![]()
![]()
Lantern is an open-source PostgreSQL database extension to store vector data, generate embeddings, and handle vector search operations.
It provides a new index type for vector columns called lantern_hnsw which speeds up ORDER BY ... LIMIT queries.
Lantern builds and uses usearch, a single-header state-of-the-art HNSW implementation.
If you don’t have PostgreSQL already, use Lantern with Docker to get started quickly:
docker run --pull=always --rm -p 5432:5432 -e "POSTGRES_USER=$USER" -e "POSTGRES_PASSWORD=postgres" -v ./lantern_data:/var/lib/postgresql/data lanterndata/lantern:latest-pg15Then, you can connect to the database via postgresql://$USER:postgres@localhost/postgres.
To install Lantern using homebrew:
brew tap lanterndata/lantern
brew install lantern && lantern_install
You can also install Lantern on top of PostgreSQL from our precompiled binaries via a single make install.
Alternatively, you can use Lantern in one click using Replit.
Prerequisites:
cmake version: >=3.3
gcc && g++ version: >=11 when building portable binaries, >= 12 when building on new hardware or with CPU-specific vectorization
PostgreSQL 11, 12, 13, 14, 15 or 16
Corresponding development package for PostgreSQL (postgresql-server-dev-$version)
To build Lantern on new hardware or with CPU-specific vectorization:
git clone --recursive https://github.com/lanterndata/lantern.git
cd lantern
cmake -DMARCH_NATIVE=ON -S lantern_hnsw -B build
make -C build install -j
To build portable Lantern binaries:
git clone --recursive https://github.com/lanterndata/lantern.git
cd lantern
cmake -DMARCH_NATIVE=OFF -S lantern_hnsw -B build
make -C build install -j
Lantern retains the standard PostgreSQL interface, so it is compatible with all of your favorite tools in the PostgreSQL ecosystem.
First, enable Lantern in SQL (e.g. via psql shell)
CREATE EXTENSION lantern;Note: After running the above, lantern extension is only available on the current postgres DATABASE (single postgres instance may have multiple such DATABASES). When connecting to a different DATABASE, make sure to run the above command for the new one as well. For example:
CREATE DATABASE newdb;
\c newdb
CREATE EXTENSION lantern;Create a table with a vector column and add your data
CREATE TABLE small_world (id integer, vector real[3]);
INSERT INTO small_world (id, vector) VALUES (0, '{0,0,0}'), (1, '{0,0,1}');Create an hnsw index on the table via lantern_hnsw:
CREATE INDEX ON small_world USING lantern_hnsw (vector);Customize lantern_hnsw index parameters depending on your vector data, such as the distance function (e.g., dist_l2sq_ops), index construction parameters, and index search parameters.
CREATE INDEX ON small_world USING lantern_hnsw (vector dist_l2sq_ops)
WITH (M=2, ef_construction=10, ef=4, dim=3);Start querying data
SET enable_seqscan = false;
SELECT id, l2sq_dist(vector, ARRAY[0,0,0]) AS dist
FROM small_world ORDER BY vector <-> ARRAY[0,0,0] LIMIT 1;Lantern supports several distance functions in the index
There are 3 operators available <-> (l2sq), <=> (cosine), <+> (hamming).
There are four defined operator classes that can be employed during index creation:
dist_l2sq_ops: Default for the typereal[]dist_vec_l2sq_ops: Default for the typevectordist_cos_ops: Applicable to the typereal[]dist_vec_cos_ops: Applicable to the typevectordist_hamming_ops: Applicable to the typeinteger[]
The M, ef, and ef_construction parameters control the performance of the HNSW algorithm for your use case.
- In general, lower
Mandef_constructionspeed up index creation at the cost of recall. - Lower
Mandefimprove search speed and result in fewer shared buffer hits at the cost of recall. Tuning these parameters will require experimentation for your specific use case.
- If you have previously cloned Lantern and would like to update run
git pull && git submodule update --recursive
- Embedding generation for popular use cases (CLIP model, Hugging Face models, custom model)
- Interoperability with pgvector's data type, so anyone using pgvector can switch to Lantern
- Parallel index creation via an external indexer
- Ability to generate the index graph outside of the database server
- Support for creating the index outside of the database and inside another instance allows you to create an index without interrupting database workflows.
