

The project contains 3 Jupyter notebook and 1 README.md file:
-
1 notebook for EDA
-
2 notebooks for 2 different final trained models
The year 2018 has been an inflection point for machine learning models handling text (or more accurately, Natural Language Processing or NLP for short).
Our conceptual understanding of how best to represent words and sentences in a way that best captures underlying meanings and relationships is rapidly evolving.
One of the latest milestones in this development is the release of BERT, an event described as marking the beginning of a new era in NLP. BERT is a model that broke several records for how well models can handle language-based tasks.
BERT builds on top of a number of clever ideas that have been bubbling up in the NLP community recently – including but not limited to Semi-supervised Sequence Learning (by Andrew Dai and Quoc Le), ELMo (by Matthew Peters and researchers from AI2 and UW CSE), ULMFiT (by fast.ai founder Jeremy Howard and Sebastian Ruder), the OpenAI transformer (by OpenAI researchers Radford, Narasimhan, Salimans, and Sutskever), and the Transformer (Vaswani et al).
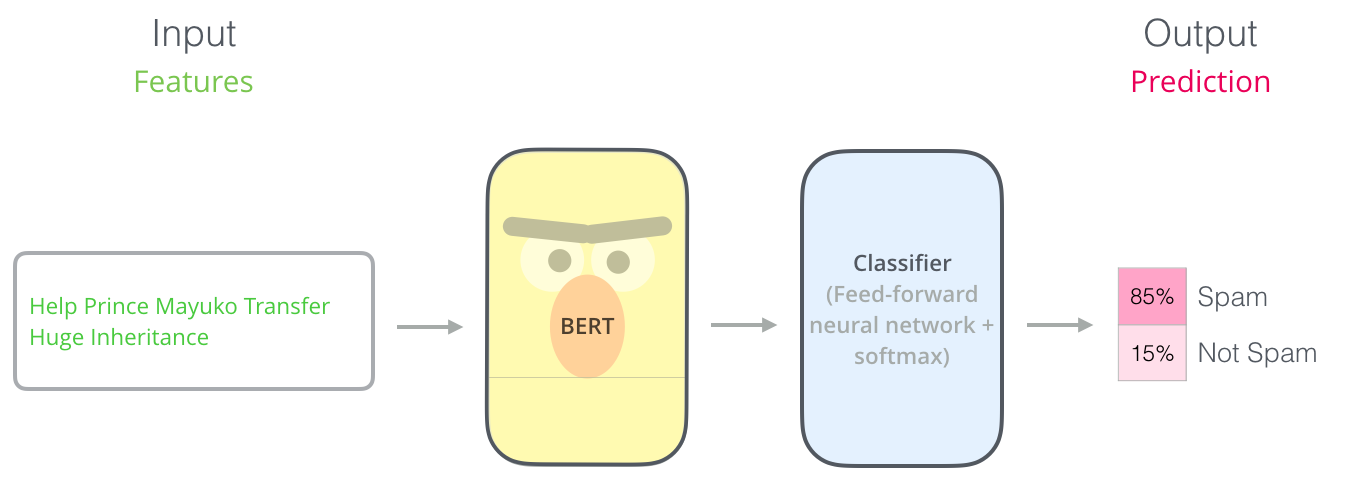
To train such a model, you mainly have to train the classifier, with minimal changes happening to the BERT model during the training phase. This training process is called Fine-Tuning.
