發現前面爬蟲寫得有夠雜亂的,重新來寫過一個連沒用過的人都能一起實做的筆記吧!
crawler with BS4~ step by step .
找一個範例網站來練習吧!
To find a website to practice !
url:心靈雞湯(http://www.coffeearticle.com/archives/category/心靈雞湯)
python==3.6.0
beautifulsoup4==4.5.3
requests==2.13.0
(版本應該沒有太大影響,不過還是先記錄一下)
(sometimes, version different is a problem ,so write here)
確認過自己環境有pip install 以上工具後,就可以來進行初步測試了!
import requests
html = 'http://www.coffeearticle.com/archives/category/心靈雞湯'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
re = requests.get(html, headers = headers)
print(re)回傳200代表正常訪問的意思。
(200 means correct response)
<Response [200]>
但我們要的是內文,所以print(re.text)就能顯示內文 but we need the content ,so print(re.text).
import requests
html = 'http://www.coffeearticle.com/archives/category/心靈雞湯'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
re = requests.get(html, headers = headers)
print(re.text)<!DOCTYPE html>
<!--[if IE 8]><html class="ie8"><![endif]-->
<!--[if IE 9]><html class="ie9"><![endif]-->
<!--[if gt IE 8]><!--> <html lang="zh-TW" xmlns:og="http://ogp.me/ns#" xmlns:fb="http://ogp.me/ns/fb#"> <!--<![endif]-->
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<meta name="viewport" content="user-scalable=yes, width=device-width, initial-scale=1.0, maximum-scale=1, minimum-scale=1">
<!--[if lt IE 9]>
<script src="http://www.coffeearticle.com/wp-content/themes/voice/js/html5.js"></script>
<![endif]-->
<title>心靈雞湯 – 一杯咖啡一篇文章</title>
<link rel='dns-prefetch' href='//fonts.googleapis.com' />
<link rel='dns-prefetch' href='//s.w.org' />
<link rel="alternate" type="application/rss+xml" title="訂閱 一杯咖啡一篇文章 »" href="http://www.coffeearticle.com/feed"
==========================================
....下面內容省略....
==========================================
網站爬蟲都會有一定的規律性,有些是重複的東西,例如HTML標籤(img、a、div、button) 或是標籤的屬性(class、id、href、title)
crawler have rules on website , to find same HTML Attr or Class .
我想爬這個網站的全部文章"標題"為目標應該怎麼辦呢?
if my target is all article "title" on this website , how I gonna do ?
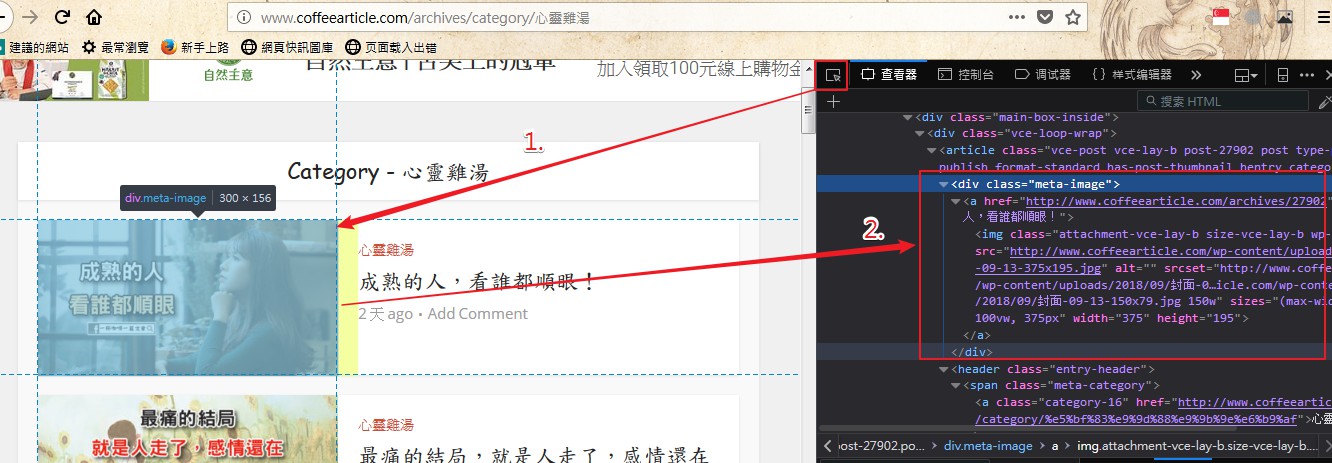
 查找規則需要用到瀏覽器,這邊使用firefox來查看,按下"F12"可以使用查找元素功能找到想找的範圍
查找規則需要用到瀏覽器,這邊使用firefox來查看,按下"F12"可以使用查找元素功能找到想找的範圍
you need the browser to find rules , I use the firefox browser to find it, press "F12" can search for elements .
