DEMO VIDEO : https://drive.google.com/file/d/1_6YDqa-G6f9koklkF4l-gUpWczeDHJiu/view?usp=share_link
Data Used in the story : https://drive.google.com/file/d/1ys6sjFvYf2-DEF1W6RgKI7B5hM5Ap3mE/view?usp=share_link
Fraud prevention in the banking and financial services industry is the process of identifying, preventing and mitigating fraudulent activities to protect customers' assets and the financial institution's reputation. Banks and other financial institutions are particularly vulnerable to fraud because they handle large amounts of sensitive financial information and transactions.
The approch taken to solve the above use case heavily relies on stream processing. We have provided this git to process the transaction using MDB spark streaming connector as in Architecture 1. Also we present an alternative approach using confluent and kafka stream for processing stream data in Architecture 2(No code provided for the same in this git hub)

The high level architecture components for implementing the real time fraud detection model is as below:
- Producer apps & SQL data source : The producer app is a simulator that mimics generation of transactions. The SQL source has been included as a sample operational data source that holds customer demographics
- MongoDB Atlas: Atlas serves as the core persistence layer and stores the raw transactions, the transactions flagged as fraud as well as customer demographics information.
- Fraud detection layer on Databricks: The core fraud detection algorithm is a reference notebook provided by Databricks. MLFlow has been used to manage the MLOps for this model. The trained model is available as a REST endpoint. The model is also operating on a Delta live table to provide batch/ real time predictive analytics. Deltalake has been used as the persistence on Databricks
- MongoDB Atlas Appservices: Altas Appservice help manager the trigger function to listen to the featurized transaction collection and tag the transactions in realtime by invoking the AI/ML REST endpoint in Databricks.

In this architecture, Kafka is utilized as an alternative solution for transferring and streaming data from various source and used for model management.
-
Confluent/Kafka: Data is generated from various sources, including customer transactions and demographics, merchant information, and training data. This data is processed and transferred to Confluent, which writes it to different Kafka topics. Kafka is used for its durability, scalability, and fault-tolerance, ensuring that data is stored securely and can be accessed reliably. MongoDB Atlas uses the Kafka sink connector to persist the data, allowing businesses to gain valuable insights and make informed decisions. Refer the following documentation for more details on Kafka connectors available for MongoDb and Databricks.
-
Transaction Prediction Service: This is a middleware which uses persisted data in MongoDB for model management, enabling organizations to make predictions and gain insights based on the data. This service streamlines workflows and optimizes decision-making processes, helping businesses stay ahead of the curve.
-
Trains and Registers a Model based on Rules
-
Trains and Registers a Model based on Classification using XGB.

-
Load Realtime data from mongodb > extract features > write to mongodb
-
Load one time batch data incrementally to train model
Using MongoDB Spark Connector load historical transactions data from MongoDB fraud-detection.txn_data collection to Delta live tables. This is one time dump run each time to update the Delta live table (DLT) with new transactions that have been processed between subsequent runs of this step. This stage helps extracting relevant features from the raw transactions data and create a featurized view to be easily consumed for ML model training. Also The DLT is registered as Feature store. This help maintain,verisoning, lineage for features created over time.
raw transaction data in mongodb
 processed trainsaction in feature store
processed trainsaction in feature store

We build a simple XGB classifier over the extracted features stored in the feature store. Using the MLflow we are able to track num of estimators used for modelling, ,model accuracy, auc to maitain details of various interations and also monitor the model performance over time. Based on the performance of the model run we promote the model to staging enviroment and post testing all the integration steps the model can be promoted to production enviroment.
Model Run Info

Model Run Registry

Similar to the previous XGB model run. We can wrap the xgb model with some user set rule on user application to validate transactions. The model first executes the rule check by using cc_num and make a request to fraud-detection.usr_auth_rule_data collection to fetch use specific and validate the transaction features against the same. Once all the rules are satificatorily processed the transaction is verified using the XGB model built above. The combined model now is registered using ML flow. This help is versioning and maintaining various rule features introduced/removed/changed over time.
Example view of rule collection

Rule Model Execution Flow

Create two workflows one for model training activity and second for realtime processing of transactions. The second workflows are continously running jobs whereas the model training worflow is scheduled to run at regular intervals. Follow steps in link to create new worflow
Once successfully created workflow will look as follows
Model training workflow

