Fake News are becoming increasingly popular, while many of them are manually written to spread false content, others are automated. to disseminate false content, others are automated. Understanding how they are generated, makes it easier to identify them. Therefore, performing each of the the different stages that are involved in this task. In this way, it is required to download a number n of headlines from a news portal such as BBC World, using web-scrapping techniques. This information must be stored in an autogenerated .csv file. .csv file auto-generated by the program, containing the date of the news item and the headline, and any other data, if necessary. Likewise, with the collected data you must generate your own fake headline using own fake headline using Markov Chains. Finally, return graphs that allow you to perform an analysis. analysis of the collected information:
-
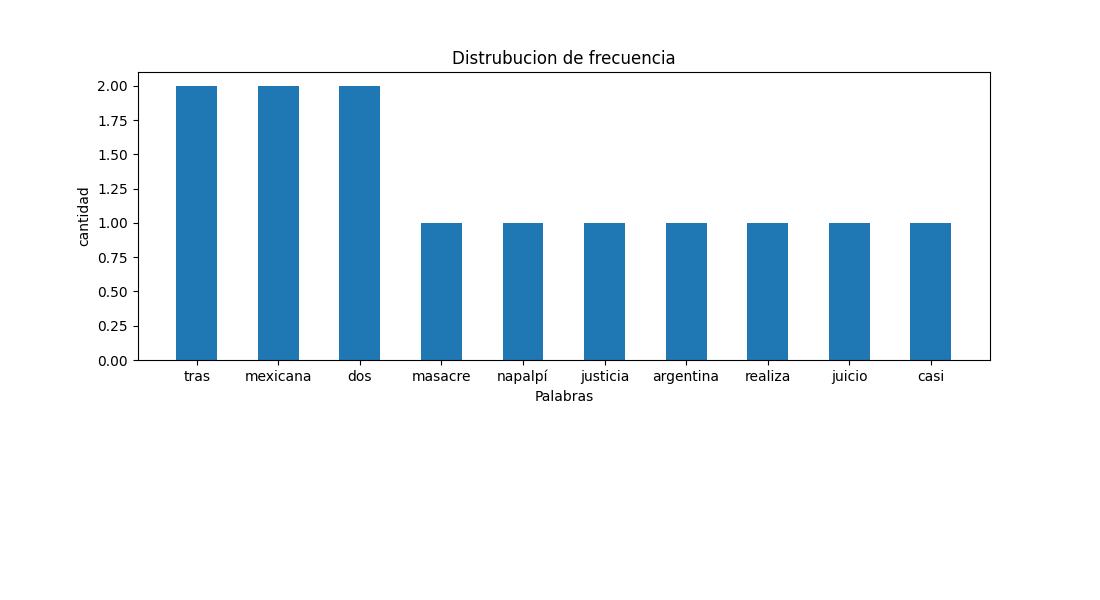
Frequency distribution of the words used in all statements. Take into account a previous Consider a previous stage of data cleaning to avoid stop-words.
-
Most used word by date of publication of the news item. You can choose the type of graphic that you consider more convenient.
-
Number of articles published by date.
-
Cloud of most used words.
-
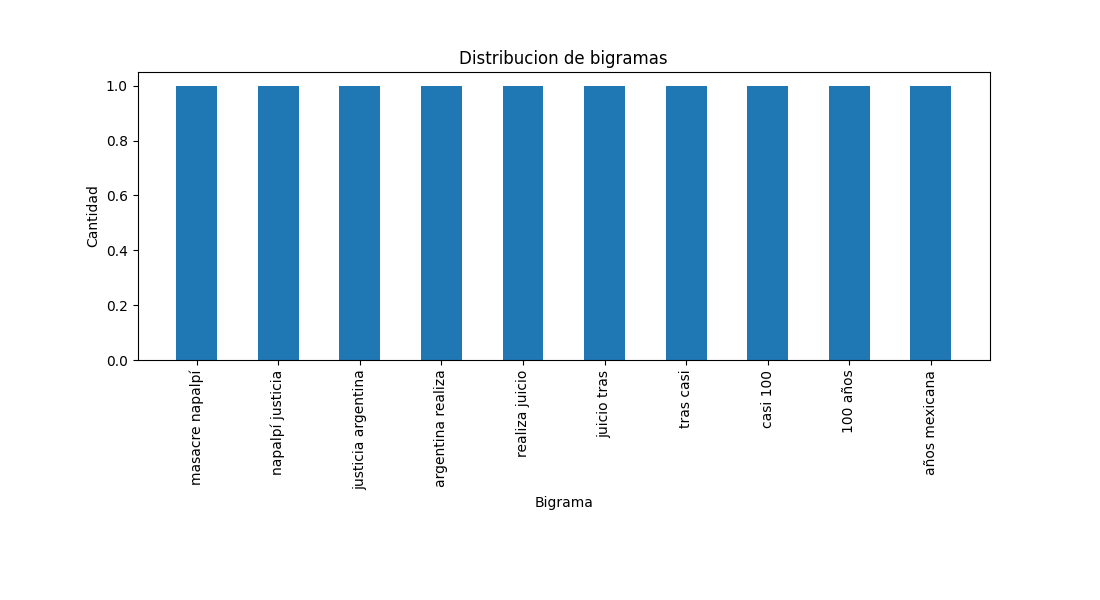
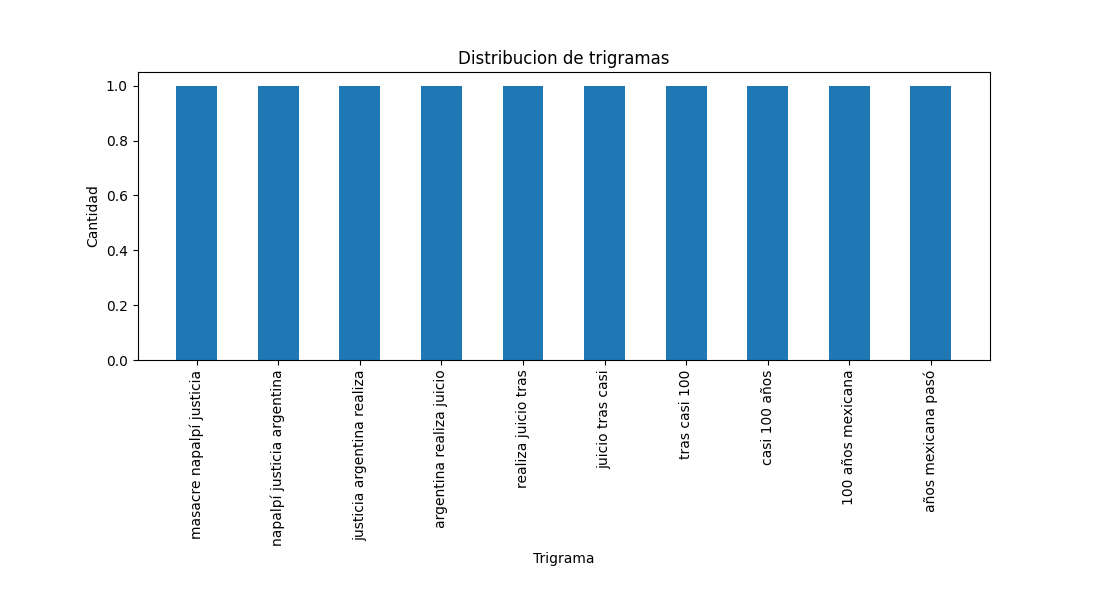
Distribution of the 10 most frequent bigraphs and trigrams.
Generate 30 random headlines, based on the information collected, and observe if the results hold when the analysis is performed again. the results hold when performing the above analysis again. The results and conclusions obtained should be included in the report.
You must have python installed, and type the following command.
$ pip install -r requirements.txtTo deploy the programm, run the main file, this can be done by executing the following command.
python web_scrapping.pyProgramm: Python, Pandas, Numpy, Matplotlib
When we run our program, we can see that it compiles the data from the BBC website and then generates the following results the BBC website and then generates the following results:
