关键词式指定站点新闻爬虫
- 基于Scrapy框架
- 谷歌高级搜索(爬取新闻链接)
- 关键词、站点自定义
- 新闻页面解析(已包含人民日报、纽约时报、东方新闻、星岛新闻页面解析)
- MySQL存储
- 可拓展
- 主体为Scrapy工程目录结构
utils目录下包括繁简转换插件,原项目地址analysis目录下为一些简单的数据分析代码,包括分词、词频统计等。spiders下包括谷歌搜索、人民日报、纽约时报、东方新闻、星岛新闻爬虫
-
修改
settings.py中关于数据库的配置项MYSQL_HOST = '127.0.0.1' # 数据库地址 MYSQL_DBNAME = 'job_news' # 数据库名称 MYSQL_USER = 'root' # 数据库账号 MYSQL_PASSWD = '123456' # 数据库密码 MYSQL_PORT = 3306
-
启动谷歌搜索爬虫
scrapy crawl google -a kw=关键词 -a site=站点网址
-
启动新闻站点爬虫
scrapy crawl 爬虫名
- 新闻目录

- 新闻内容

- 词云

- 词频
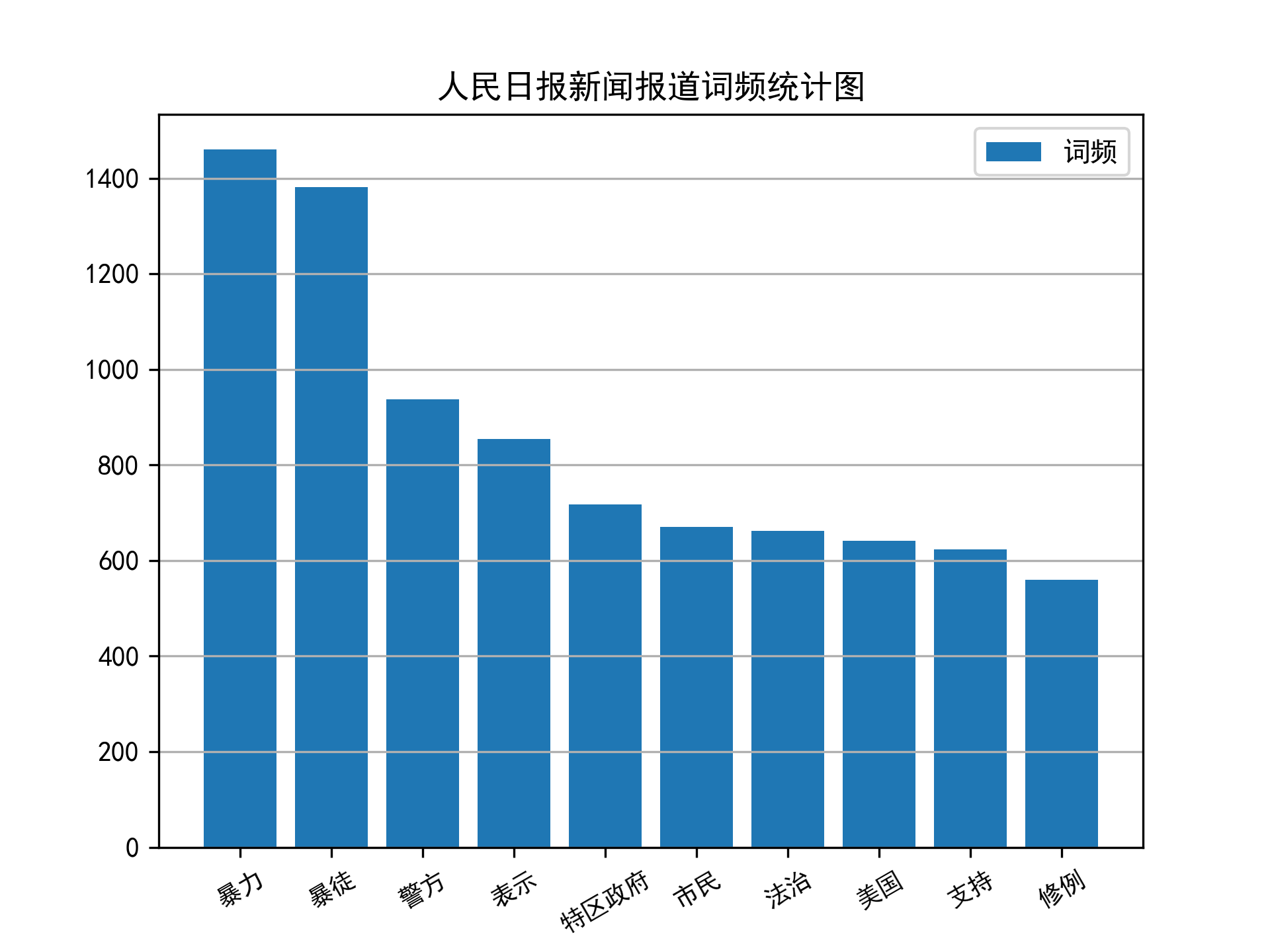
-
新增新闻站点爬虫
在项目根目录执行:
scrapy genspider example example.com
仿照
peopleNews.py修改即可。