bigdata flow example

- kafka với single node
| name | option |
|---|---|
| KAFKA_LISTENER_SECURITY_PROTOCOL_MAP | INTERNAL, EXTERNAL_SAME_HOST, PLAINTEXT *(no auth) |
| KAFKA_LISTENERS | <protocol>://<host>:<port> EXTERNAL_SAME_HOST://:29092, EXTERNAL_DIFFERENT_HOST://:29093, INTERNAL://:9092 |
| KAFKA_ADVERTISED_LISTENERS | cái trên chỉ là cho broker thôi . muốn client(consummer, producer) kết nối được thì phai chỉ định cái này INTERNAL://kafka:9092, EXTERNAL_SAME_HOST://localhost:29092, EXTERNAL_DIFFERENT_HOST://157.245.80.232:29093 |

- sau khi compose up thì cần vô master bật hadoop. nếu là lần thứ 2 thì k cần format vì đã được map volume
docker exec -it hadoop-master bash
hadoop namenode -format
start-all.sh
- check jps trên master
root@47116eadca50:/# jps
1747 NameNode
2729 Jps
793 SecondaryNameNode
1067 ResourceManager
- check jps trên worker
docker exec -it hadoop-slave1 bash
root@32de54052105:~# jps
471 Jps
236 NodeManager
111 DataNode
-
check ui namenode tại :
http://localhost:9870/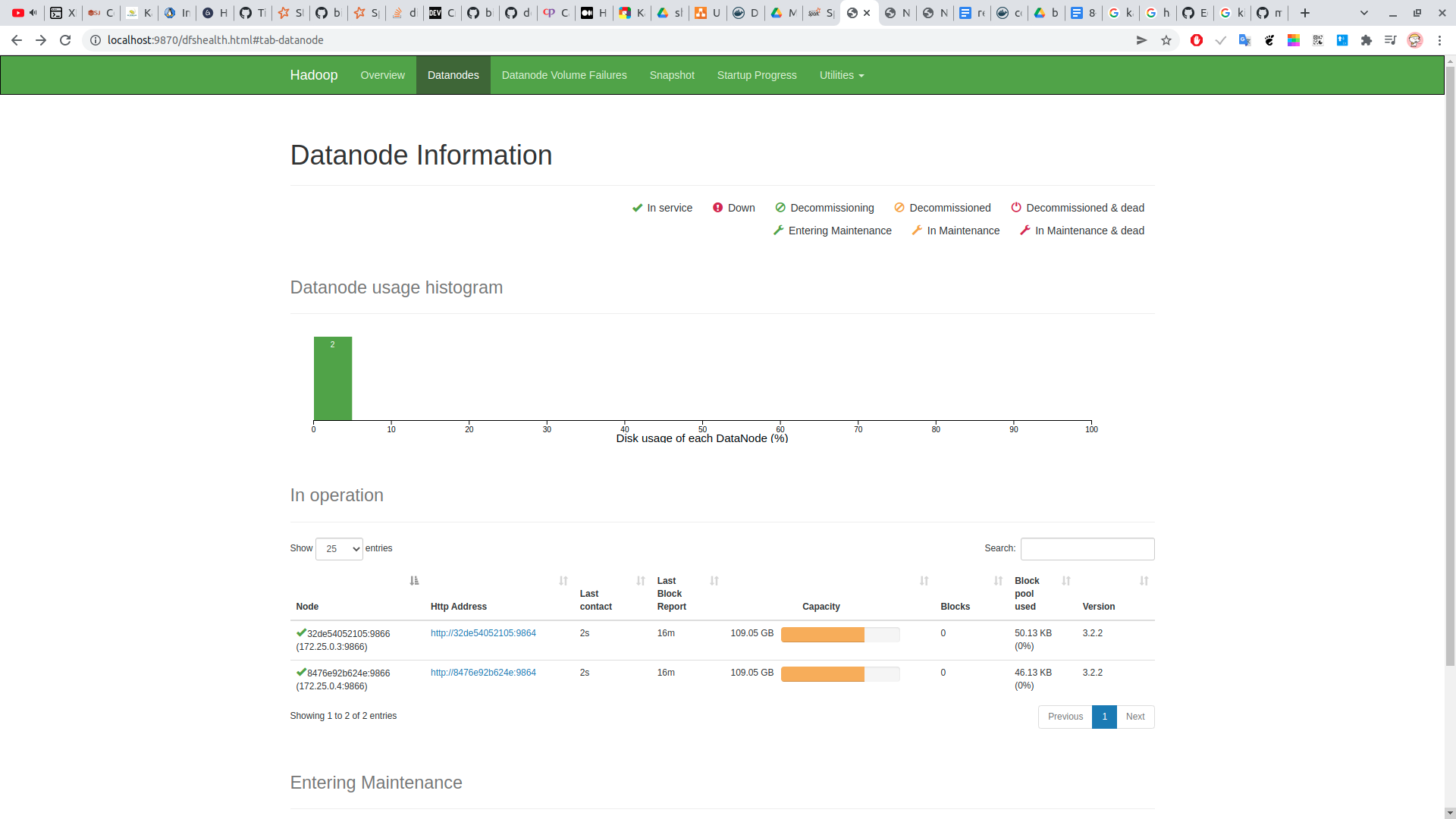
-
check ui data node tại:
http://localhost:9864/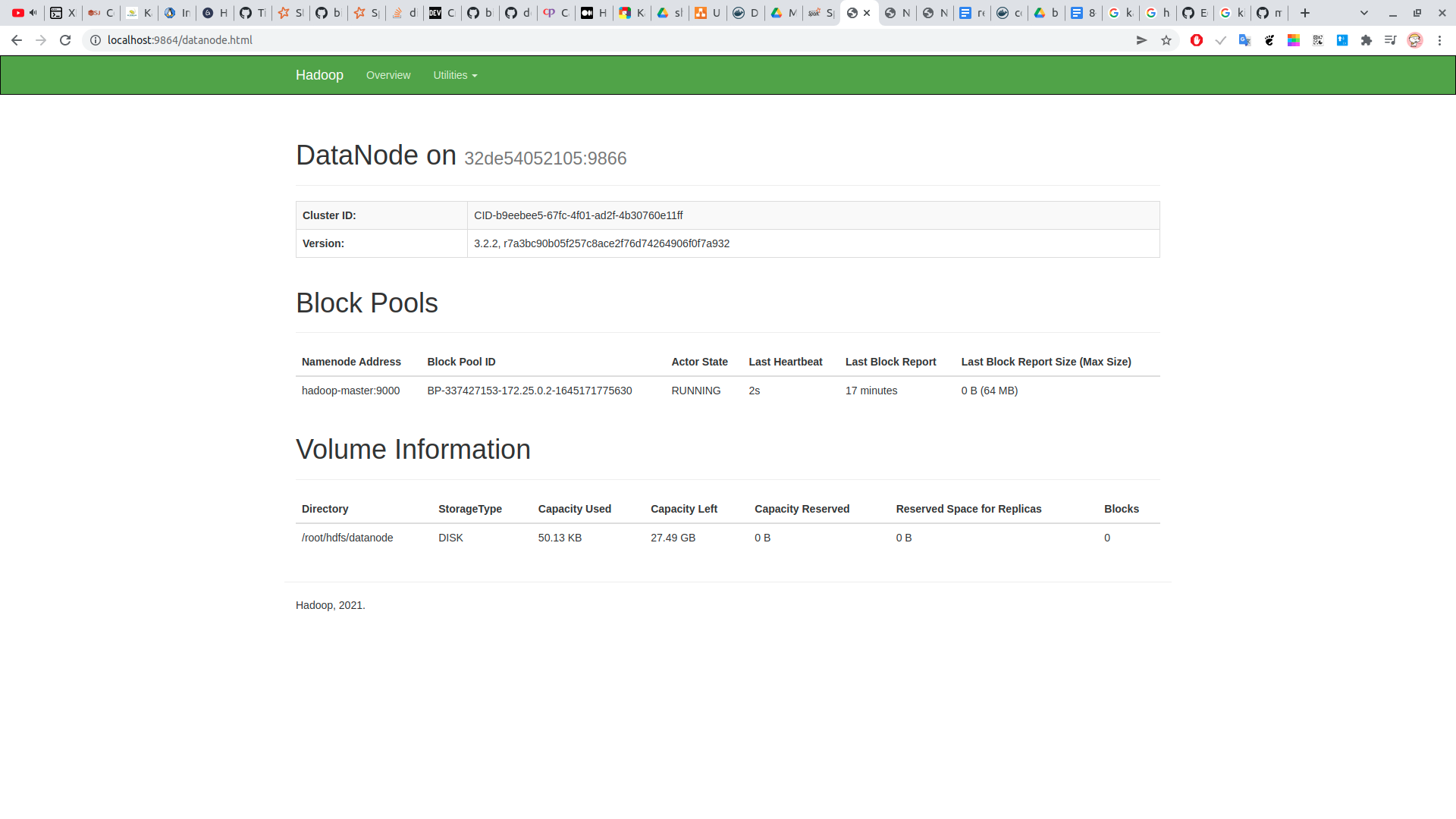
-
chạy thử một job spark rồi check ui yarn
http://localhost:8088/cluster/scheduler


docker exec -it hadoop-master bash
spark-shell --master yarn
- yarn:
