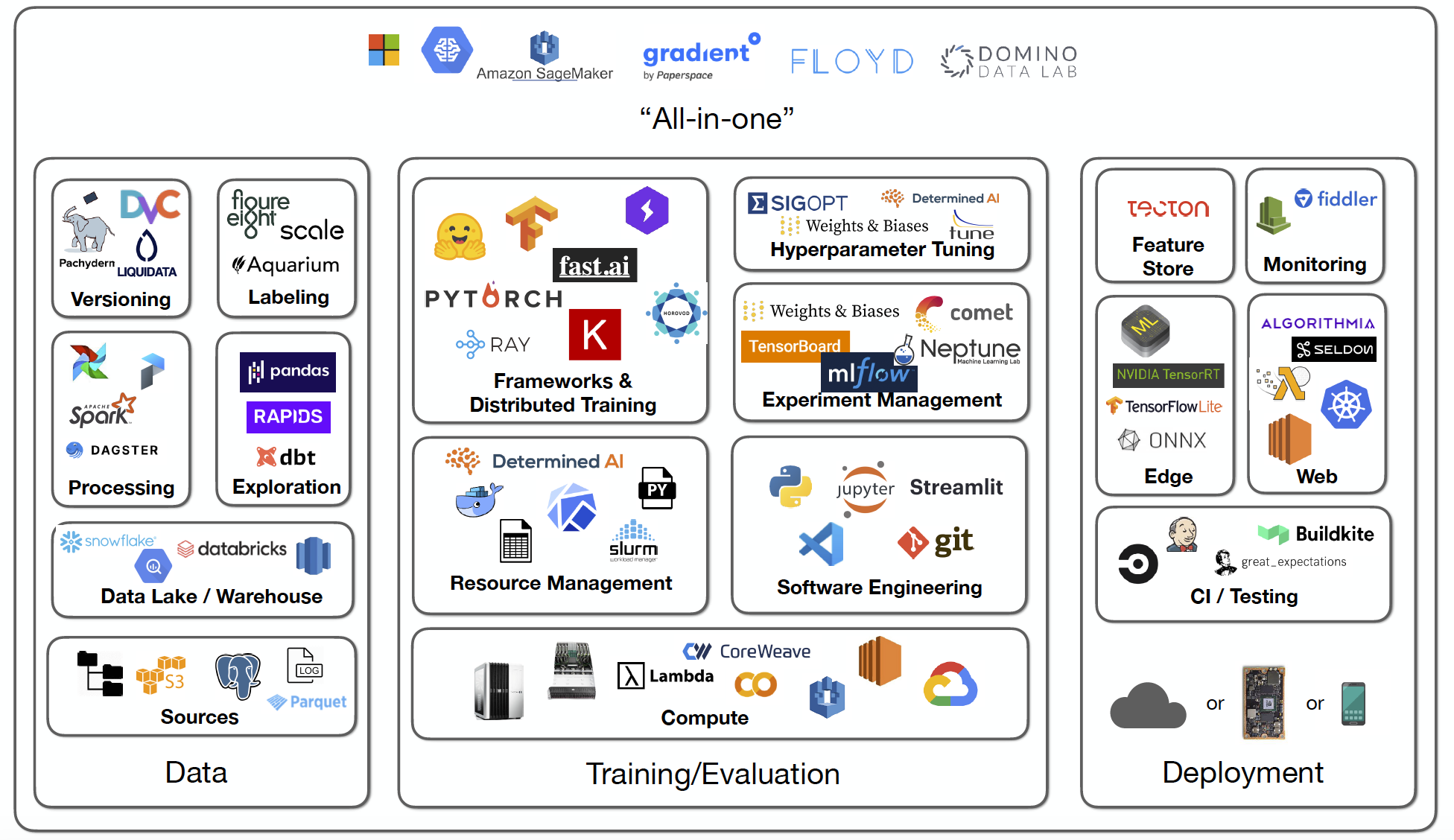
In short for Machine Learning Operations, is a set of practices and methodologies that aim to streamline the deployment, management, and maintenance of machine learning models in production environments. It brings together the principles of DevOps (Development Operations) and applies them specifically to machine learning workflows. The MLOps lifecycle encompasses various stages and processes, ensuring the smooth integration of machine learning models into real-world applications.