Streaming Worflow

Reads the processed_transaciton DLT stream continuously and write into mongo collection.
-
transactions Inserts all the raw transactions as it is received from the simulator.
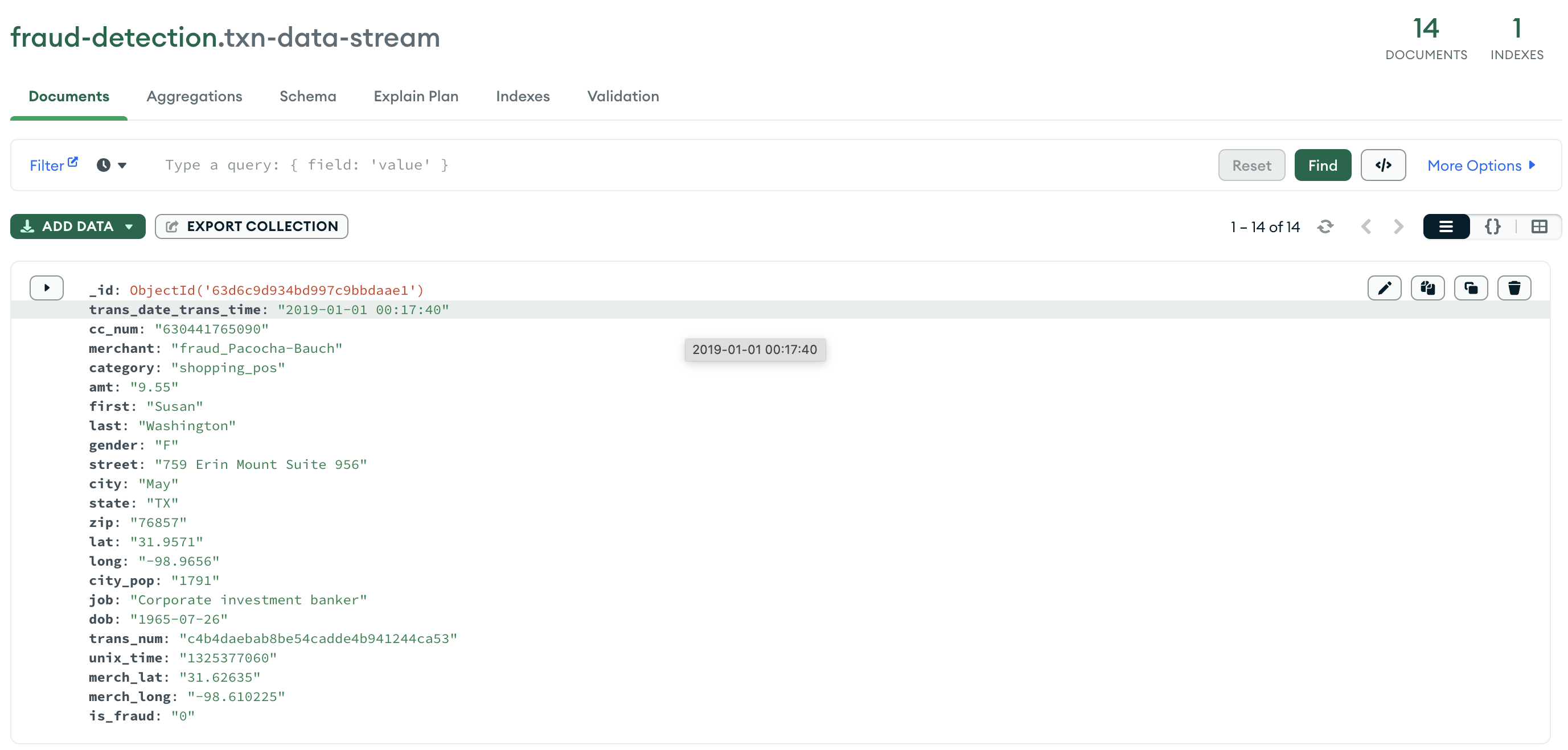
-
processed transactions post feature transformation : Inserts the processed transaction run against the feature extraction. This collection would have a featurized view of the raw transaction to be used for classificaiton of the txn a fradulent or not. Against this collection we set the tigger function. Upon insert or update on this collection we use the Appservice txnpred func to call the classifier.
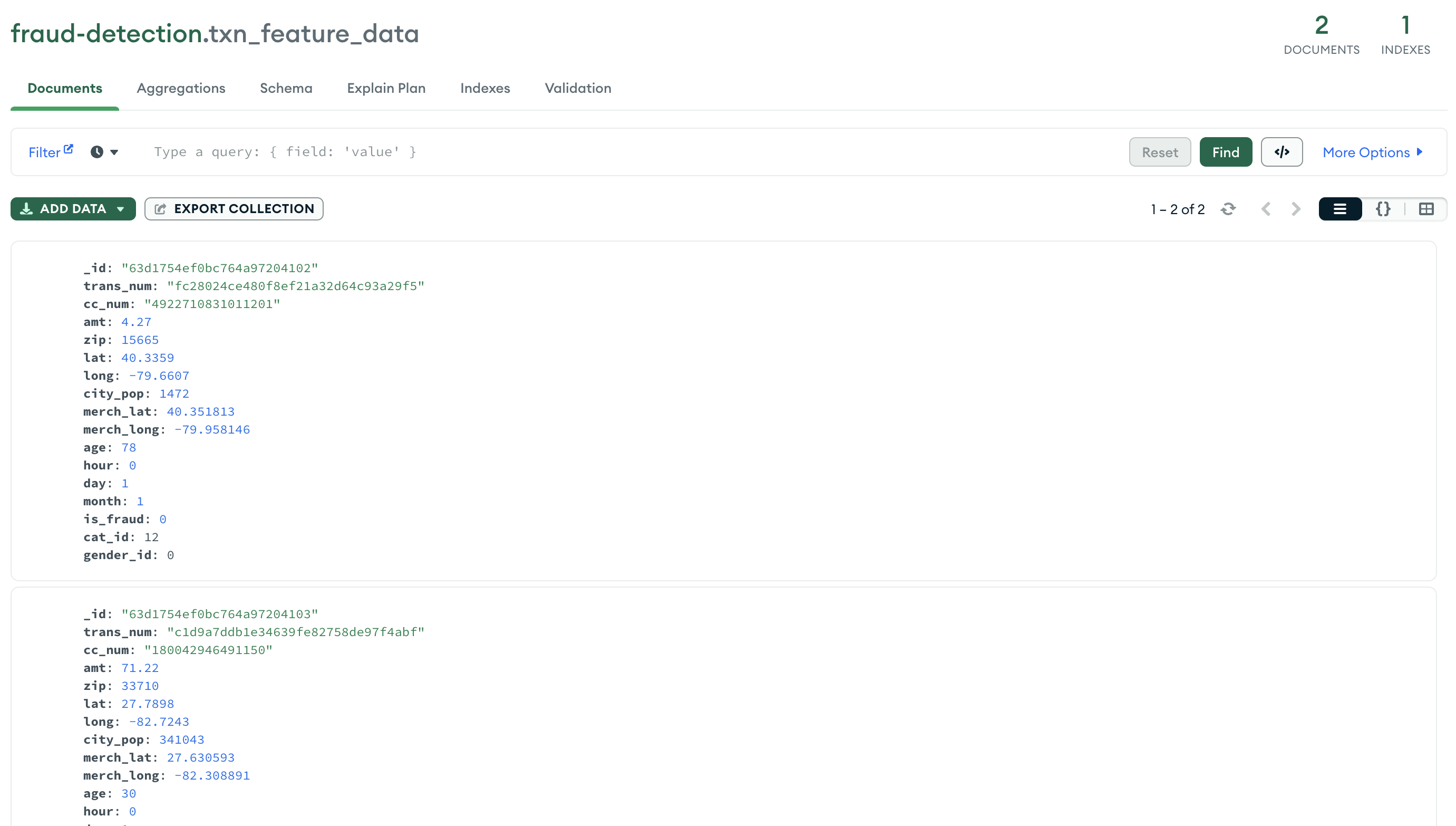
-
transaction status table :
