Project Page: PLLaVA
DemoVideo.mp4
Welcome to PLLAVA!
The primary purpose of this repository is to support research and the development of prototype models. It is designed to facilitate ease of experimentation and enable a clear overview of results. Please note that this repo is currently undergoing development and reconstruction.
It's important to mention that we have not optimized the response speed of the application or the frontend logic. Our goal is to maintain simplicity, clarity, and ease of development, making it accessible for both researchers and students. If you have suggestions or want to enhance the application's performance, please feel free to contact us or contribute to the project.
We've briefly introduce our work in section PLLAVA. For more details, feel free to read our paper. Check out section Usage to start using this repo. If you felt our works interesting, please star us, your support is all we want. If you find our work helpful, feel free to cite us directly.
- 2024/4/24: Release:
- We are releasing our code/models/datasets.
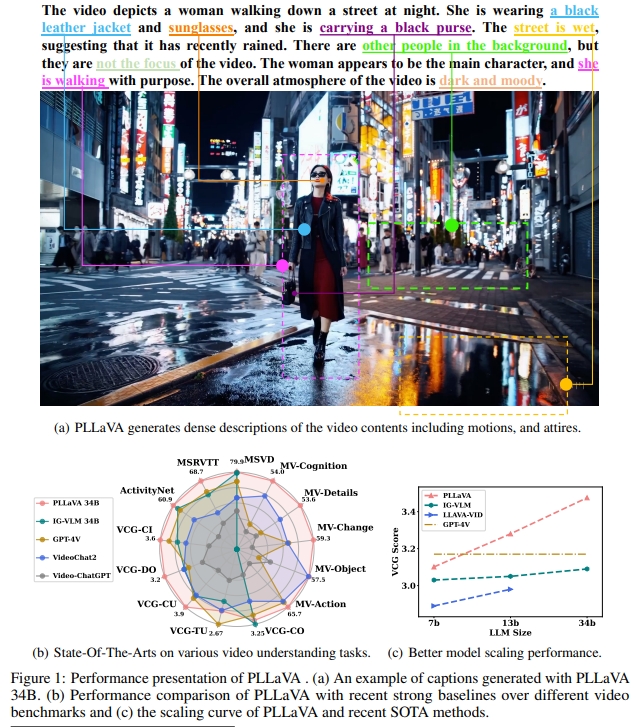
Vision-language pre-training (VLP) has significantly elevated performance across a range of vision-language applications. Yet, the pre-training process for video-related tasks demands an exceptionally high degree of computational and data resources. This paper investigates a straightforward, highly efficient, and resource-light approach to adapting an existing image-language pre-training model for video data. Our preliminary experiments reveal that directly fine-tuning pre-trained image-language models with multiple frames on video datasets leads to performance saturation or even a drop in caption-related tasks. Besides, it is also vulnerable to prompts and tends to provide short descriptions. We conducted a deep analysis and observed that the performance saturation and the vulnerability might be related to the dominant patches that exist in some single video patches. We then propose a simple pooling strategy to smooth the feature distribution along the temporal dimension and thus reduce the dominant impacts from some extreme tokens. The new model is termed Pooling LLaVA, or PLLaVA in short. With the proposed pooling strategy, we achieve new state-of-the-art performance on all evaluated datasets. Notably, on the recent popular Video ChatGPT benchmark, PLLaVA achieves a score of 3.48 out of 5 on average of five evaluated dimensions, which is the new state-of-the-art score on the leaderboard and is 0.31 higher than the previous SOTA results from GPT4V (IG-VLM). On the latest multi-choice benchmark MVBench, PLLaVA achieves 58.1% accuracy on average across 20 sub-tasks, which is the new state-of-the-art result and is 14.5% higher than GPT4V (IG-VLM).

There are two dimensions for the pooling strategy: the spatial dimension and the temporal dimension. We empirically found that reducing the spatial dimension with a larger temporal dimension could lead to better model performance, compared to reducing the temporal dimension directly.

We compare the performance of PLLAVA with recent popular methods over both question-answer and captioning datasets. The results are shown below.

This section provides guidance on how to run, train, and evaluate our models.
First, you will need to set up the environment and download some pre-trained weights.
This repo is built up using transformers for model construction along with accelerate for distributed training. Follow the instructions to install the needed environment.