Implementing MLOps practices is crucial for several reasons:
-
Reproducibility: MLOps ensures that the entire machine learning pipeline, from data preprocessing to model deployment, is reproducible. This means that the same results can be obtained consistently, facilitating debugging, testing, and collaboration among team members.
-
Scalability: MLOps allows for the seamless scaling of machine learning models across different environments and datasets. It enables efficient deployment and management of models, regardless of the volume of data or the complexity of the infrastructure.
-
Agility: MLOps promotes agility by enabling rapid experimentation, iteration, and deployment of models. It facilitates quick feedback loops, allowing data scientists and engineers to adapt and improve models based on real-world performance and user feedback.
-
Monitoring and Maintenance: MLOps ensures continuous monitoring of deployed models, tracking their performance and detecting anomalies. It enables proactive maintenance, including retraining models, updating dependencies, and addressing potential issues promptly.
-
Collaboration: MLOps fosters collaboration among data scientists, engineers, and other stakeholders involved in the machine learning workflow. It establishes standardized practices, tools, and documentation, enabling efficient communication and knowledge sharing.
.gif)
This project aims to implement the MLOps (Machine Learning Operations) lifecycle from scratch. The stages involved in the lifecycle include:
Set Project🐣
Set up your project environment and version control system for MLOps.
- Create a Python virtual environment to manage dependencies.
- Initialize Git and set up your GitHub repository for version control.
- Install DVC (Data Version Control) for efficient data versioning and storage.
- Install project dependencies using
requirements.txt. - Write utility scripts for logs, exception handling, and common utilities.
Exploratory Data Analysis📊
Perform EDA on your data to gain insights and understand statistical properties.
- Explore the data to understand its distribution and characteristics.
- Plot charts and graphs to visualize data patterns and relationships.
- Identify and handle outliers and missing data points.
Data Pipeline🚧
Create a data ingestion pipeline for data preparation and versioning.
- Write a data ingestion pipeline to split data into train and test sets.
- Store the processed data as artifacts for reproducibility.
- Implement data versioning using DVC for maintaining data integrity.
- Use the Faker library to generate synthetic data with noise for testing purposes.
Data Transformation🦾
Perform data transformation tasks to ensure data quality and consistency.
- Write a script for data transformation, including imputation and outlier detection.
- Handle class imbalances in the dataset.
- Implement One-Hot-Encoding and scaling for features.
Model Training🏋️
Train and tune multiple classification models and track experiments.
- Train and tune various classification models on the data.
- Use MLflow for experimentation and tracking model metrics.
- Log results in the form of JSON to track model performance.
Validation Pipeline✅
Create a Pydantic pipeline for data preprocessing and validation.
- Define a Pydantic data model to enforce data validation and types.
- Implement a pipeline for data preprocessing and validation.
- Verify the range of values and data types for data integrity.
Create a FastAPI⚡
Build a FastAPI to make predictions using your trained models.
- Develop a FastAPI application to serve predictions.
- Integrate the trained models with the FastAPI endpoint.
- Provide API documentation using Swagger UI.
Test the API⚗️
Conduct thorough testing of your FastAPI application.
- Use Pytest to test different components of the API.
- Test data types and handle missing input scenarios.
- Ensure the API responds correctly to various inputs.
Containerization and Orchestration🚢
Prepare your application for deployment using containers and orchestration.
- Build a Docker image for your FastAPI application.
- Push the Docker image to Azure Container Registry (ACR).
- Test the application locally using Minikube.
- Deploy the Docker image from ACR to Azure Kubernetes Service (AKS) for production.
CI/CD🔁
Set up a Continuous Integration and Continuous Deployment pipeline for your application.
- Configure CI/CD pipeline for automated build and testing.
- Deploy the application on Azure using CI/CD pipelines.
- Clone the repository:
git init
git clone https://github.com/karan842/mlops-best-practices.git- Create a virtual environment
python -m venv env- Install dependencies
pip install -r requirements.txt- Run the Flask App
python app.py- Run Data and Model pipeline (Enable MLFLOW)
mlflow ui
dvc init
dvc repro- Test the application
pytestTo make contribution in this project:
- Clone the repository.
- Fork the repository.
- Make changes.
- Create a Pull request.
- Also, publish an issue!
- Machine Learning in Production (DeepLearning.AI) - Coursera
- MLOps communities from Discord, Twitter, and LinkedIn
- Kubernetes, MLFlow, Pytest official documents
- Microsoft Learning
- ChatGPT and Bard