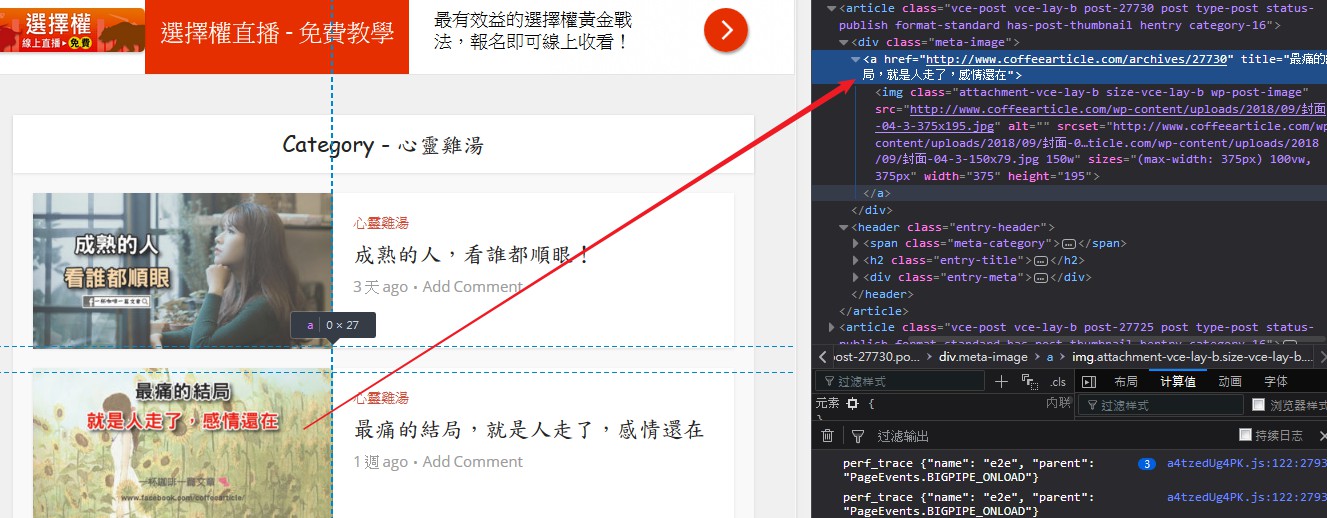
發現每個文章正被一個
這時候beautifulsoup可以登場了 我後面 as 命名為BS4 比較簡短
now, beautifulsoup come in , and as name "BS4"
from bs import Beautifulsoup as BS4把剛剛的re.text內文丟給BS4,並使用 .find_all(查找class名字為"meta-image")的class屬性。
soup = BS4(re.text)
print(soup.find_all(class_='meta-image'))import requests
from bs4 import BeautifulSoup as BS4
html = 'http://www.coffeearticle.com/archives/category/心靈雞湯'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
re = requests.get(html, headers = headers)
soup = BS4(re.text)
print(soup.find_all(class_='meta-image'))嘗試將過濾的內容印出來看看。
try to print the fliter content.
[<div class="meta-image">
<a href="http://www.coffeearticle.com/archives/27902" title="成熟的人,看誰都順眼!">
<img alt="" class="attachment-vce-lay-b size-vce-lay-b wp-post-image" height="195" sizes="(max-width: 375px) 100vw, 375px" src="http://www.coffeearticle.com/wp-content/uploads/2018/09/封面-09-13-375x195.jpg" srcset="http://www.coffeearticle.com/wp-content/uploads/2018/09/封面-09-13-375x195.jpg 375w, http://www.coffeearticle.com/wp-content/uploads/2018/09/封面-09-13-150x79.jpg 150w" width="375"/> </a>
</div>, <div class="meta-image">
<a href="http://www.coffeearticle.com/archives/27730" title="最痛的結局,就是人走了,感情還在">
<img alt="" class="attachment-vce-lay-b size-vce-lay-b wp-post-image" height="195" sizes="(max-width: 375px) 100vw, 375px" src="http://www.coffeearticle.com/wp-content/uploads/2018/09/封面-04-3-375x195.jpg" srcset="http://www.coffeearticle.com/wp-content/uploads/2018/09/封面-04-3-375x195.jpg 375w, http://www.coffeearticle.com/wp-content/uploads/2018/09/封面-04-3-150x79.jpg 150w" width="375"/> </a>
</div>, <div class="meta-image">
<a href="http://www.coffeearticle.com/archives/27725" title="一輩子不容易,惟有擁有這10種心態,才能活得簡單快樂">
<img alt="" class="attachment-vce-lay-b size-vce-lay-b wp-post-image" height="195" sizes="(max-width: 375px) 100vw, 375px" src="http://www.coffeearticle.com/wp-content/uploads/2018/09/封面-09-7-375x195.jpg" srcset="http://www.coffeearticle.com/wp-content/uploads/2018/09/封面-09-7-375x195.jpg 375w, http://www.coffeearticle.com/wp-content/uploads/2018/09/封面-09-7-150x79.jpg 150w" width="375"/> </a>
</div>,
==========================================
....中間內容省略....
