This repo contains the code, data, and models for "MAmmoTH2: Scaling Instructions from the Web". Our paper proposes a new paradigm to scale up high-quality instruction data from the web.
🔥 🔥 🔥 Check out our [Project Page] for more results and analysis!
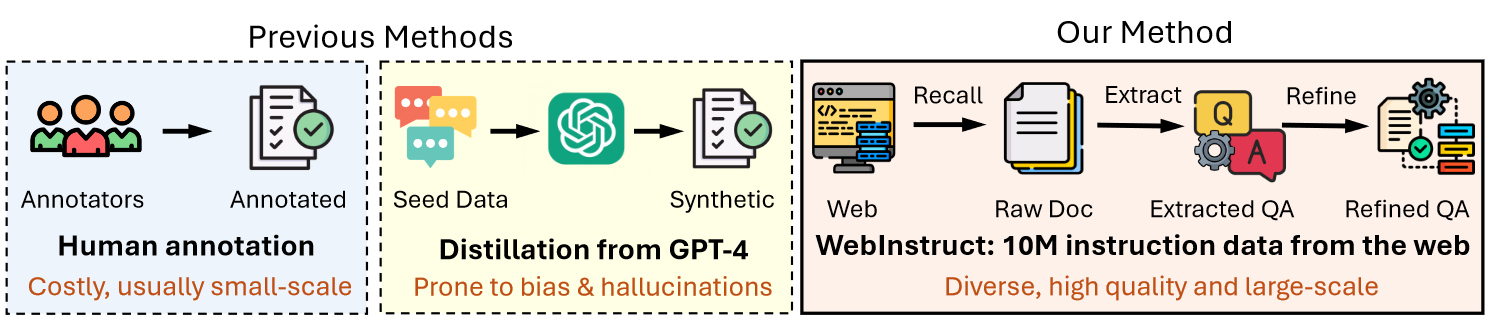
We propose discovering instruction data from the web. We argue that vast amounts of high-quality instruction data exist in the web corpus, spanning various domains like math and science. Our three-step pipeline involves recalling documents from Common Crawl, extracting Q-A pairs, and refining them for quality. This approach yields 10 million instruction-response pairs, offering a scalable alternative to existing datasets. We name our curated dataset as WebInstruct.
| Model | Dataset | Init Model | Download |
|---|---|---|---|
| MAmmoTH2-8x7B | WebInstruct | Mixtral-8x7B | 🤗 HuggingFace |
| MAmmoTH2-7B | WebInstruct | Mistral-7B-v0.2 | 🤗 HuggingFace |
| MAmmoTH2-8B | WebInstruct | Llama-3-base | 🤗 HuggingFace |
| MAmmoTH2-8x7B-Plus | WebInstruct + OpenHermes2.5 + CodeFeedback + Math-Plus | MAmmoTH2-8x7B | 🤗 HuggingFace |
| MAmmoTH2-7B-Plus | WebInstruct + OpenHermes2.5 + CodeFeedback + Math-Plus | MAmmoTH2-7B | 🤗 HuggingFace |
| MAmmoTH2-8B-Plus | WebInstruct + OpenHermes2.5 + CodeFeedback + Math-Plus | MAmmoTH2-8B | 🤗 HuggingFace |
For the 20B+ models:
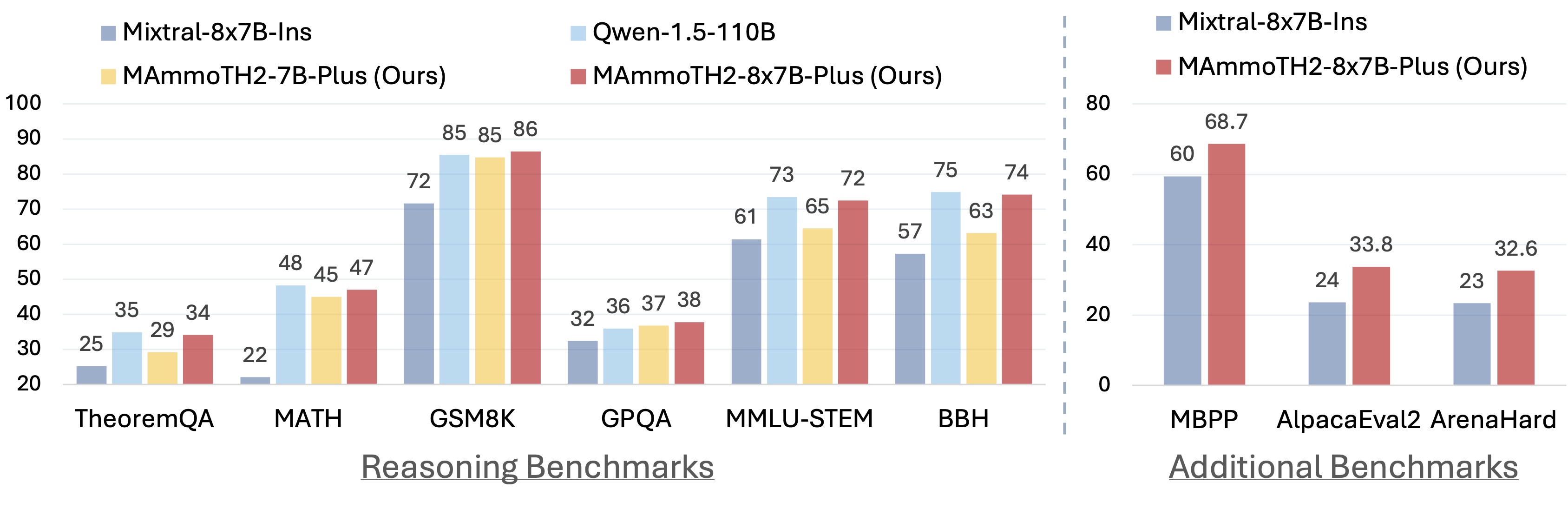
| Model | TheoremQA | MATH | GSM8K | GPQA | MMLU-ST | BBH | ARC-C | Avg |
|---|---|---|---|---|---|---|---|---|
| GPT-4-Turbo-0409 | 48.4 | 69.2 | 94.5 | 46.2 | 76.5 | 86.7 | 93.6 | 73.6 |
| Qwen-1.5-110B | 34.9 | 49.6 | 85.4 | 35.9 | 73.4 | 74.8 | 91.6 | 63.6 |
| Qwen-1.5-72B | 29.3 | 46.8 | 77.6 | 36.3 | 68.5 | 68.0 | 92.2 | 59.8 |
| Deepseek-LM-67B | 25.3 | 15.9 | 66.5 | 31.8 | 57.4 | 71.7 | 86.8 | 50.7 |
| Yi-34B | 23.2 | 15.9 | 67.9 | 29.7 | 62.6 | 66.4 | 89.5 | 50.7 |
| Llemma-34B | 21.1 | 25.0 | 71.9 | 29.2 | 54.7 | 48.4 | 69.5 | 45.7 |