The pred function from Atlas App service inserts the processed transaction run against the classification model. This collection would have a transaction status column added to show the prediction value when run against the transaction record, also carries the transaction number for identification.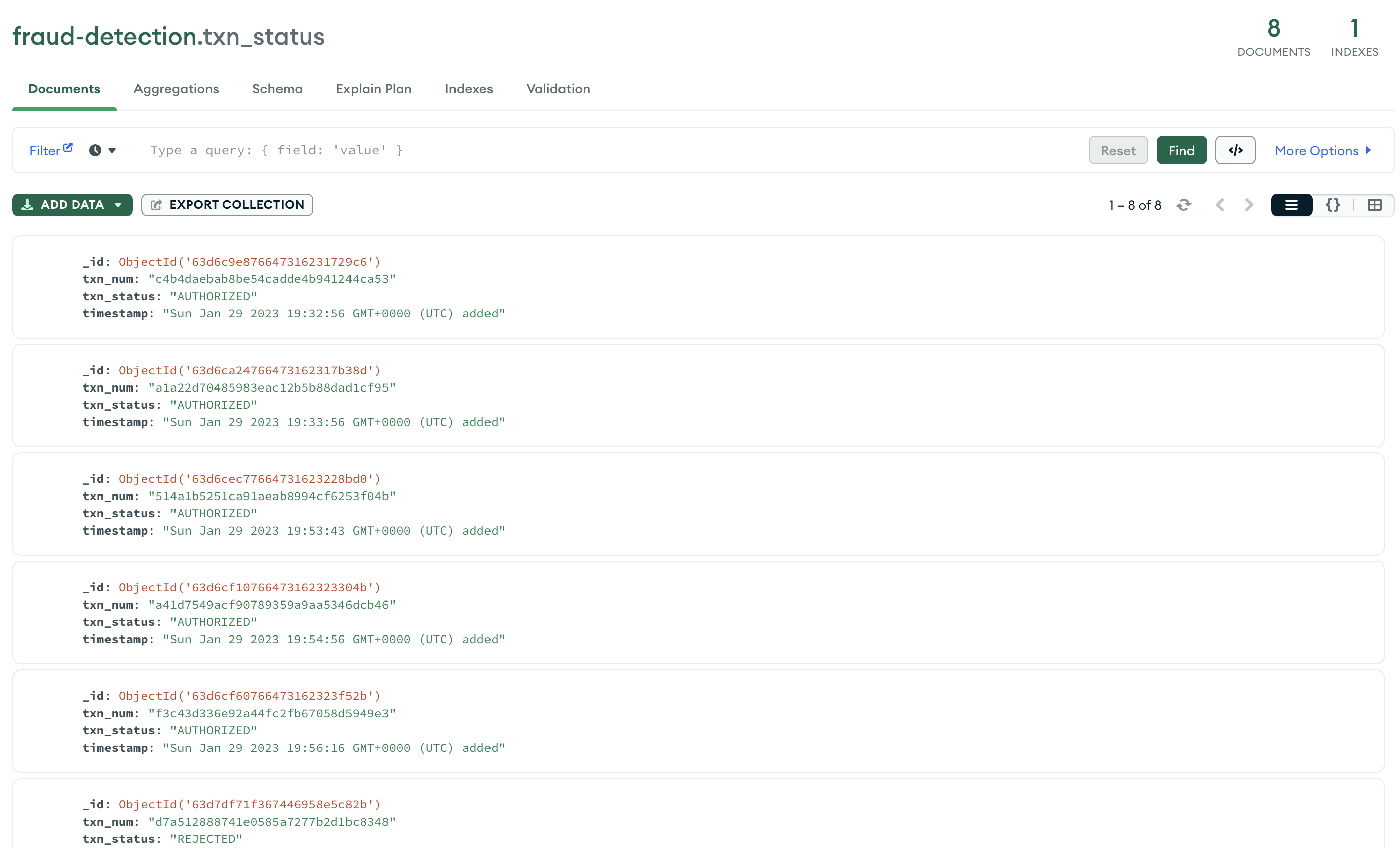



A simple python program to simulate the Transaction of record being inserted every 1 min. It randomly generates valid/fraud transactions and inserts them to the raw transactions.
Databricks can serve the models as REST endpoints. The Models are setup in a cluster. The size of which can be changed by the user based on the need.
Below is a snapshot of the REST Endpoint exposed in a m5.xa.large cluster.

Since the endpoint are exposed via REST the Authentication key can be generated from the databricks as shown below

The rule model registered in the model registry is exposed as REST endpoints as shown below
RULE BASED MODEL : https://dbc-ca6bc27a-67f7.cloud.databricks.com/model/fraud_rule_model/Staging/invocations

A Simple javascript program writtien as function under MongoDB Atlas App services to listen to the transactions features collections using set Atlas triggers. Once triggered the trigger invoke the rule model REST API's exposed and update the fraud_detection.txn_status collection.
Setting Atlas triggers
The Code to trigger function used in this demo

Create a trigger function as shown in the steps above and add the code in the function block.