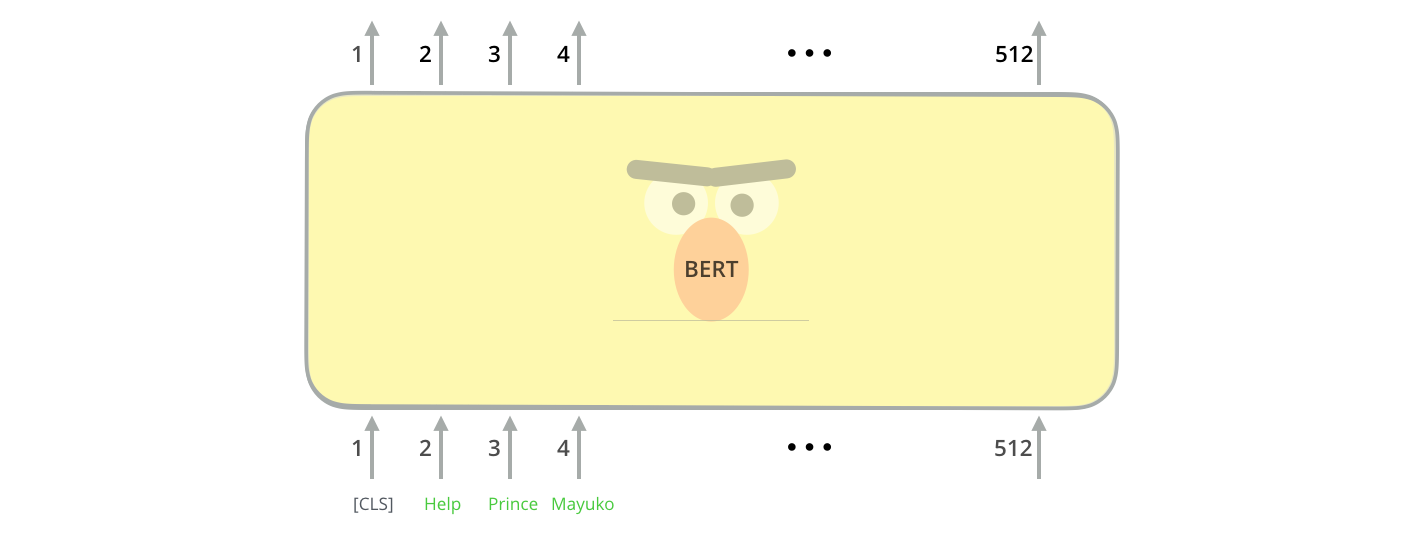
The first input token is supplied with a special [CLS] token for reasons that will become apparent later on. CLS here stands for Classification.
Just like the vanilla encoder of the transformer, BERT takes a sequence of words as input which keep flowing up the stack. Each layer applies self-attention, and passes its results through a feed-forward network, and then hands it off to the next encoder.
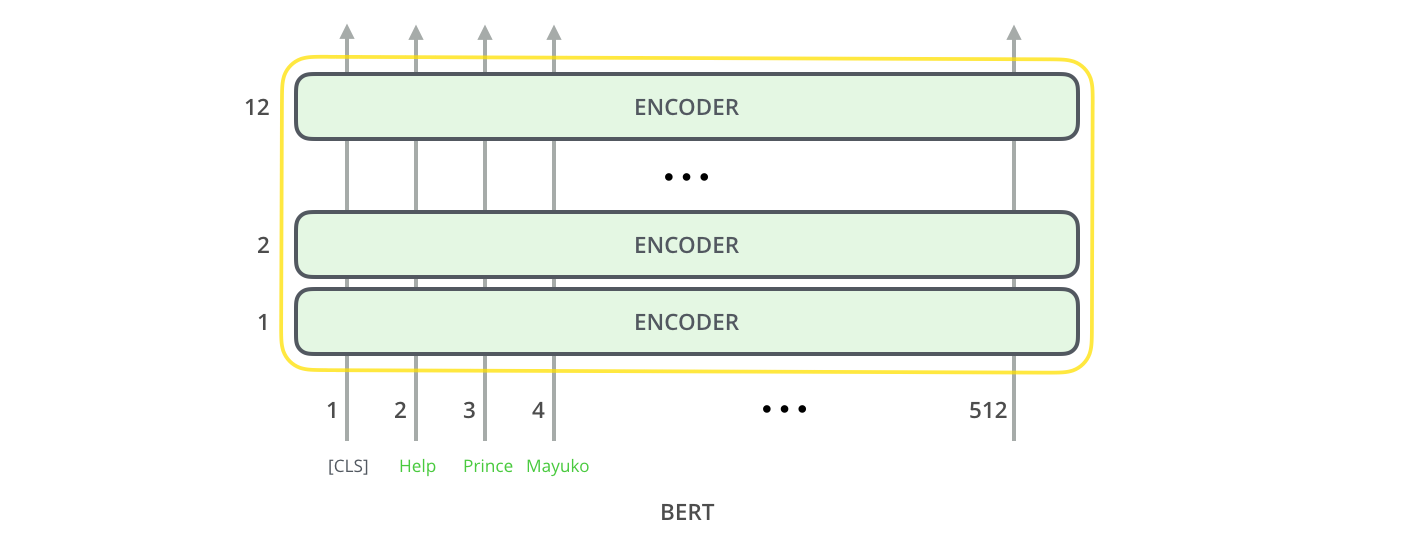
In terms of architecture, this has been identical to the Transformer up until this point (aside from size, which are just configurations we can set). It is at the output that we first start seeing how things diverge.
Each position outputs a vector of size hidden_size (768 in BERT Base). For the sentence classification example we’ve looked at above, we focus on the output of only the first position (that we passed the special [CLS] token to).