- Above all, the following environment set up is for python 3.10. If you choose to use conda for environment setup, we recommend creating the virtual environment with:
conda create -n pllava python=3.10- Firstly, install pytorch from the official website. The code runs on torch 2.2.1, cu118 or cu122. Select the version that suits your drive version.
torch 2.2.1+cu118
torchaudio 2.2.1+cu118
torchvision 0.17.1+cu118
If your driver version is higher than cu121, you could probably try installing with the following scripts:
pip install -r requirements.txtOtherwise, you would need to install a torch for your server first, then install the other packages:
pip install -r requirements.torch.txt # decide your own requirements, (this is for cu11), or install torch directly following the official website.
pip install -r requirements.no_torch.txt # install the following- Prepare the model. We prefer to have huggingface models explicitly downloaded to a MODELS directory. However, if you are familiar with huggingface-hub usage, feel free to organize the model yourself.
python python_scripts/hf.py
Here are some detailed information of the obtained models:
| Model | Link | Initialized From |
|---|---|---|
| pllava-7b |  |
llava-hf/llava-v1.6-vicuna-7b-hf · Hugging Face |
| pllava-13b | |
llava-hf/llava-v1.6-vicuna-13b-hf · Hugging Face |
| pllava-34b | |
llava-hf/llava-v1.6-34b-hf · Hugging Face |
The model directory should look like this, where you would only need the corresponding model's weights and directory.
$ tree MODELS
MODELS
|-- pllava-13b
| |-- added_tokens.json
| |-- config.json
| |-- generation_config.json
| |-- model-00001-of-00006.safetensors
| |-- model-00002-of-00006.safetensors
| |-- model-00003-of-00006.safetensors
| |-- model-00004-of-00006.safetensors
| |-- model-00005-of-00006.safetensors
| |-- model-00006-of-00006.safetensors
| |-- model.safetensors.index.json
| |-- preprocessor_config.json
| |-- processor_config.json
| |-- special_tokens_map.json
| |-- tokenizer.json
| |-- tokenizer.model
| `-- tokenizer_config.json
|-- pllava-34b
| |-- added_tokens.json
| |-- config.json
| |-- generation_config.json
| |-- model-00001-of-00015.safetensors
| |-- model-00002-of-00015.safetensors
| |-- model-00003-of-00015.safetensors
| |-- model-00004-of-00015.safetensors
| |-- model-00005-of-00015.safetensors
| |-- model-00006-of-00015.safetensors
| |-- model-00007-of-00015.safetensors
| |-- model-00008-of-00015.safetensors
| |-- model-00009-of-00015.safetensors
| |-- model-00010-of-00015.safetensors
| |-- model-00011-of-00015.safetensors
| |-- model-00012-of-00015.safetensors
| |-- model-00013-of-00015.safetensors
| |-- model-00014-of-00015.safetensors
| |-- model-00015-of-00015.safetensors
| |-- model.safetensors-deprecated
| |-- model.safetensors.index.json
| |-- preprocessor_config.json
| |-- processor_config.json
| |-- special_tokens_map.json
| |-- tokenizer.json
| |-- tokenizer.model
| `-- tokenizer_config.json
|-- pllava-7b
|-- added_tokens.json
|-- config.json
|-- generation_config.json
|-- model-00001-of-00003.safetensors
|-- model-00002-of-00003.safetensors
|-- model-00003-of-00003.safetensors
|-- model.safetensors.index.json
|-- preprocessor_config.json
|-- processor_config.json
|-- special_tokens_map.json
|-- tokenizer.json
|-- tokenizer.model
`-- tokenizer_config.json
With the above steps, you should be able to proceed on with the following usages.
To run our models, make sure you have downloaded a model pretrained weights from the huggingface spaces. Then, run the following scripts with the corresponding path input. Since we are only training with lora and the projector, the model to be run are determined with:
- model_dir: model directory, one with config.json as compatible with transformers. This refers to the base model's directory, for example "llava-hf/llava-v1.6-vicuna-7b-hf"/"ermu2001/pllava-7b"/"MODELS/pllava-7b". (default to: MODELS/plave-7b)
- weights_dir: your weights directory. could be the same as model_dir, but if you have a weights directory for the lora weights, you should set this weights_dir to that directory to load the lora weights. This directory should be local. Also, it would need to contain a config.json file within. (default to: ${model_dir}).
model_dir="model directory"
weights_dir="weights directory"
bash scripts/demo.sh ${model_dir} ${weights_dir}Now check out the application demo and try play with PLLAVA!
