![]()

Retrieve images based on a query (text or image), using Open AI's pretrained CLIP model.
Text as query.

Image as query.

CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can map images and text into the same latent space, so that they can be compared using a similarity measure.
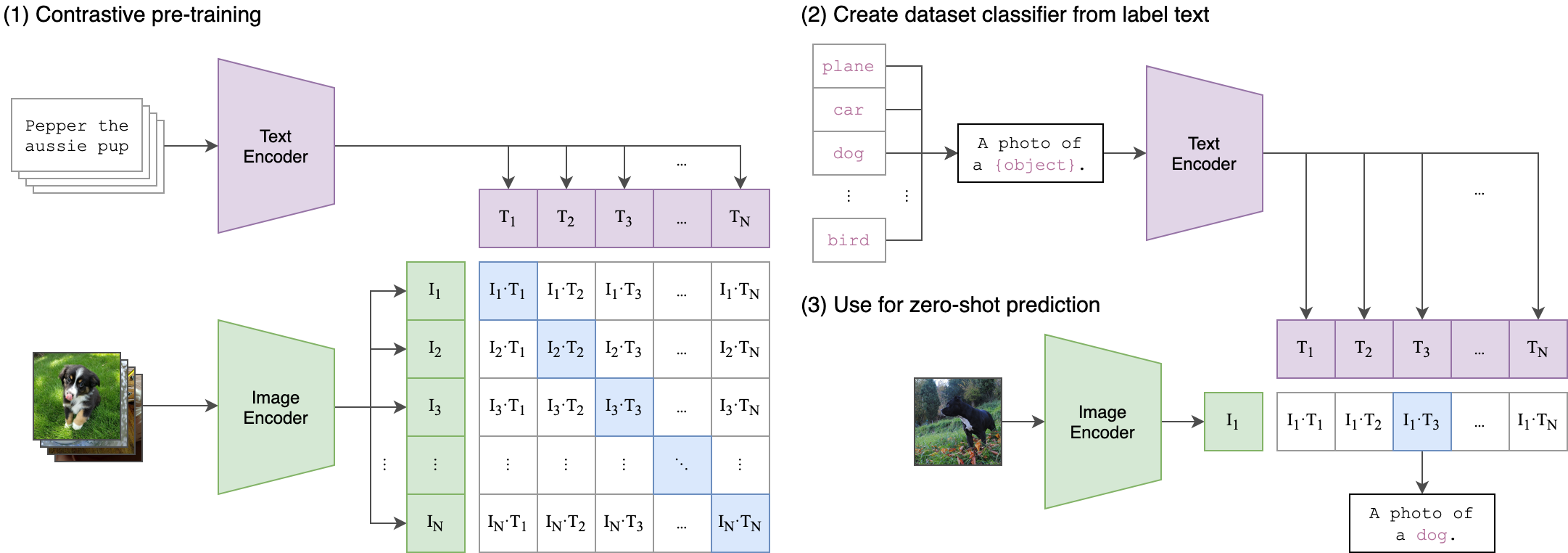
Extending the work in this repository, I created a simple image search engine that can take both text and images as query. The search engine works as follows:
- Use the image encoder to compute the feature vector of the images in the dataset.
- Index the images in the following format:
image_id: {"url": https://abc.com/xyz, "feature_vector": [0.1, 0.3, ..., 0.2]} - Compute the feature vector of the query. (Use text encoder if query is text. Use image encoder if query is image.)
- Compute the cosine similarities between the feature vector of the query and the feature vector of the images in the dataset.
- Return
$k$ images that have the highest similarity.
I used the lite version of the Unsplash dataset that contains 25,000 images. The k-Nearest Neighbor search is powered by Amazon Elasticsearch Service. I deployed the query service as an AWS Lambda function and put an API gateway in front of it. The frontend is developed using Streamlit.
- The feature vector outputted by CLIP is a 32-bit floating point vector with 512 dimensions. To reduce storage cost and increase query speed, we may consider using a dimension reduction technique such as PCA to reduce the number of features. If we want to scale the system to billions of images, we may even consider binarizing the features, as is done in Pinterest.
pip install -e . --no-cache-dir
python scripts/download_unsplash.py --image_width=480 --threads_count=32
This will download and extract a zip file that contains the metadata about the photos in the dataset. The script will use the URLs of the photos to download the actual images to unsplash-dataset/photos. The download may fail for a few images (see this issue). Since CLIP will downsample the images to 224 x 224 anyway, you may want to adjust the width of the downloaded images to reduce storage space. You may also want to increase the threads_count parameter to achieve a faster performance.
python scripts/ingest_data.py
The script will download the pretrained CLIP model and process the images by batch. It will use GPU if there is one.
Build Docker image for AWS Lambda.
docker build --build-arg AWS_ACCESS_KEY_ID=YOUR_AWS_ACCESS_KEY_ID \
--build-arg AWS_SECRET_ACCESS_KEY=YOUR_AWS_SECRET_ACCESS_KEY \
--tag clip-image-search \
--file server/Dockerfile .
Run the Docker image as a container.
docker run -p 9000:8080 -it --rm clip-image-search
Test the container with a POST request.
curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{"query": "two dogs", "input_type": "text"}'
streamlit run streamlit_app.py