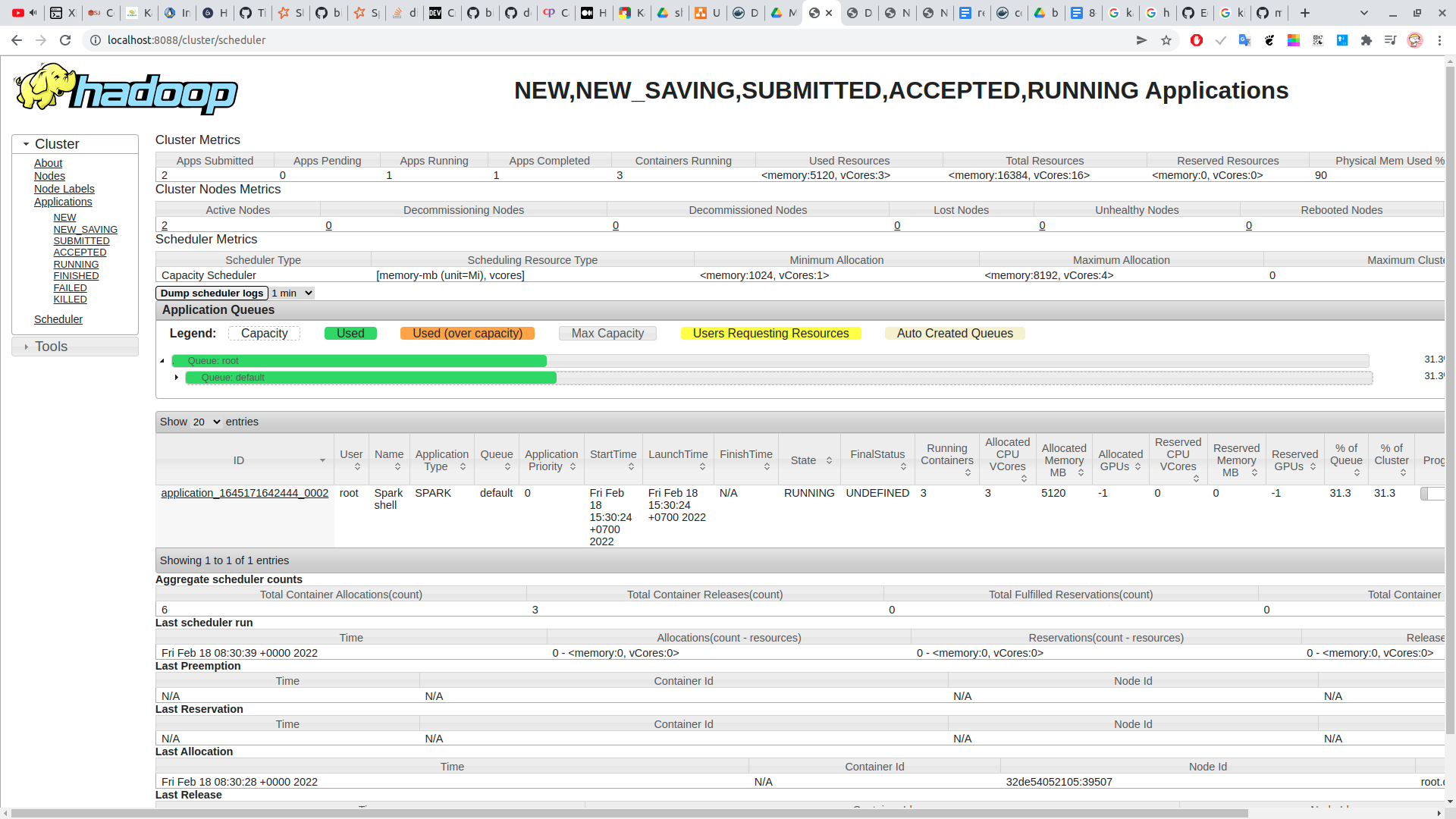

-
trong prj chạy lệnh class đẩy data vô cổng ngoài docker
localhost:29092com/team/job/create/CreateStream.java -
test thử bên ngoài docker. cũng đọc ở cổng
localhost:29092com/team/job/eval/TestReadKafka.java -
attach vô trong kafka để đọc data
docker exec -it kafka-name bash
kafka-console-consumer --topic hello-kafka --bootstrap-server kafka-host:9092 --from-beginning
-
chấp nhận là 1 thâng spark master sẽ không thể init được executer
-
nếu muốn chạy stand alone mode, chỉ cần trỏ spark folder. trong đó cấu hình file worker. vô sbin chạy start-all.sh. check jps tiến trình Worker và Master. chắc là trc đó vẫn cần ssh.