- See all of our helper functions to better enable your workflows
Important takeaways:
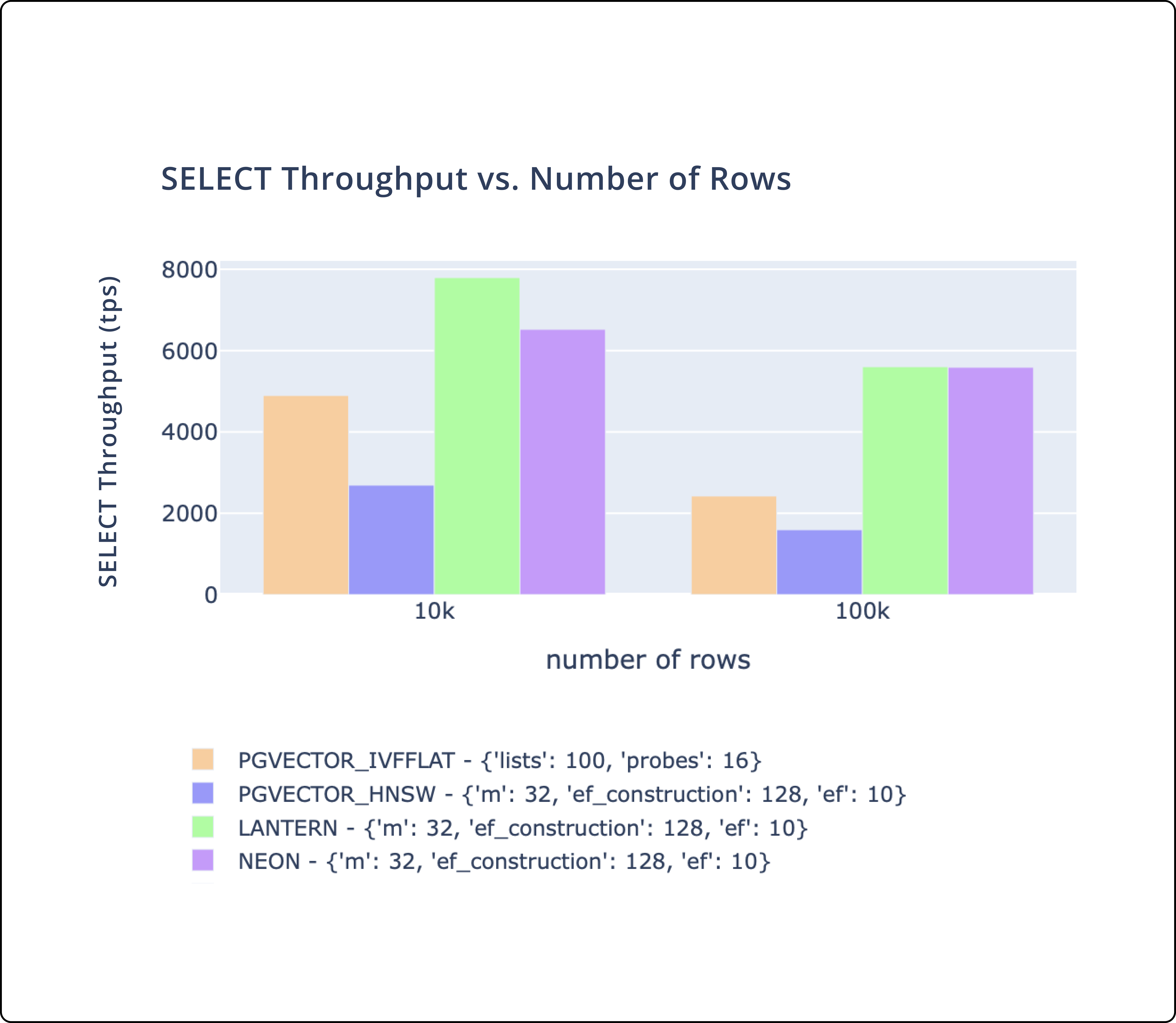
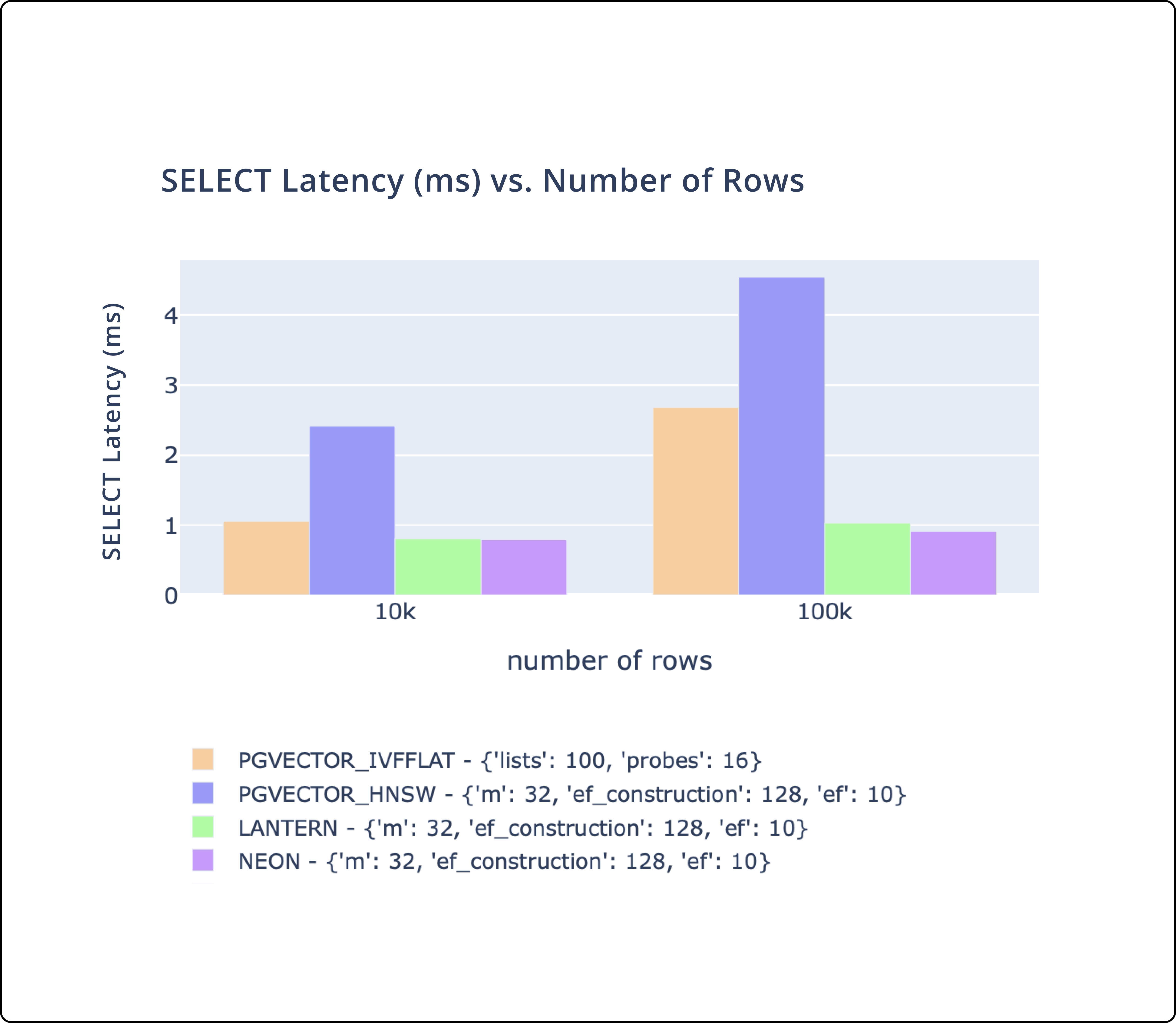
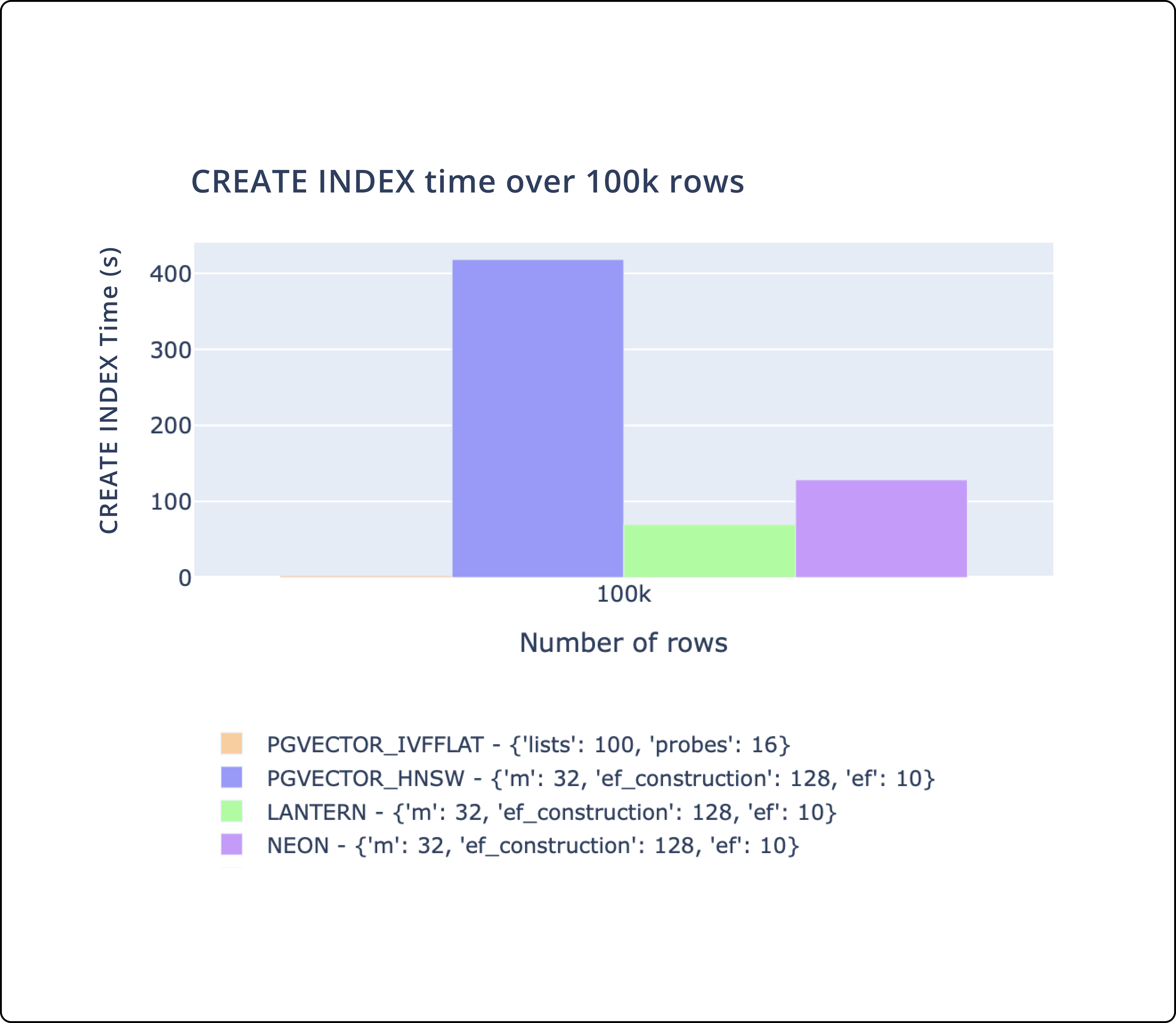
- There's three key metrics we track.
CREATE INDEXtime,SELECTthroughput, andSELECTlatency. - We match or outperform pgvector and pg_embedding (Neon) on all of these metrics.
- We plan to continue to make performance improvements to ensure we are the best performing database.
- Cloud-hosted version of Lantern - Sign up here
- Hardware-accelerated distance metrics, tailored for your CPU, enabling faster queries
- Templates and guides for building applications for different industries
- More tools for generating embeddings (support for third party model API’s, more local models)
- Support for version control and A/B test embeddings
- Autotuned index type that will choose appropriate creation parameters
- Support for 1 byte and 2 byte vector elements, and up to 8000 dimensional vectors (PR #19)
- Request a feature at support@lantern.dev
- GitHub issues: report bugs or issues with Lantern
- Need support? Contact support@lantern.dev. We are happy to troubleshoot issues and advise on how to use Lantern for your use case
- We welcome community contributions! Feel free to open an issue or a PR. If you contact support@lantern.dev, we can find an open issue or project that fits you