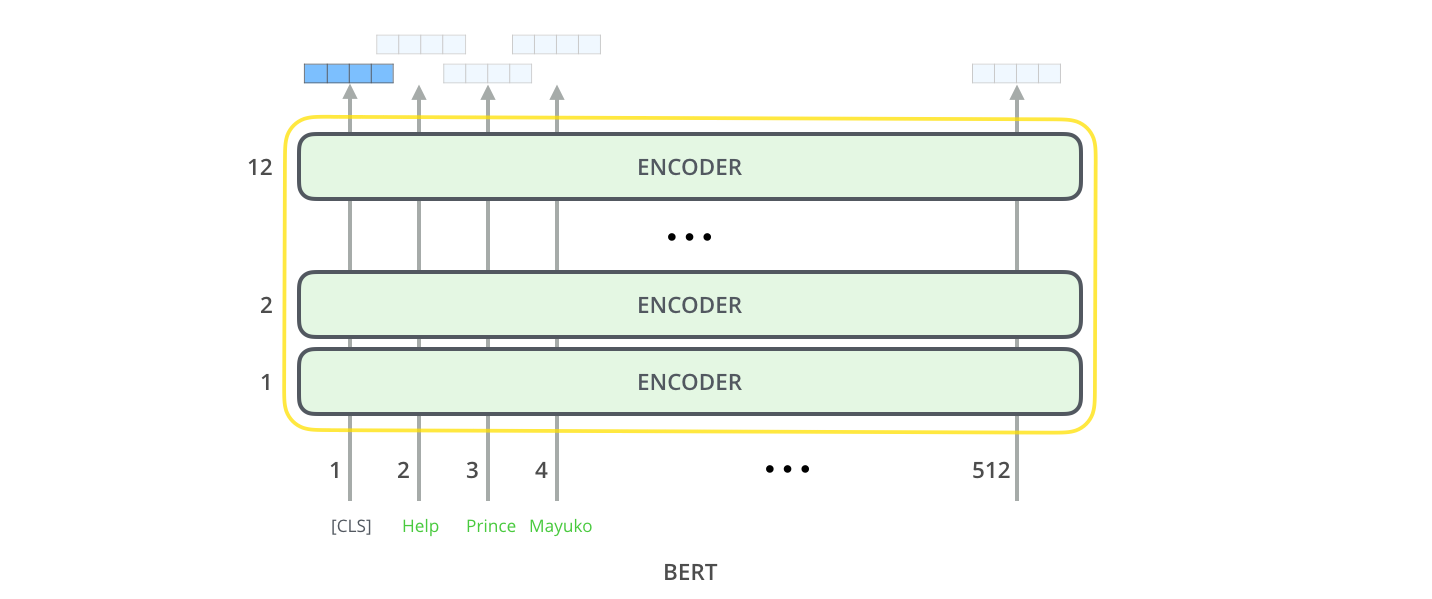
That vector can now be used as the input for a classifier of our choosing. The paper achieves great results by just using a single-layer neural network as the classifier.
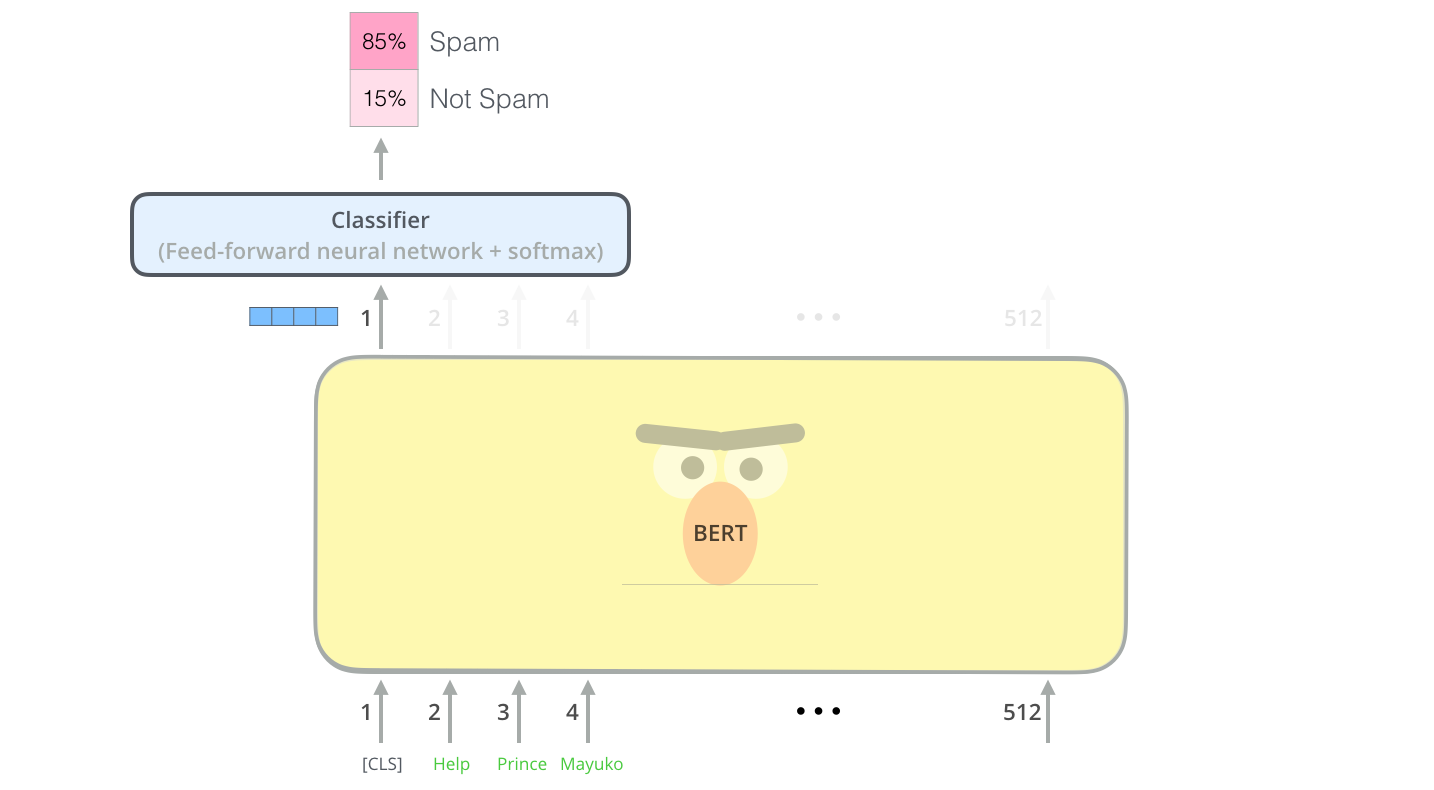
If you have more labels (for example if you’re an email service that tags emails with “spam”, “not spam”, “social”, and “promotion”), you just tweak the classifier network to have more output neurons that then pass through softmax.
The release of the Transformer paper and code, and the results it achieved on tasks such as machine translation started to make some in the field think of them as a replacement to LSTMs. This was compounded by the fact that Transformers deal with long-term dependancies better than LSTMs.
The Encoder-Decoder structure of the transformer made it perfect for machine translation. But how would you use it for sentence classification? How would you use it to pre-train a language model that can be fine-tuned for other tasks (downstream tasks is what the field calls those supervised-learning tasks that utilize a pre-trained model or component).
Further reading: to understand how RNNs, LSTMS work as well as why and how attention is used please see this Medium article written by member of team-6 Manu:
Transfer learning is a technique where a deep learning model trained on a large dataset is used to perform similar tasks on another dataset. We call such a deep learning model a pre-trained model. The most renowned examples of pre-trained models are the computer vision deep learning models trained on the ImageNet dataset. So, it is better to use a pre-trained model as a starting point to solve a problem rather than building a model from scratch.
There are multiple advantages of using transformer-based models, but the most important ones are:
-
These models do not process an input sequence token by token rather they take the entire sequence as input in one go which is a big improvement over RNN based models because now the model can be accelerated by the GPUs.
-
We don’t need labeled data to pre-train these models. It means that we have to just provide a huge amount of unlabeled text data to train a transformer-based model. We can use this trained model for other NLP tasks like text classification, named entity recognition, text generation, etc. This is how transfer learning works in NLP.
BERT (Bidirectional Encoder Representations from Transformers) is a big neural network architecture, with a huge number of parameters, that can range from 100 million to over 300 million. So, training a BERT model from scratch on a small dataset would result in overfitting.
- Train the entire architecture – We can further train the entire pre-trained model on our dataset and feed the output to a softmax layer. In this case, the error is back-propagated through the entire architecture and the pre-trained weights of the model are updated based on the new dataset.
- Train some layers while freezing others – Another way to use a pre-trained model is to train it partially. What we can do is keep the weights of initial layers of the model frozen while we retrain only the higher layers. We can try and test as to how many layers to be frozen and how many to be trained.
