Data exchange 实现从源读取数据 -> 目标数据类型转换 -> 写到目标数据源
数据中台必备,架构师利器
当前版本最后编译时间20220818
- 支持跨平台执行(windows,linux),只需要一个可执行文件和一个配置文件就可以运行,无需其它依赖,轻量级引擎。
- 输入输出数据源支持influxdb v1、clickhouse、mysql、rocketmq、kafka、redis、excel
- 任意一个输入节点可以同任意一个输出节点进行组合,遵循pipeline模型。
- 为满足业务场景需要,支持配置文件中使用全局变量,实现动态更新配置文件功能。
- 任意一个输出节点都可以嵌入go语言脚本并进行解析,实现对输出数据流的格式转换功能。
- 支持节点级二次开发,通过配置自定义节点,并在自定义节点中配置go语言脚本,可扩展实现各种功能操作。
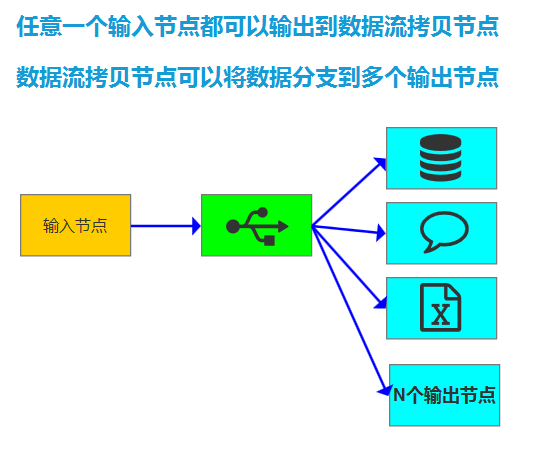
- 任意一个输入节点都可以通过组合数据流拷贝节点,实现从一个输入同时分支到多个输出的场景。
- 支持将各节点执行日志输出到数据库中。
- 支持跟crontab调度组合配置,实现周期性执行etl-engine任务。
- 输入输出任意组合

- 解析嵌入脚本语言 方便格式转换

- 数据流复制 方便多路输出
- 自定义节点 方便实现各种操作

- run_crontab与run_graph灵活组合

run_graph.exe -fileUrl .\graph.xml -logLevel info
run_graph -fileUrl .\graph.xml -logLevel info
<?xml version="1.0" encoding="UTF-8"?>
<Graph>
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="5">
<Script name="sqlScript"><![CDATA[
select * from (select * from t3 limit 10)
]]></Script>
</Node>
<Node id="DB_OUTPUT_01" type="DB_OUTPUT_TABLE" desc="节点2" dbConnection="CONNECT_02" outputFields="f1;f2" renameOutputFields="c1;c2" outputTags="tag1;tag4" renameOutputTags="tag_1;tag_4" measurement="t1" rp="autogen">
</Node>
<!--
<Node id="DB_OUTPUT_02" type="DB_OUTPUT_TABLE" desc="节点3" dbConnection="CONNECT_03" outputFields="f1;f2;f3" renameOutputFields="c1;c2;c3" batchSize="1000" >
<Script name="sqlScript"><![CDATA[
insert into db1.t1 (c1,c2,c3) values (?,?,?)