-
với stand alone, check job ở http://localhost:8080/
#
spark-submit --master spark://spark-master-host:7077 --total-executor-cores 4 --class com.team.job.process.PushHDFS /opt/bitnami/spark/examples/jars/shopee-streaming-1.0-SNAPSHOT-jar-with-dependencies.jar
#
start-slave.sh spark://localhost:7077
#
spark-shell --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.0 --master local val df = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "172.25.0.8:9092").option("subscribe", "hello-kafka").option("startingOffsets", "earliest").load()
val query2 = df.writeStream.format("console").start()- yarn mode để đọc thử streaming. nhớ chỉnh version kafka cho đúng với spark
spark-shell --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2 --master yarn --conf spark.sql.parquet.binaryAsString=true --num-executors 3 --executor-memory 1G
- submit to hdfs
spark-submit --master yarn --num-executors 3 --executor-memory 1G --class com.team.job.process.PushHDFS shopee-streaming-1.0-SNAPSHOT-jar-with-dependencies.jar
- check hdfs
spark-shell --master yarn --conf spark.sql.parquet.binaryAsString=true --num-executors 3 --executor-memory 1G
#
val df = spark.read.parquet("hdfs://hadoop-master:9000/test")
df.show()
+------------------+--------------------+
| key| val|
+------------------+--------------------+
| 2001:ac8:93::/48|Hanoi,Hanoi,Vietn...|
|2001:dc8:9000::/48| Vietnam,Asia|
| 2001:dc8::/47| Vietnam,Asia|
|2001:dc8:c000::/47| Vietnam,Asia|
|2001:df0:2740::/48| Vietnam,Asia|
| 2001:df0:66::/48| Vietnam,Asia|