| Mixtral-8×7B | 23.2 | 28.4 | 74.4 | 29.7 | 59.7 | 66.8 | 84.7 | 52.4 |
| Mixtral-8×7B-Instruct | 25.3 | 22.1 | 71.7 | 32.4 | 61.4 | 57.3 | 84.7 | 50.7 |
| Intern-Math-20B | 17.1 | 37.7 | 82.9 | 28.9 | 50.1 | 39.3 | 68.6 | 46.4 |
| MAmmoTH2-34B | 30.4 | 35.0 | 75.6 | 31.8 | 64.5 | 68.0 | 90.0 | 56.4 |
| MAmmoTH2-8x7B | 32.2 | 39.0 | 75.4 | 36.8 | 67.4 | 71.1 | 87.5 | 58.9 |
| MAmmoTH2-8x7B-Plus | 34.1 | 47.0 | 86.4 | 37.8 | 72.4 | 74.1 | 88.4 | 62.9 |
For the 7B/8B-scale models:
| Model | TheoremQA | MATH | GSM8K | GPQA | MMLU-ST | BBH | ARC-C | Avg |
|---|---|---|---|---|---|---|---|---|
| Deepseek-7B | 15.7 | 6.4 | 17.4 | 25.7 | 43.1 | 42.8 | 47.8 | 28.4 |
| Qwen-1.5-7B | 14.2 | 13.3 | 54.1 | 26.7 | 45.4 | 45.2 | 75.6 | 39.2 |
| Mistral-7B | 19.2 | 11.2 | 36.2 | 24.7 | 50.1 | 55.7 | 74.2 | 38.8 |
| Gemma-7B | 21.5 | 24.3 | 46.4 | 25.7 | 53.3 | 57.4 | 72.5 | 43.0 |
| Llemma-7B | 17.2 | 18.0 | 36.4 | 23.2 | 45.2 | 44.9 | 50.5 | 33.6 |
| WizardMath-7B-1.1 | 11.7 | 33.0 | 83.2 | 28.7 | 52.7 | 56.7 | 76.9 | 49.0 |
| OpenMath-Mistral | 13.1 | 9.1 | 24.5 | 26.5 | 43.7 | 49.5 | 69.4 | 33.7 |
| Abel-7B-002 | 19.3 | 29.5 | 83.2 | 30.3 | 29.7 | 32.7 | 72.5 | 42.5 |
| Intern-Math-7B | 13.2 | 34.6 | 78.1 | 22.7 | 41.1 | 48.1 | 59.8 | 42.5 |
| Rho-1-Math-7B | 21.0 | 31.0 | 66.9 | 29.2 | 53.1 | 57.7 | 72.7 | 47.3 |
| Deepseek-Math-7B | 25.3 | 34.0 | 64.2 | 29.2 | 56.4 | 59.5 | 67.8 | 48.0 |
| Deepseek-Math-Instruct | 23.7 | 44.3 | 82.9 | 31.8 | 59.3 | 55.4 | 70.1 | 52.5 |
| Llama-3-8B | 20.1 | 21.3 | 54.8 | 27.2 | 55.6 | 61.1 | 78.6 | 45.5 |
| Llama-3-8B-Instruct | 22.8 | 30.0 | 79.5 | 34.5 | 60.2 | 66.0 | 80.8 | 53.4 |
| MAmmoTH2-7B | 26.7 | 34.2 | 67.4 | 34.8 | 60.6 | 60.0 | 81.8 | 52.2 |
| MAmmoTH2-8B | 29.7 | 33.4 | 67.9 | 38.4 | 61.0 | 60.8 | 81.0 | 53.1 |
| MAmmoTH2-7B-Plus | 29.2 | 45.0 | 84.7 | 36.8 | 64.5 | 63.1 | 83.0 | 58.0 |
| MAmmoTH2-8B-Plus | 32.5 | 42.8 | 84.1 | 37.3 | 65.7 | 67.8 | 83.4 | 59.1 |
Coming soon!