]]></Script>
</Node>
-->
<Line id="LINE_01" type="STANDARD" from="DB_INPUT_01" to="DB_OUTPUT_01" order="0" metadata="METADATA_01"></Line>
<Metadata id="METADATA_01">
<Field name="c1" type="string" default="-1" nullable="false"/>
<Field name="c2" type="int" default="-1" nullable="false"/>
<Field name="tag_1" type="string" default="-1" nullable="false"/>
<Field name="tag_4" type="string" default="-1" nullable="false"/>
</Metadata>
<Connection id="CONNECT_01" dbURL="http://127.0.0.1:58080" database="db1" username="user1" password="******" token=" " org="hw" type="INFLUXDB_V1"/>
<Connection id="CONNECT_02" dbURL="http://127.0.0.1:58086" database="db1" username="user1" password="******" token=" " org="hw" type="INFLUXDB_V1"/>
<!-- <Connection id="CONNECT_04" dbURL="127.0.0.1:19000" database="db1" username="user1" password="******" type="CLICKHOUSE"/>-->
<!-- <Connection id="CONNECT_03" dbURL="127.0.0.1:3306" database="db1" username="user1" password="******" type="MYSQL"/>-->
</Graph>任意一个读节点都可以输出到任意一个写节点
输入节点-读数据表
输出节点-写数据表
输入节点-读 excel文件
输出节点-写 excel文件
输入节点-执行数据库脚本
输出节点-垃圾桶,没有任何输出
输入节点-MQ消费者
输出节点-MQ生产者
数据流拷贝节点,位于输入节点和输出节点之间,既是输出又是输入
输入节点-读 redis
输出节点-写 redis
自定义节点,通过嵌入go脚本来实现各种操作
输入节点-执行系统脚本节点
输入节点-读取CSV文件节点
DB_INPUT_TABLE -> DB_OUT_TABLEDB_INPUT_TABLE -> XLS_WRITERDB_INPUT_TABLE -> MQ_PRODUCERDB_INPUT_TABLE -> REDIS_WRITERXLS_READER -> DB_OUT_TABLEXLS_READER -> XLS_WRITERXLS_READER -> MQ_PRODUCERXLS_READER -> REDIS_WRITERDB_EXECUTE_TABLE -> OUTPUT_TRASHDB_EXECUTE_TABLE -> DB_OUT_TABLEDB_EXECUTE_TABLE -> XLS_WRITERDB_EXECUTE_TABLE -> MQ_PRODUCERDB_EXECUTE_TABLE -> REDIS_WRITERMQ_CONSUMER -> DB_OUT_TABLEMQ_CONSUMER -> XLS_WRITERMQ_CONSUMER -> MQ_PRODUCERMQ_CONSUMER -> REDIS_WRITERDB_INPUT_TABLE -> COPY_STREAMXLS_READER -> COPY_STREAMMQ_CONSUMER -> COPY_STREAMREDIS_READER -> COPY_STREAMCOPY_STREAM -> DB_OUT_TABLECOPY_STREAM -> XLS_WRITERCOPY_STREAM -> MQ_PRODUCERCOPY_STREAM -> REDIS_WRITEREDIS_READER -> DB_OUT_TABLEREDIS_READER -> XLS_WRITERREDIS_READER -> MQ_PRODUCERREDIS_READER -> REDIS_WRITERCUSTOM_READER_WRITER -> OUTPUT_TRASHEXECUTE_SHELL -> DB_OUT_TABLEEXECUTE_SHELL -> XLS_WRITEREXECUTE_SHELL -> MQ_PRODUCEREXECUTE_SHELL -> REDIS_WRITEREXECUTE_SHELL -> OUTPUT_TRASHCSV_READER -> DB_OUT_TABLECSV_READER -> XLS_WRITERCSV_READER -> MQ_PRODUCERCSV_READER -> REDIS_WRITERCSV_READER -> OUTPUT_TRASH
输入节点
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, DB_INPUT_TABLE |
| script | sqlScript SQL语句 |
| fetchSize | 每次读取记录数 |
| dbConnection | 数据源ID |
| desc | 描述 |
MYSQL、Influxdb 1x、CK
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="1000">
<Script name="sqlScript"><![CDATA[
select * from (select * from t4 limit 100000)
]]></Script>
</Node>输入节点
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, XLS_READER |