|2001:df2:ce00::/48| Vietnam,Asia|
|2001:df3:e500::/48| Vietnam,Asia|
|2001:df4:2900::/48| Vietnam,Asia|
|2001:df4:2d00::/48| Vietnam,Asia|
|2001:df5:bb00::/48| Vietnam,Asia|
|2001:df7:c600::/48| Vietnam,Asia|
| 2001:ee0:100::/42| Vietnam,Asia|
| 2001:ac8:93::/48|Hanoi,Hanoi,Vietn...|
|2001:dc8:9000::/48| Vietnam,Asia|
| 2001:dc8::/47| Vietnam,Asia|
|2001:dc8:c000::/47| Vietnam,Asia|
|2001:df0:2740::/48| Vietnam,Asia|
| 2001:df0:66::/48| Vietnam,Asia|
|2001:df2:ce00::/48| Vietnam,Asia|
+------------------+--------------------+
only showing top 20 rows- check es
long@hello:~$ curl localhost:9200
{
"name" : "es-host",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "AEMQsZwhTVy4kLUqLdmEtw",
"version" : {
"number" : "7.11.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "8ced7813d6f16d2ef30792e2fcde3e755795ee04",
"build_date" : "2021-02-08T22:44:01.320463Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
-
đẩy lên dùng java
-
check data trên kibana:
http://localhost:5601/app/dev_tools#/console
GET test/_search # test is index name
{
"query": {
"match_all": {}
}
}
- đọc data từ HDFS và đẩy vô es
spark-submit --master yarn --num-executors 3 --executor-memory 1G --class com.team.job.process.PushES shopee-streaming-1.0-SNAPSHOT-jar-with-dependencies.jar
- check data
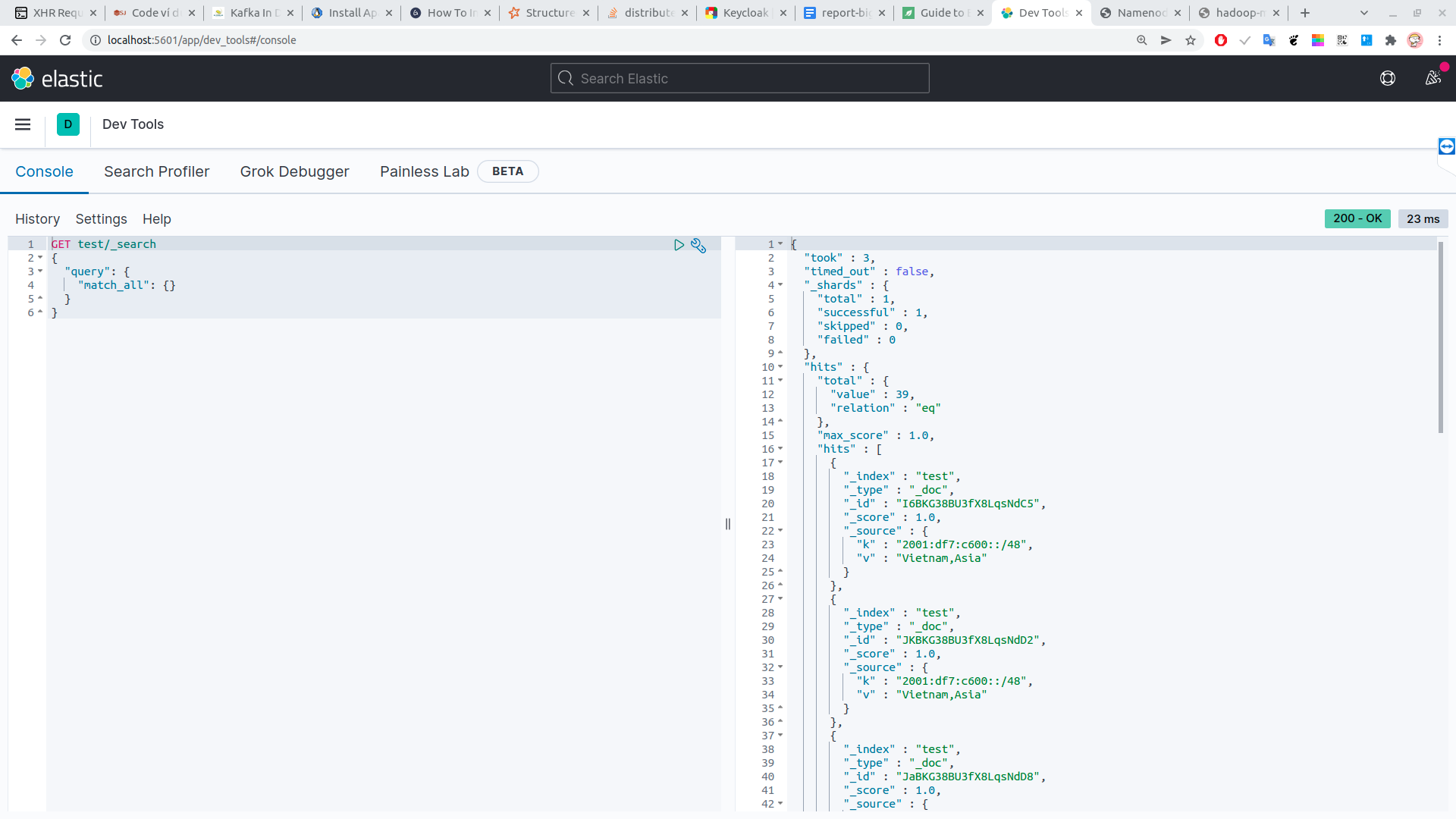

- load data tu es va chay phan tan
spark-submit --master yarn --num-executors 3 --executor-memory 1G --class com.team.job.process.ComputeES shopee-streaming-1.0-SNAPSHOT-jar-with-dependencies.jar
