每個人使用文字都有自己的習慣,習慣強烈的,我們能夠單憑人力就可辨別一份文件或一封Email到底是誰寫的,盡管這份文件或Email並沒有留下任何署名;然而,有些人的用字習慣可能是隱晦的,因而依靠人力很難去辨別原作者,此時就需要去建構Machine Learning的分析模型來解決問題
Text Learning是利用Machine Learning的方法,藉由分析文件中文字詞的種類,出現的頻率來建立分辨文件作者的模型
Enron Dataset 包含許多email文件,從中選取寄信者來自Chris和Sara的郵件,對一部份來自Chris和Sara的郵件作Machine Learning,試圖建構一個模型,在不知道寄件者的情況下,僅憑郵件的內容,便可判別此郵件來自Chris或Sara
更詳細對此程式演算法的解釋請點這裡
本程式以python3.6.0執行,使用函式庫nltk, numpy, scipy, sklearn, pandas, matplotlib
在Terminal輸入: git clone https://github.com/linhung0319/text-learning.git
執行 svm 資料夾內的主程式 svm_author_id.py
將Enron Dataset,來自Chris和Sara的郵件進行處理
只留下郵件中的內容部份
將內容部份的文字進行Stem和TFIDF轉換,得到每個字詞的重要性權重
主程式使用的是已處理後的Data, word_data.pkl 和 email_authors.pkl ,若要產生處理後的Data,需下載Enron Dataset:
-
執行 startup.py ,下載並解壓縮Enron Dataset至./maildir
-
執行 pickle_email_text.py ,將原始資料處理為 word_data.pkl 和 email_authors.pkl
-
執行 pickle_email_text.py
- 將email內容的文字進行Stem轉換 ( parse_out_email_text.py )
- 將轉換後的文字以list的形式儲存成 word_data.pkl
- 每個字對應的作者以list的形式儲存成 email_authors.pkl
-
email_preprocess.py
- 讀取 word_data.pkl 和 email_authors.pkl 並將這些字詞進行TFIDF轉換,計算出每個字詞的重要性權重
- 刪除掉其中出現過於頻繁的字詞(過於頻繁的字詞不具備代表性)
- 將字詞與其作者分為Training Set 和 Testing Set
利用Support Vector Machine演算法建構模型,根據Email使用的文字判斷Email屬於Sara或是Chris
調整SVM的參數以找到分類精準度最佳的結果 (Tuning Parameters in SVM)
利用SVM的Hyper Plane係數,找出對分類具有最高判別力的文字詞 (Top Features)
計算SVM分類結果的精準度 (Accuracy Score, Confusion Matrix, Precision, Recall Score)
-
執行 svm_author_id.py
- 測試SVM的不同參數,以得到最高的分類精準度 (find_best_param)
- 以最佳的SVM參數去建構分類Email的模型
- 找出此SVM模型,作為判斷Email分類,最重要的文字詞
- 計算模型的精準度
-
plot_gallery.py
- 畫出不同參數下SVM分類Email的精準度