| fileURL | 文件路径+文件名称 |
| startRow | 从第几行开始读取 |
| sheetName | 表名称 |
| fieldMap | 字段映射关系,格式:field1=A;field2=B;field3=C 字段名称=第几列 多个字段之间用分号分隔 |
<Node id="XLS_READER_01" type="XLS_READER" desc="输入节点1" fileURL="d:/demo/test1.xlsx" startRow="2" sheetName="人员信息" fieldMap="field1=1;field2=2;field3=3">
</Node>输出节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | 类型, DB_OUTPUT_TABLE | |
| sqlScript | insert、delete、update SQL语句 | ck,mysql |
| batchSize | 每次批提交的记录数 | ck,mysql 注意influx以输入时的fetchSize为批提交的大小 |
| outputFields | 输入节点读数据时传递过来的字段名称 | influx,ck,mysql |
| renameOutputFields | 输出节点到目标数据源的字段名称 | influx,ck,mysql |
| dbConnection | 数据源ID | |
| desc | 描述 | |
| outputTags | 输入节点读数据时传递过来的标签名称 | influx |
| renameOutputTags | 输出节点到目标数据源的标签名称 | influx |
| rp | 保留策略名称 | influx |
| measurement | 表名称 | influx |
MYSQL、Influxdb 1x、CK
<Node id="DB_OUTPUT_01" type="DB_OUTPUT_TABLE" desc="写influx节点1" dbConnection="CONNECT_02" outputFields="f1;f2;f3;f4" renameOutputFields="c1;c2;c3;c4" outputTags="tag1;tag2;tag3;tag4" renameOutputTags="tag_1;tag_2;tag_3;tag_4" measurement="t5" rp="autogen">
</Node>
<Node id="DB_OUTPUT_02" type="DB_OUTPUT_TABLE" desc="写mysql节点2" dbConnection="CONNECT_03" outputFields="time;f1;f2;f3;f4;tag1;tag2;tag3;tag4" renameOutputFields="time;c1;c2;c3;c4;tag_1;tag_2;tag_3;tag_4" batchSize="1000" >
<Script name="sqlScript"><![CDATA[
insert into db1.t1 (time,c1,c2,c3,c4,tag_1,tag_2,tag_3,tag_4) values (?,?,?,?,?,?,?,?,?)
]]></Script>
</Node>输出节点
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, XLS_WRITER |
| fileURL | 文件路径+文件名称 |
| startRow | 从第几行开始读取 如:数字2代表是第2行 开始写数据 |
| sheetName | 表名称 |
| outputFields | 输入节点传递过来的字段名称, 格式:field1;field2;field3 |
| renameOutputFields | 字段映射关系,格式:指标=B;年度=C;地区=D 字段名称=第几列 多个字段之间用分号分隔 |
| metadataRow | 输出EXCEL文件中第几行输出字段名称,如:数字1代表是第1行 开始写字段名称 |
| appendRow | true代表追加记录模式,false代表覆盖模式。 |
<Node id="XLS_WRITER_01" type="XLS_WRITER" desc="输出节点2" appendRow="true" fileURL="d:/demo/test2.xlsx" startRow="3" metadataRow="2" sheetName="人员信息" outputFields="c1;c3;tag_1" renameOutputFields="指标=B;年度=C;地区=D" >
</Node>输入节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | MQ_CONSUMER | |
| flag | 默认值:ROCKETMQ | 支持rocketmq |
| nameServer | mq服务器地址,格式:127.0.0.1:8080 | |
| group | mq组名称 | |
| topic | 订阅主题名称 | |
| tag | 标签名称,格式:*代表消费全部标签, tag_1代表只消费tag_1标签 |
<Node id="MQ_CONSUMER_02" type="MQ_CONSUMER" flag="ROCKETMQ" nameServer="127.0.0.1:8080" group="group_1" topic="out_event_user_info" tag="*"></Node>输出节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | MQ_PRODUCER | |
| flag | 默认值:ROCKETMQ | 支持rocketmq |
| nameServer | mq服务器地址,格式:127.0.0.1:8080 | |
| group | mq组名称 | |
| topic | 订阅主题名称 | |
| tag | 标签名称,格式:tag_1 | |