- Freeze the entire architecture – We can even freeze all the layers of the model and attach a few neural network layers of our own and train this new model. Note that the weights of only the attached layers will be updated during model training.
The following project includes exploratory data analysis and a model for the classification of disaster and non-disaster tweets. The code is stored in Jupiter notebook format and can be run directly in Google Collab notebook. All important steps are explained within the notebook.
The first part of the code incorporates a graphical representation and overview of the features of each of the columns of the dataset. First, the overview of the dataset and the number of missing data for each column is given. As a result of the analysis the first three columns, particularly 'id', 'location' and 'keyword', were deleted because they could not sufficiently contribute to the classification. The analysis then focuses on the 'text' column which is the most important part of the dataset. Each of the key features is discussed and the possible cleaning is suggested. The dataset before and after cleaning is plotted to ensure that the dataset has been cleaned correctly and that no other cleaning is necessary.
As a result of the EDA, a number of cleaning operations were conducted. Particularly the punctuation, brackets, URL addresses, newline characters and other unnecessary features were deleted. The purpose was to minimise the number of features that do not add meaning to the text, to maximize the learning rate, minimize bias and ultimately to increase the potential accuracy of the model. Considering the transformer model used (see Bert in "Transfer Learning"), the model can find meaning in the punctuation, which could potentially increase the accuracy. This is the case only under the condition that the punctuation is made correctly throughout the dataset, which is not the case for the Twitter disaster dataset. A considerable number of words include punctuation and there are a number of abbreviations that include numbers and punctuation. This would possibly confuse the model. For that reason, the aforementioned features of the text were deleted.
The text was also transformed to lower-case so that the Bert-large-uncased transformer model (see Bert in "Transfer Learning") could be used.
Transfer learning is a technique that incorporates the use of the deep learning model with complex architecture that is general enough to be used on similar classification or regression tasks. Such a model is generally trained on a large dataset and it is therefore called to be pre-trained. For such a model so-called fine-tuning is necessary to train part of the model and the whole Artificial neural networks (ANN) structure for the given task. Particularly, Bert transformer model was used in this project during transfer learning.
Bert (Bidirectional Encoder Representations from Transformers) was developed by Jacob Devlin et al (arXiv:1810.04805 [cs.CL])at Google. It was pre-trained on a large corpus of unlabelled data including Book Corpus and the entire Wikipedia and as a novel model it achieves state-of-the-art performance for many NLP tasks.
Transfer learning enabled the project to achieve state-of-the-art accuracies even with limited resources and processing power.
Due to the complexity of natural language processing (NLP) of this task, a pre-trained transformer-based NLP model was implemented in order to minimize the processing power needed for the training and to make the model architecture simpler. Unlike sequential RNN which can also be used for NLP, the transformer is a transduction model that relies entirely on self-attention. It was first published in "Attention Is All You Need" in 2017 ( arXiv:1810.04805 [cs.CL]) and It enables a much better prediction of consecutive text based on its meaning. It was therefore an ideal candidate for this project. In general, there are several other advantages in comparison with the sequential RNN model. Transformer models take an entire sequence of tokens as input rather than token by token which enables a training boost by GPU. It is also capable of much better performance for unsupervised learning i.e. without the labelled data. This is, however, not the case of this project where the data are labelled.
We decided to implement Bert-large-uncased from transformer library huggingface because of its state-of-the-art performance in NLP tasks without having the burden of GPT-3's large size due to 175 Billion params. The first versions of the model were tested on Bert-base-uncased to make the training faster and to get the general idea of the performance of different implementations of our ANN model.
A final NN is a result of extensive testing of different architectures and fine-tuning methods. Particularly freezing the whole Bert model, completely unfreezing the Bert and training were tested. Each of the mentioned fine-tuning techniques was tested with a different number of layers on top of the Bert model. The pure Bert based classifier without NN layers outside Bert was also tested to ensure that we actually choose the best architecture for the task. Each of the architectures was tested with different settings of parameters such as learning rate or a number of dropout layers that could potentially increase the validation accuracy of the overall model.
- https://jalammar.github.io
- https://www.analyticsvidhya.com/blog/2020/07/transfer-learning-for-nlp-fine-tuning-bert-for-text-classification/
- https://towardsdatascience.com/working-with-hugging-face-transformers-and-tf-2-0-89bf35e3555a
- https://medium.com/analytics-vidhya/create-a-tokenizer-and-train-a-huggingface-roberta-model-from-scratch-f3ed1138180c
- https://towardsdatascience.com/transformers-retraining-roberta-base-using-the-roberta-mlm-procedure-7422160d5764