Follow the following steps to reproduce our results or train your own variant:
To train our model from a starting Image-aligned Vision LLM, you would need to download the data first. Our data set up is mainly based on the original Videochat2's training data. Check out Instruction Data to prepare the instruction training data. Ideally, setting up a root data directory and alter the code here would accomodate the data for training most smoothly.
Now you're only a few step away from starting the training. Follow the instructions:
Customize a accelerate training config. For example, a simple config using multiple gpus with no distribution strategy (only torch DDP) would look like:
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: falseCheck out out the Accelerate documents for more details.
Next, you should go over a basic training configuration of the training process in here. Then passing this file as the first arg to the training script would utilize every arguments in the file. You can customize some of the hyper parameters for your own training process by passing them in the format of "key" "value" pair in the following arguments. A example training scripts could be find here.
We recommand customize a configuration to set up a customized training!
With the above steps, you would be able to start the training process. The output would be well organized in the output directory, each a qualified model directory to pass in to demo as weights_dir, since we are only saveing the lora weights and projector weights to avoide redundancy.
This section mainly introduce how to reproduce the evaluation or evaluate your own model.
Make sure you set up the "DATAS" directory as in DATA.md, then you would be able to run the inference with fortune! The evaluation data directory of DATAS would look like:
DATAS/:
DATAS/VideoQA:
DATAS/VideoQA/TGIF_QA:
test_a.json
test_q.json
DATAS/VideoQA/TGIF_QA/videos:
tumblr_m4387mGrlc1r6m5e8o1_250.gif
...
DATAS/VideoQA/TGIF_QA/videos_mp4:
tumblr_m4387mGrlc1r6m5e8o1_250.mp4
...
DATAS/VideoQA/TGIF_QA/video_gif:
tumblr_m4387mGrlc1r6m5e8o1_250.gif
...
DATAS/VideoQA/MSVD_Zero_Shot_QA:
test_a.json
test_q.json
DATAS/VideoQA/MSVD_Zero_Shot_QA/videos:
-4wsuPCjDBc_5_15.avi
DATAS/VideoQA/MSVD_Zero_Shot_QA/msvd_qa:
DATAS/VideoQA/ActivityNet:
test_a.json
test_q.json
DATAS/VideoQA/ActivityNet/all_test:
v_--tFD65KaK4.mp4
...
DATAS/VideoQA/MSRVTT_Zero_Shot_QA:
test_a.json
test_q.json
DATAS/VideoQA/MSRVTT_Zero_Shot_QA/videos:
DATAS/VideoQA/MSRVTT_Zero_Shot_QA/videos/all:
video0.mp4
...
DATAS/MVBench:
...
DATAS/Recaption/Inter4K:
annotations.json
DATAS/Recaption/Inter4K/60fps:
DATAS/Recaption/Inter4K/60fps/UHD:
1.mp4
...
Once you have construted the evaluation data, you can start the evaluation as in here. This script is for evaluating 7B/13B models. As pllava-34b model uses a slightly different prompting, it is evaluated with this script.
bash scripts/eval.sh
Same as running the demo, you would need to determine the model_dir and weights_dir to evaluate the model. Feel free to comment out some commands and produce partial evaluation.
The evaluation results would be shown to you with our results gallery demo:
bash scripts/gallery.sh Feel free to use the compare version to compare differnt models' results or use the single gallery version to check out one model's results. They are basically the same. Check out this script for more details
Follow instructions at DATA.md and you can extend the recaptioning data with a few steps.
Feel free to point out high quality dataset of videos, we would proceed on doing captioning on those datasets.
If you find this project useful in your research, please consider cite:
@misc{xu2024pllava,
title={PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning},
author={Lin Xu and Yilin Zhao and Daquan Zhou and Zhijie Lin and See Kiong Ng and Jiashi Feng},
year={2024},
eprint={2404.16994},
archivePrefix={arXiv},
primaryClass={cs.CV}
}This code base is mainly built upon Videochat2. SALUTE.
We would also like to recognize and commend the following open source projects, thank you for your great contribution to the open source community:
- LLaVA: Fantastic Open Source Image LLM Model.
- VideoChatGPT: Great Evaluation Benchmarking Framework.
- VideoLlava:Video LLM repo with helpful resources.