- 分別畫出SVM模型判斷Email屬於Sara或Chris,最重要的文字詞及其相對比重
- 不同參數下SVM模型的Accuracy Score
下圖為以C, gamma作為調整參數,在linear kernel和rbf (常態分佈) kernel下的Accuracy Score (僅放入1/10的Training Data, 約200封Email)
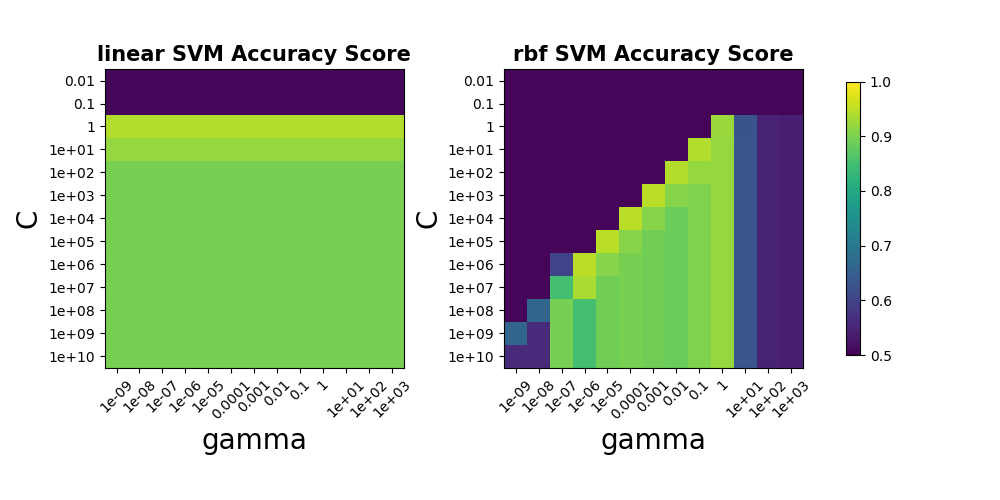
一般SVM使用的是rbf的kernel來建立模型, 然而當Data的feature維度非常大時,便不太需要將Sample投影到高維度,通常可以直接在現維度找到線性的Hyper Plane作分割
由圖可以發現,由於Word Feature的維度高達1708個,因此使用linear kernel的SVM模型,其精準度並不比rbf kernel來的低
由於從linear kernel的SVM模型中找出最具判別力的字詞較為簡單,因此使用linear kernel的SVM作分析
- 找出最具判別力的字詞
下圖為Sara和Chris的Email中判斷力前20的字詞
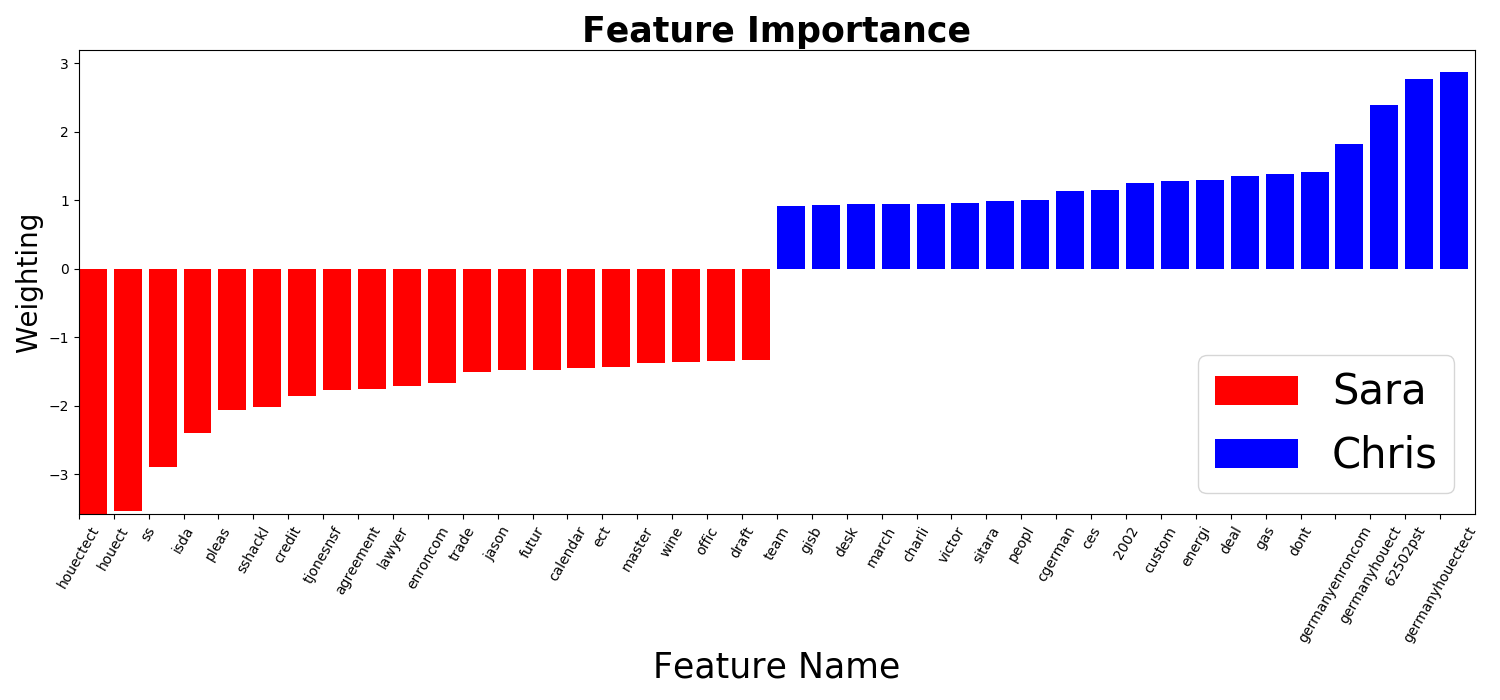
linear kernel SVM的Hyper Plane法向量,可以看成是最能分類Data的方向,若某一個維度(字詞)在此方向上的比重很大,則表示此維度(字詞)分類Data的能力很強;反之,若在此方向上的分量很小,則表示此維度(字詞)分類Data的能力很差,較不重要
因此,讀取linear kernel SVM的Hyper Plane法向量,可以根據比重,知道哪個Email中的字詞最具有判斷能力
- 分析SVM模型的精準度
- Accuracy Score = 97%
- 分類成功的Email數量 / 總共的Email數量
- Accuracy Score很高表示此模型能很好的判別Sara和Chris的Email
| Confusion Matrix | Predicted Sara | Predicted Chris |
|---|---|---|
| True Sara | 7568 (TP) | 312 (FP) |
| True Chris | 146 (FN) | 7795 (TN) |
-
Precision Score = 96%
- TP / (TP + FP)
- Precision Score越高,表示Sara的郵件被誤判為Chris的郵件的機率越低
-
Recall Score = 98%
- TP / (TP + FN)
- Recall Score越高,表示Chris的郵件被誤判為Sara的郵件的機率越低
由於Precision Score略低於Recall Score,表示Sara的郵件較容易被誤判為Chris的郵件,因此這個模型對Chris郵件的判別力大於Sara郵件
從Confusion Matrix其實也可以很簡單的看出,在Sara和Chris的郵件總數差不多的情況下,Sara的郵件被誤判為Chris的有312封;反之,Chris的郵件被誤判為Sara的146封
此程式主要的演算法,包括建立分析模型前對Data的處理方式,和使用SVM建立分析模型,參考於線上課程網站Udacity的Nano Degree,Intro to Machine Learning
調整SVM模型不同參數的方法,參考於sklearn的範例頁
找出Email文字中最具判斷力的字詞(Word Feature)的方法,參考於Visualising Top Features in Linear SVM with Scikit Learn and Matplotlib