| sendFlag | 发送模式,1是同步;2是异步;3是单向 | |
| outputFields | 输入节点传递过来的字段名称, 格式:field1;field2;field3 多个字段之间用分号分隔 |
|
| renameOutputFields | 字段映射关系,格式:field1;field2;field3 多个字段之间用分号分隔 |
<Node id="MQ_PRODUCER_01" type="MQ_PRODUCER" flag="ROCKETMQ" nameServer="127.0.0.1:8080" group="group_11" topic="out_event_system_user" tag="tag_1"
sendFlag="3" outputFields="time;tag_1;c2" renameOutputFields="时间;设备;指标" >
</Node>将一个输入节点的数据流输出到多个分支输出节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | COPY_STREAM |
<Node id="COPY_STREAM_01" type="COPY_STREAM" desc="数据流拷贝节点" ></Node>
<Line id="LINE_01" type="STANDARD" from="DB_INPUT_01" to="COPY_STREAM_01" order="1" metadata="METADATA_01" ></Line>
<Line id="LINE_02" type="COPY" from="COPY_STREAM_01:0" to="DB_OUTPUT_01" order="2" metadata="METADATA_01"></Line>
<Line id="LINE_03" type="COPY" from="COPY_STREAM_01:1" to="DB_OUTPUT_02" order="2" metadata="METADATA_02"></Line>输入节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | REDIS_READER | |
| nameServer | 127.0.0.1:6379 | |
| password | ****** | |
| db | 0 | 数据库ID |
| isGetTTL | true或false 是否读取ttl信息 | |
| keys | 读取的KEY,多个KEY之间用分号分隔 | 目前只支持读取string,int,float类型内容 |
<Node id="REDIS_READER_01" type="REDIS_READER" desc="输入节点1"
nameServer="127.0.0.1:6379" password="******" db="0" isGetTTL="true" keys="a1;a_1" ></Node>输出节点,因key名称不可重复,所以只适合将读节点中的最后一行记录进行写入操作
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | REDIS_WRITER | |
| nameServer | 127.0.0.1:6379 | |
| password | ****** | |
| db | 0 | 数据库ID |
| isGetTTL | true或false 是否写入ttl信息 | |
| outputFields | 目前只支持写string,int,float类型内容 | |
| renameOutputFields | 目前只支持写string,int,float类型内容 |
<Node id="REDIS_WRITER_01" type="REDIS_WRITER" desc="输出节点1" nameServer="127.0.0.1:6379" password="******" db="1"
isGetTTL="true" outputFields="a1;a_1" renameOutputFields="f1;f2" ></Node>自定义节点,可以通过嵌入GO脚本实现各种操作
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | CUSTOM_READER_WRITER |
输入节点-执行系统脚本节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | EXECUTE_SHELL | |
| fileURL | 外部脚本文件位置 | fileURL与Script两者只能出现一个,同时出现时fileURL优先于Script |
| Script | 脚本内容 | |
| outLogFileURL | 控制台输出内容到指定的日志文件 |
<Node id="EXECUTE_SHELL_01" type="EXECUTE_SHELL" desc="节点1" _fileURL="d:/test1.bat" outLogFileURL="d:/test1_log.txt">
<Script><![CDATA[
c:
dir/w
]]></Script>
</Node>输入节点-读取CSV文件节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | CSV_READER | |
| fileURL | CSV文件位置 | |
| fetchSize | 每次读取到内存中的批量数 | 如:可配合influxdb中每次批量提交的记录数 |
| startRow | 从第几行开始读数据,默认0代表第1行 | 一般0是第一行列名称 |
| fields | 定义输出的字段名称,多个字段间用分号分隔 | field1;field2;field3 |
| fieldsIndex | 定义输出的列,默认0代表第1列,多个字段间用分号分隔 | "2;3;4" |
<Node id="CSV_READER_01" type="CSV_READER" desc="输入节点1" fetchSize="5" fileURL="d:/demo2.csv" startRow="1" fields="field1;field2;field3" fieldsIndex="0;3;4">