==========================================
, <div class="meta-image">
<a href="http://www.coffeearticle.com/archives/27469" title="從前的我,現在的我(讀到心酸)">
<img alt="" class="attachment-vce-lay-b size-vce-lay-b wp-post-image" height="195" sizes="(max-width: 375px) 100vw, 375px" src="http://www.coffeearticle.com/wp-content/uploads/2018/08/封面-09-82-375x195.jpg" srcset="http://www.coffeearticle.com/wp-content/uploads/2018/08/封面-09-82-375x195.jpg 375w, http://www.coffeearticle.com/wp-content/uploads/2018/08/封面-09-82-150x79.jpg 150w" width="375"/> </a>
</div>]
再將剛剛的資料丟到for迴圈 並將各別資料以標籤a的title內容印出。
print "a" of elements's title Attr through forloop.
import requests
from bs4 import BeautifulSoup as BS4
html = 'http://www.coffeearticle.com/archives/category/心靈雞湯'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
re = requests.get(html+pages+str(num), headers = headers)
soup = BS4(re.text)
for i in soup.find_all(class_='meta-image'):
print(i.a['title'])成熟的人,看誰都順眼!
最痛的結局,就是人走了,感情還在
一輩子不容易,惟有擁有這10種心態,才能活得簡單快樂
寫給漸漸老去的自己
懂事的人最委屈,一定要看看的
低調做人,你的路會越走越穩健
一輩子真的好難….
你越覺得你好運,你就越容易吸引到對的人
懂得感恩,才有一切
從前的我,現在的我(讀到心酸)
接下來發現另一個規則:
下一頁開始網址變成 url/page/2 ,依此類推 第三頁是 url/page/3
所以就改一下前面的網址。
found next rules :
next page is url/page/2 , example : page 3 is url/page/3
so edit the html rul .
html = 'http://www.coffeearticle.com/archives/category/心靈雞湯'
pages = '/page/'
num = 1
re = requests.get(html+pages+str(num), headers = headers)通常文章都是最新的在第一頁
如果想要從最後面到最前面要怎麼寫迴圈呢?
usually , the newest article on first page , if I want to crawler data from last page to first page ,how ?
使用 reversed() 這個python 函式 ,可以把數字從最後印回到最前面。
Use the reversed() to reversed number
import requests
from bs4 import BeautifulSoup as BS4
html = 'http://www.coffeearticle.com/archives/category/心靈雞湯'
pages = '/page/'
num = 1
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
for i in reversed(range(1,5)):
print(' ')
print('目前頁數:',i)
re = requests.get(html+pages+str(i), headers = headers)
soup = BS4(re.text)
for i in soup.find_all(class_='meta-image'):
print(i.a['title'])
目前頁數: 4
生活順其自然,老天自有安排
做人要真(深度好文)
不隨意評價別人,是一種修養;不活在別人的評價里,也是一種修行!
人生長路漫漫,且行且珍惜。
逼出來的堅強,忍出來的性格!
心寬是福,看淡是樂(寫的真好)
轉變一下思維,就可使人絕處逢生
有格局的聰明人:彎腰不是認輸,而是為了拾起 丟掉的幸福!
累了,就放空自己
人活多久,吃多少,穿多好,富貴還是貧窮,命裡早已註定
目前頁數: 3
有一種安全感,叫靠自己
人怎麼待我,我就怎麼待人!
真正聰明人,從不吵架 (深度好文)
找一個和你頻率相同的人
小時候,幸福很簡單;長大了,簡單很幸福
心累 (寫的真好)
站在人群,我毫不起眼;活在世上,我不玩心眼(送給簡單正直的你)
對自己好點,別活得太累了
那些沉默的人,看似很平凡,往往是「狠角色」!
不要狠心傷害,真心在乎你的人!
目前頁數: 2
目中有人才有路,心中有愛才有度
把一切看淡,心就不累了
即使老了,也要老的漂亮
一輩子,什麼最重要?(句句在理)
來時一絲不掛,去時一縷青煙,人就這麼簡單
有些心事,無人能懂..
成長是一個很痛的名詞,時間能看清一切!
有些滄桑,自己懂就好
心裡委屈,想要發洩時,看看這5句話,你會好受很多!
自己的人生,自己決定!尤其是「女人」做不了公主,就做自己的女王!
目前頁數: 1
成熟的人,看誰都順眼!
最痛的結局,就是人走了,感情還在
一輩子不容易,惟有擁有這10種心態,才能活得簡單快樂
寫給漸漸老去的自己
懂事的人最委屈,一定要看看的
低調做人,你的路會越走越穩健
一輩子真的好難….
你越覺得你好運,你就越容易吸引到對的人
懂得感恩,才有一切
從前的我,現在的我(讀到心酸)
這是一小部分大家有可能遇到的小問題,希望可以幫助到你~
that's small part of problem , hope it can help you~