
python3 src/preprocess.py --data_dir ./data/vcc2016_training/ --source_speaker SF1 --target_speaker TM3
SF1 log f0 mean: 5.388794225257816
SF1 log f0 std: 0.2398814107162179
TM3 log f0 mean: 4.858265991213904
TM3 log f0 std: 0.23171982666578547Make sure that the checkpoint and eval directories are created. The training program will periodically synthesize eval examples.
python3 src/train.py \
--resume_from_checkpoint False \
--checkpoint_dir SF1_TM3_checkpoints \
--source_speaker SF1 \
--target_speaker TM3 \
--source_logf0_mean 5.38879422525781 \
--source_logf0_std 0.2398814107162179 \
--target_logf0_mean 4.858265991213904 \
--target_logf0_std 0.23171982666578547
Epoch 0
Iteration: 10, it/s: 0.49, d_loss: 0.0083846, g_loss: 613.42, test_d_loss: 0.0028683, test_g_loss: 515.88
Iteration: 20, it/s: 0.75, d_loss: 0.0016719, g_loss: 602.03, test_d_loss: 0.0137144, test_g_loss: 644.71
Iteration: 30, it/s: 0.69, d_loss: 0.0010094, g_loss: 620.05, test_d_loss: 0.0019095, test_g_loss: 566.79
...