pbSGD
Powered Stochastic Gradient Descent Methods for Accelerated Nonconvex Optimization
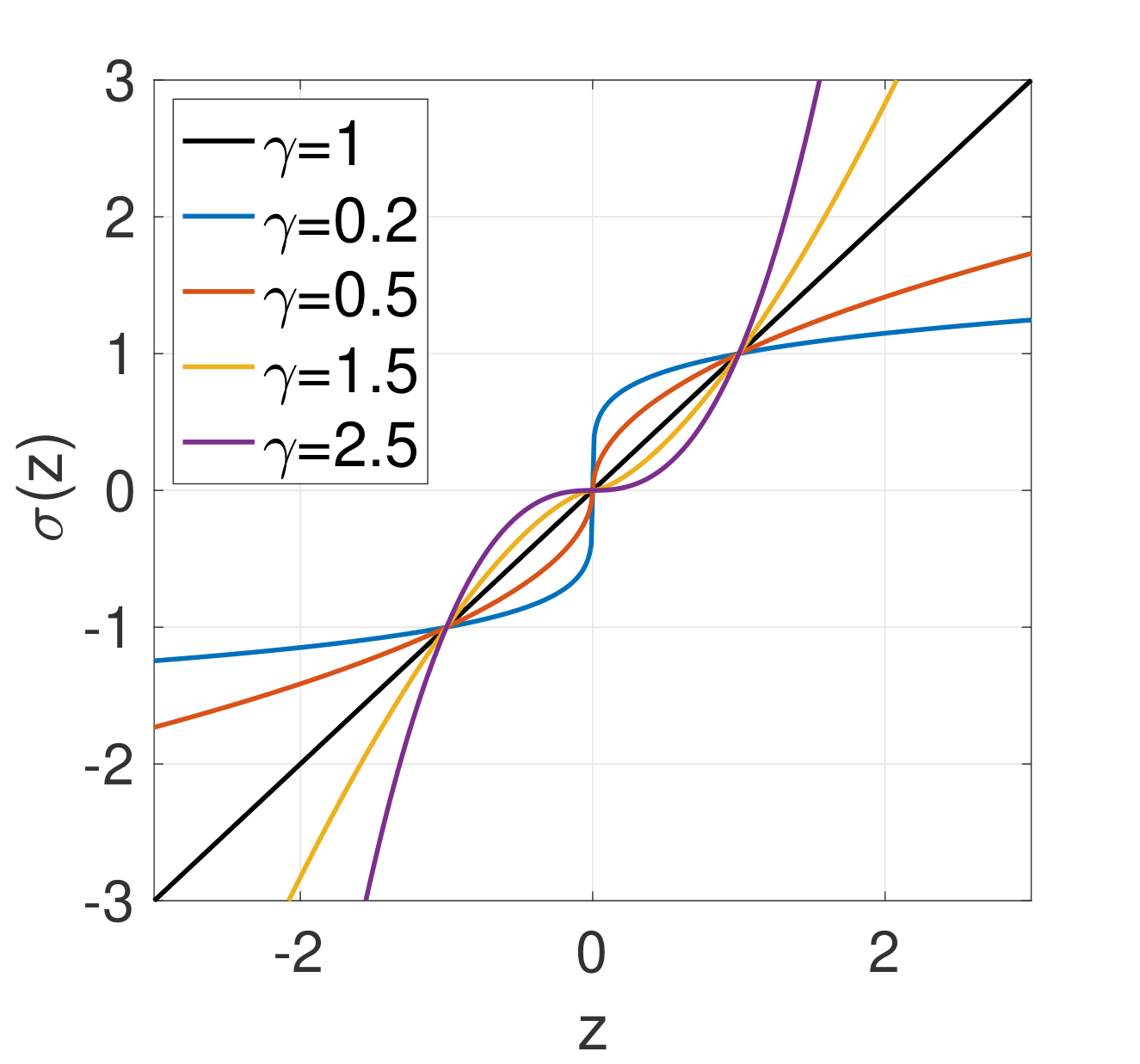
Introduction
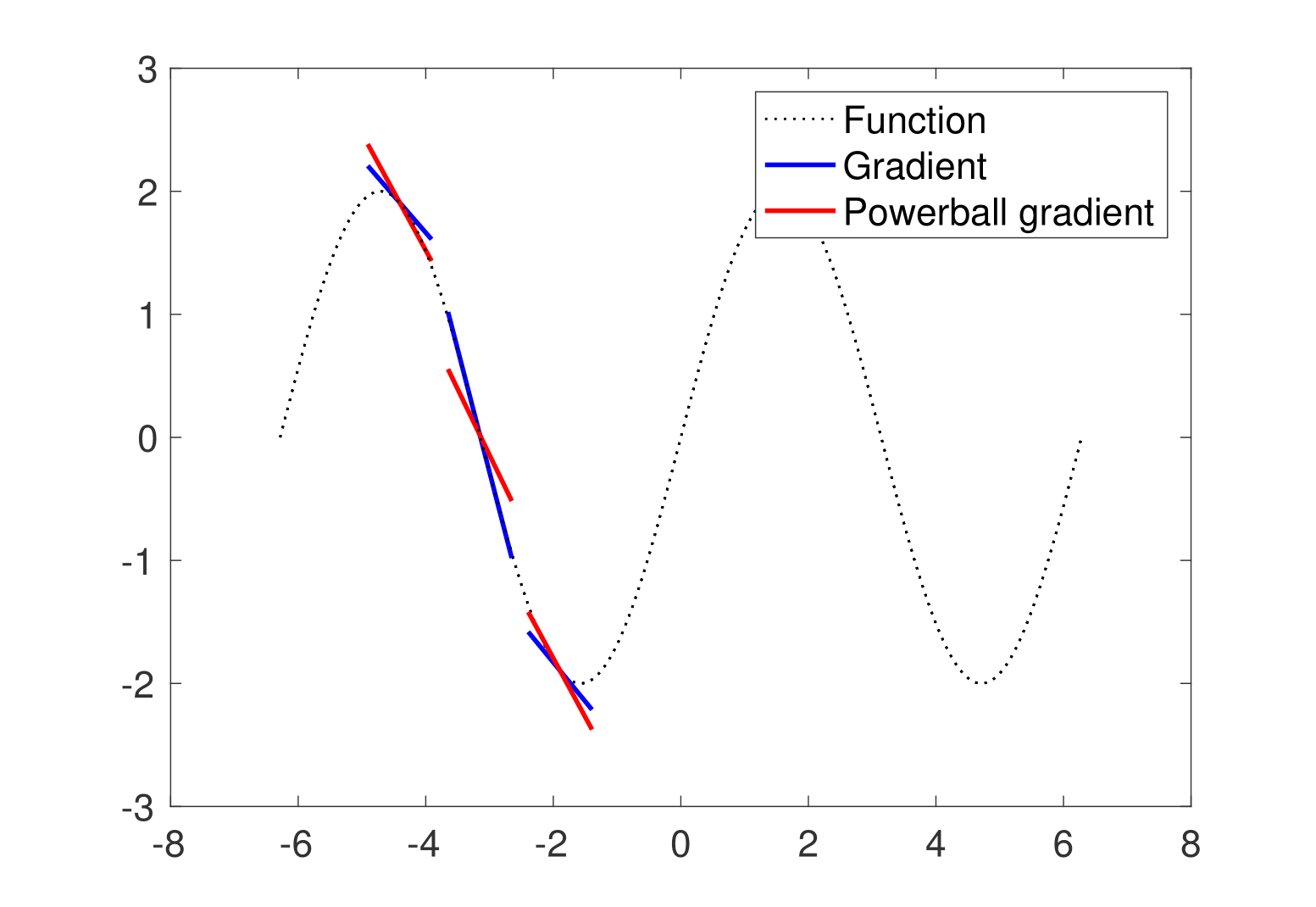
We propose a novel technique for improving the stochastic gradient descent (SGD) mthod to train deep networks, which we term pbSGD. The proposed pbSGD method simply raises the stochastic gradient to a certain power
This nonlinear transform function improving the convergence of SGD is orthogonal and complementary to other techniques for accelerating gradient-based optimization methods such as learning rate schedules.
Installation
pbSGD requires Python >= 3.6.0 and torch >= 0.4.0. The torch version is currently provided in this repository.
We're supporting pbSGD installation via pip. You can just run
pip install pbSGDin your terminal and install pbSGD into your python environment. On the other hand, as pbSGD is modified based on SGD implementation, you can also copy the file into your own project and simply import it.
Examples
We provide demos including experiments on CIFAR-10 and CIFAR-100 to reproduce the results in our work.
Contributions
The CIFAR-10 and CIFAR-10 demo code are borrowed from pytorch-cifar and pytorch-cifar-models respectively.