- The cloud of most used words:

- Frequency distribution of the most frequent words:
- Frequency distribution of the most frequent bigrams:
- Frequency distribution of the most frequent trigrams:
When looking at the fake headlines generated by our program and comparing them with the original headlines, we realize that even though some of the generated headlines lack we realize that even though some of the headlines generated are meaningless, we realize that some of them are we realize that some of them are even coherent, for example "AMLO The most promising political effect of how the president emerged". This is because the headlines are generated by Markov chains, which means that they are made up of random but related words, which are This is because, in order to add a successor word in a Markov chain, it must have the same multiplicity as the successor word in a Markov chain, and the successor word must have the same multiplicity as the successor word, the last word added as a predecessor in the headline dataset obtained from the Internet. obtained from the Internet; therefore, by pure probability, when concatenating related words There is the possibility that a coherent word is generated (as the search engine does). the Google search engine). On the other hand, when performing the analysis of the frequency distribution of the words in the headlines, there is the possibility of generating one that has coherence (as the Google search engine does). of the frequency of the words in the random headlines, we observe that the most used words are almost the same as those in the used are almost the same as in the compiled headlines, and we could also observe that the frequency distributions of the words used in the random headlines are almost the same as in the compiled headlines. that the distributions of the most used bigrams and trigrams are quite different if we compare the compiled the compiled headlines and the randomly generated headlines.
For support, email licerol@uninorte.edu.co