- Demo
- Overview
- Project Goal
- Technical Aspects
- Installation
- Feature Request
- Used Technologies
- Appendix
- FAQ
- Author
- License
- Feedback
• Link for web application : https://trafficvolume-predictor.anvil.app/
• Overview of web application :
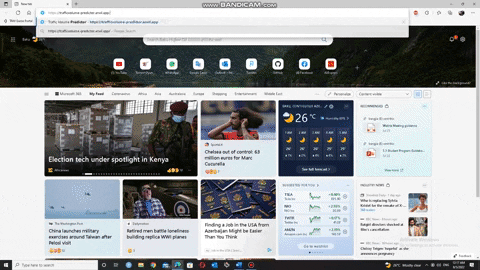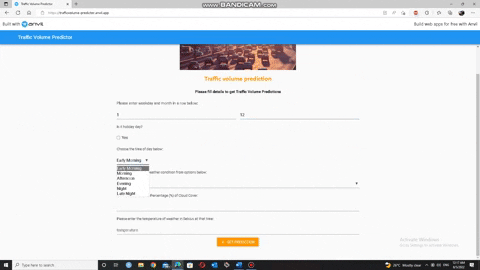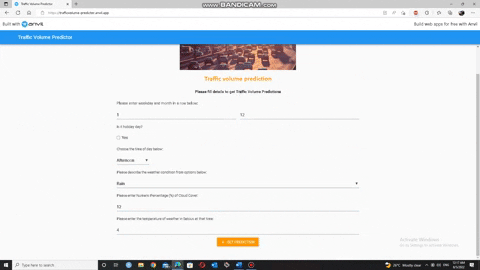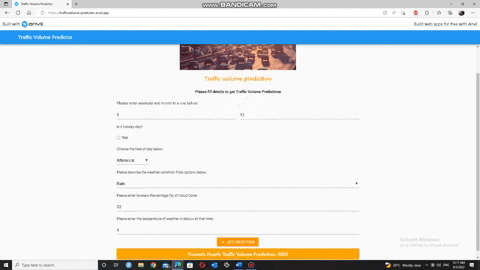
𝐍𝐨𝐭𝐞: 𝐖𝐞𝐛 𝐚𝐩𝐩𝐥𝐢𝐜𝐚𝐭𝐢𝐨𝐧 𝐰𝐨𝐫𝐤𝐬 𝟐𝟒/𝟕.
Nowadays, traffic is a major issue for everyone, and it is a source of stress for anyone who has to deal with it on a daily life. The growth of the population delays traffic and makes it worse day by day.
The goal of this project is to build a prediction model using multiple machine learning techniques and to use a template to document the end-to-end stages. We're trying to forecast the value of a continuous variable with the Metro Interstate Traffic Volume dataset, which is a regression issue.
The dataset contains about 48k records and 9 features which after all the implementation of all standard techniques like Data Cleaning, Feature Engineering, Feature Selection, Outlier Treatment, etc was feeded to our Classifier which after training and testing, was deployed in the form of a web application.
This complete project is made as a part of Data Science Internship at iNeuron.ai.
The whole project has been divided into three parts. These are listed as follows :
• 𝐃𝐚𝐭𝐚 𝐏𝐫𝐞𝐩𝐚𝐫𝐚𝐭𝐢𝐨𝐧 : This consists of storing our data into cassandra database and utilizing it, Data Cleaning, Feature Engineering, Feature Selection, EDA, etc.
• 𝐌𝐨𝐝𝐞𝐥 𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐦𝐞𝐧𝐭 : In this step, we use the resultant data after the implementation of the previous step to cross validate our Machine Learning model and perform Hyperparameter optimization based on various performance metrics in order to make our model predict as accurate results as possible.
• 𝐌𝐨𝐝𝐞𝐥 𝐃𝐞𝐩𝐥𝐨𝐲𝐦𝐞𝐧𝐭 : This step include creation of a front-end using Anvil, Flask and Heroku to put our trained model into production.
The Code is written in Python 3.8.8. If you don't have Python installed you can find it here. If you are using a lower version of Python you can upgrade using the pip package, ensuring you have the latest version of pip. To install the required packages and libraries, run this command in the project directory after cloning the repository:
pip install -r requirements.txtRun on your Local Machine :
python server.pyThis will start the run the server.py which will also trigger code for server_app.py because of the use of asynchronous execution (threading) and will connect our ML model to Anvil application UI and will keep the server running till the web page rendered by flask application gets closed but to keep the server running forever, we used the heroku cloud to run our server continuously.
If you find a bug (the website couldn't handle the query and / or gave undesired results), kindly email me (muhammad.ojagzada.std@bhos.edu.az) by including your search query and the expected result.
If you'd like to request a new function, feel free to do so by opening an issue here. Please include sample queries and their corresponding results.

Link for video regarding to the explanation of the project :
https://drive.google.com/file/d/1PkUzDJSgya7YWwuW7OVA7Rc0CnZ9oEJ5/view
Link for App Documentation :
https://github.com/mahammadodj/iNeuron-Internship-Project/tree/master/Documents
John Hogue, john.d.hogue '@' live.com, Social Data Science & General Mills
Dataset link : https://archive.ics.uci.edu/ml/datasets/Metro+Interstate+Traffic+Volume
- Removing unwanted attributes
- Visualizing relation of independent variables with each other and output variables
- Checking and changing Distribution of continuous values
- Removing outliers
- Cleaning data and imputing if null values are present.
- Converting categorical data into numeric values.
- Scaling the data
Data pipeline was created to implement data scaling, one-hot encoding and an estimator to prevent any data leakage. CatBoost model was used as the best estimator which was then used for production followed by hyperparameter tuning.
- When the pipeline is ready, we connected the front-end made on Anvil with the backend code having the pipeline on the local machine via anvil uplink.
- A server is created in Flask which just displays a single web page and runs the uplink code via threading thereby creating a server.
- The Flask page was then deployed to Heroku cloud.
- A cron job was set on the Heroku platform to load the flask app every 30 minutes to keep the uplink connected and running the uplink code forever.
Copyright 2022 Mahammad Ojagzada
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
If you have any feedback, please reach out to me at muhammad.ojagzada.std@bhos.edu.az.