</Node>
元数据文件定义目标数据格式(如输出节点中定义的renameOutputFields或renameOutputTags所对应的字段名称及字段类型)
outputFields是输入节点中数据结果集中的字段名称, 将outputFields定义的字段转换成renameOutputFields定义的字段,其renameOutputFields转换格式通过元数据文件来定义。
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| field | ||
| name | 输出数据源的字段名称 | renameOutputFields, renameOutputTags |
| type | 输出数据源的字段类型 | string,int,int32,float, str_timestamp,decimal |
| default | 默认值 | 当nullable为false时,如果输出值为空字符串,则可以通过default来指定输出的默认值 |
| nullable | 是否允许为空 | false不允许为空,必须和default配合使用。true允许为空。 |
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | 数据源类型 | INFLUXDB_V1、MYSQL、CLICKHOUSE |
| dbURL | 连接地址 | ck,mysql,influx |
| database | 数据库名称 | ck,mysql,influx |
| username | 用户名称 | ck,mysql,influx |
| password | 密码 | ck,mysql,influx |
| token | token名称 | influx 2x |
| org | 机构名称 | influx 2x |
| rp | 数据保留策略名称 | influx 1x |
| 属性 | 说明 | 适合 |
|---|---|---|
| runMode | 1串行模式;2并行模式 | 默认推荐使用并行模式, 如果需要各流程排序执行,可使用串行模式 |
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| from | 输入节点唯一标示 | |
| to | 输出节点唯一标示 | |
| type | STANDARD 标准,一进一出,COPY 复制数据流,中间环节复制数据 | |
| order | 串行排序号,按正整数升序排列,在graph属性runMode为1时, 通过配置0,1,2这种方式实现串行执行 |
|
| metadata | 目标元数据ID |
run_graph -fileUrl ./global6.xml -logLevel debug arg1="d:/test3.xlsx" arg2=上海其中 arg1和arg2是从命令行传递进来的全局变量
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="500">
<Script name="sqlScript"><![CDATA[
select * from (select * from t5 where tag_1='${arg2}' limit 1000)
]]></Script>
<Node id="XLS_WRITER_01" type="XLS_WRITER" desc="输出节点2" appendRow="true" fileURL="${arg1}" startRow="3" metadataRow="2" sheetName="人员信息" outputFields="c1;c3;tag_1" renameOutputFields="指标=B;年度=C;地区=D" >
配置文件中${arg1} 会在服务运行时通过命令行参数arg1的值d:/test3.xlsx被替换掉
配置文件中${arg2} 会在服务运行时通过命令行参数arg2的值 上海 被替换掉
可以嵌入自己的业务逻辑
可以增加多个字段,并赋予默认值
package ext
import (
"errors"
"fmt"
"strconv"
)
func RunScript(dataValue string) (result string, topErr error) {
newRows := ""
rows := gjson.Get(dataValue, "rows")
for index, row := range rows.Array() {
//tmpStr, _ := sjson.Set(row.String(), "addCol1", time.Now().Format("2006-01-02 15:04:05.000"))
tmpStr, _ := sjson.Set(row.String(), "addCol1", "1")
tmpStr, _ = sjson.Set(tmpStr, "addCol2", "${arg2}")
newRows, _ = sjson.SetRaw(newRows, "rows.-1", tmpStr)
}
return newRows, nil
}
可以将多个字段合并为一个字段
package ext
import (
"errors"
"fmt"
"strconv"
)
func RunScript(dataValue string) (result string, topErr error) {
newRows := ""
rows := gjson.Get(dataValue, "rows")
for index, row := range rows.Array() {
area := gjson.Get(tmpStr,"tag_1").String()
year := gjson.Get(tmpStr,"c3").String()
tmpStr, _ = sjson.Set(tmpStr, "tag_1", area + "_" + year)
newRows, _ = sjson.SetRaw(newRows, "rows.-1", tmpStr)
}
return newRows, nil
}