Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch
-
-
Author: Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, Che Zheng
-
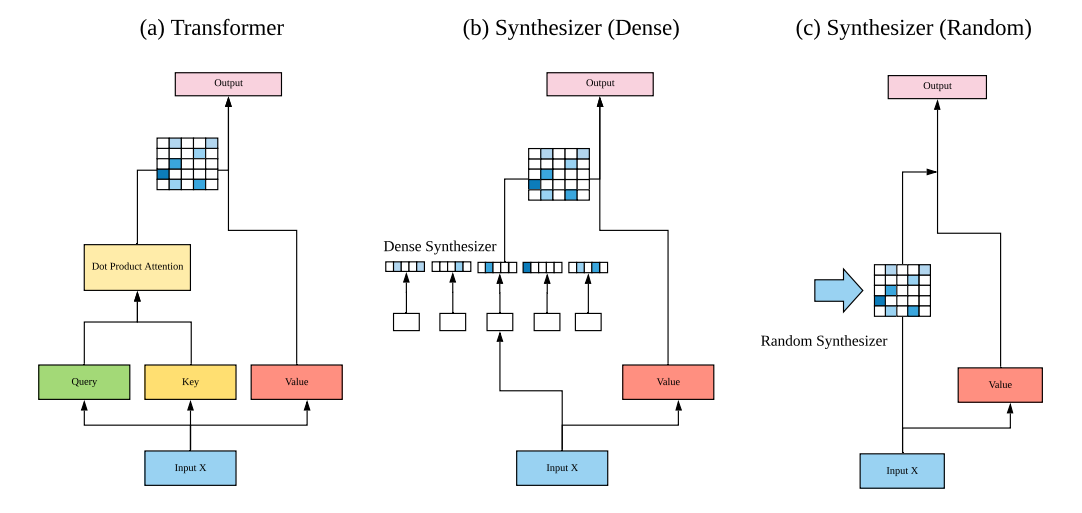
2. Fixed Random Synthesizer
4. Factorized Dense Synthesizer
5. Factorized Random Synthesizer
6. Mixture of Synthesizers
import torch
from synthesizer import Transformer, SynthesizerDense, SynthesizerRandom, FactorizedSynthesizerDense, FactorizedSynthesizerRandom, MixtureSynthesizers, get_n_params, calculate_flops
def main():
batch_size, channel_dim, sentence_length = 2, 1024, 32
x = torch.randn([batch_size, sentence_length, channel_dim])
vanilla = Transformer(channel_dim)
out, attention_map = vanilla(x)
print(out.size(), attention_map.size())
n_params, flops = get_n_params(vanilla), calculate_flops(vanilla.children())
print('vanilla, n_params: {}, flops: {}'.format(n_params, flops))
dense_synthesizer = SynthesizerDense(channel_dim, sentence_length)
out, attention_map = dense_synthesizer(x)
print(out.size(), attention_map.size())
n_params, flops = get_n_params(dense_synthesizer), calculate_flops(dense_synthesizer.children())
print('dense_synthesizer, n_params: {}, flops: {}'.format(n_params, flops))
random_synthesizer = SynthesizerRandom(channel_dim, sentence_length)
out, attention_map = random_synthesizer(x)
print(out.size(), attention_map.size())
n_params, flops = get_n_params(random_synthesizer), calculate_flops(random_synthesizer.children())
print('random_synthesizer, n_params: {}, flops: {}'.format(n_params, flops))
random_synthesizer_fix = SynthesizerRandom(channel_dim, sentence_length, fixed=True)
out, attention_map = random_synthesizer_fix(x)
print(out.size(), attention_map.size())
n_params, flops = get_n_params(random_synthesizer_fix), calculate_flops(random_synthesizer_fix.children())
print('random_synthesizer_fix, n_params: {}, flops: {}'.format(n_params, flops))
factorized_synthesizer_random = FactorizedSynthesizerRandom(channel_dim)
out, attention_map = factorized_synthesizer_random(x)
print(out.size(), attention_map.size())
n_params, flops = get_n_params(factorized_synthesizer_random), calculate_flops(
factorized_synthesizer_random.children())
print('factorized_synthesizer_random, n_params: {}, flops: {}'.format(n_params, flops))
factorized_synthesizer_dense = FactorizedSynthesizerDense(channel_dim, sentence_length)
out, attention_map = factorized_synthesizer_dense(x)
print(out.size(), attention_map.size())
n_params, flops = get_n_params(factorized_synthesizer_dense), calculate_flops(
factorized_synthesizer_dense.children())
print('factorized_synthesizer_dense, n_params: {}, flops: {}'.format(n_params, flops))
mixture_synthesizer = MixtureSynthesizers(channel_dim, sentence_length)
out, attention_map = mixture_synthesizer(x)
print(out.size(), attention_map.size())
n_params, flops = get_n_params(mixture_synthesizer), calculate_flops(mixture_synthesizer.children())
print('mixture_synthesizer, n_params: {}, flops: {}'.format(n_params, flops))
if __name__ == '__main__':
main()torch.Size([2, 32, 1024]) torch.Size([2, 32, 32])
vanilla, n_params: 3148800, flops: 3145729
torch.Size([2, 32, 1024]) torch.Size([2, 32, 32])
dense_synthesizer, n_params: 1083456, flops: 1082370
torch.Size([2, 32, 1024]) torch.Size([1, 32, 32])
random_synthesizer, n_params: 1050624, flops: 1048577
torch.Size([2, 32, 1024]) torch.Size([1, 32, 32])
random_synthesizer_fix, n_params: 1050624, flops: 1048577
torch.Size([2, 32, 1024]) torch.Size([2, 32, 32])
factorized_synthesizer_random, n_params: 1066000, flops: 1064961
torch.Size([2, 32, 1024]) torch.Size([2, 32, 32])
factorized_synthesizer_dense, n_params: 1061900, flops: 1060865
torch.Size([2, 32, 1024]) torch.Size([2, 32, 32])
mixture_synthesizer, n_params: 3149824, flops: 3145729