from DatasetScraper.scraper import scrape
from DatasetScraper.curator import Curator
import os
# google search terms
search_terms = [
'teddy bears',
'black bears'
]
# name of the classes
classes = [
'teddy',
'black'
]# scrape the images
for i,search in enumerate(search_terms):
print("Fetching images of", classes[i])
# pass in path to chromedriver
scrape('/bin/chromedriver', search, classes[i])
print("Done\n")Fetching images of teddy
[*] Opening browser
[*] Scrolling to generate images
[*] Scraping
[*] Validating Files
Done
Fetching images of black
[*] Opening browser
[*] Scrolling to generate images
[*] Scraping
[*] Validating Files
Done
# time to curate
# get paths to teddy bear images
imgs = [os.path.join('teddy', file_name) for file_name in os.listdir('teddy')]
# create the Curator
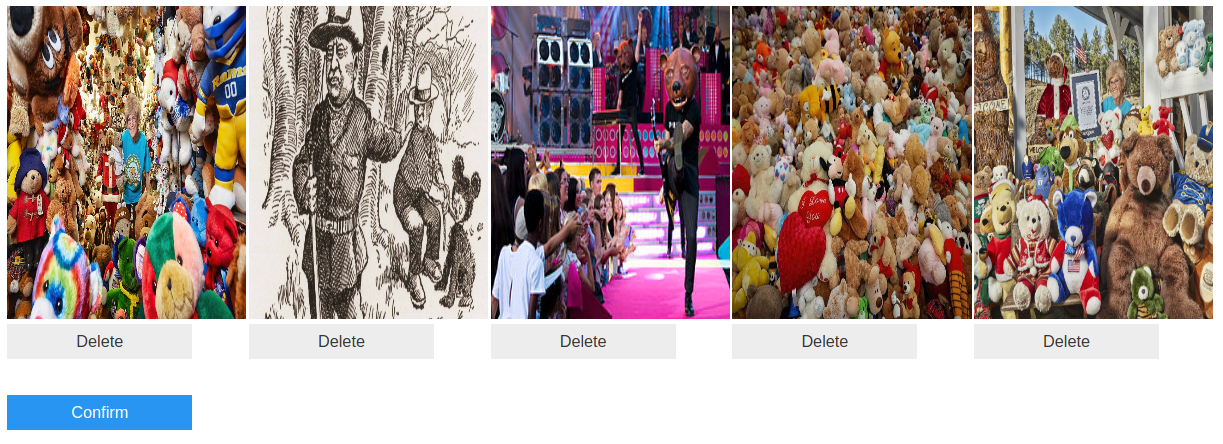
curator = Curator(img_paths=imgs)# find images which appear similar (from the eyes of a neural network)
curator.duplicate_detection()

# find images which appear different (from the eyes of a neural network)
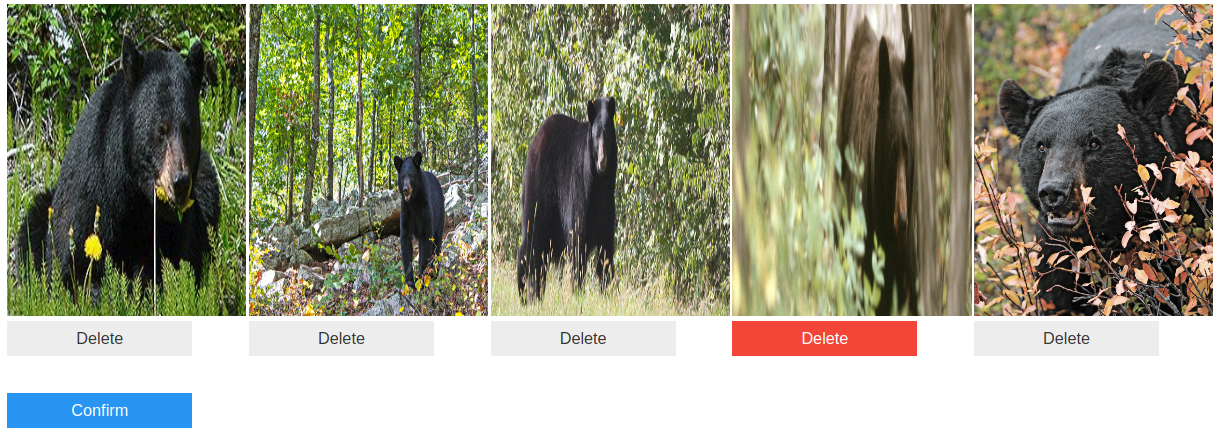
curator.garbage_detection()
# get paths to black bear images
imgs = [os.path.join('black', file_name) for file_name in os.listdir('black')]
# create the Curator
curator = Curator(img_paths=imgs)curator.duplicate_detection()

curator.garbage_detection()