This project applies Transformer-based model for Visual Question Answering task. In this study project, most of the work are reimplemented, some are adapted with lots of modification. The purpose of this project is to test the performance of the Transformer architecture and Bottom-Up feature.
Notebook:
The following figure gives an overview of the baseline model architectures.

- In the visual encoding stage which uses bottom-up attention, FasterRCNN is used to extract features for each detected object in the image. This method captures visual meanings with object-aware semantics.
| Bottom-Up Encoder |
|---|
 |
- Answer vocabulary is built based on the all the answers in the train+val set, can be seen here.
- To extract bottom-up features, I provide Colab Notebook which adapts code from Detectron model
I train both the bottom-up models on small subset of COCO2014 dataset, Toronto COCO-QA, which contains 123,287 images, with 78,736 train questions and 38,948 test questions. Questions in this subset consist of 4 types: object, number, color, location. All answers are one-word.
For VQA data format, see VQA format
I use the evaluation metric which is robust to inter-human variability in phrasing the answers:
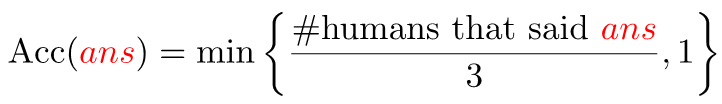
Before evaluating machine generated answers, the code do the following processing:
- Making all characters lowercase
- Removing periods except if it occurs as decimal
- Converting number words to digits
- Removing articles (a, an, the)
- Adding apostrophe if a contraction is missing it (e.g., convert "dont" to "don't")
- Replacing all punctuation (except apostrophe and colon) with a space character. We do not remove apostrophe because it can incorrectly change possessives to plural, e.g., “girl’s” to “girls” and colons because they often refer to time, e.g., 2:50 pm. In case of comma, no space is inserted if it occurs between digits, e.g., convert 100,978 to 100978. (This processing step is done for ground truth answers as well.)
Despite using only small dataset and answer vocabulary, the results look acceptable. Moreover, we can see that the Transformer model learns well and pays attention to objects in the image.
| Images | Question-Answer Pairing |
|---|---|
 |
Question: what is on the sofa ? Answer: cat (0.693) Question: what is the cat lying on ? Answer: couch (0.097) Question: what color is the cat ? Answer: orange (0.831) Question: how many cat are there on the sofa ? Answer: two (0.584) |
 |
Question: what are the people riding on ? Answer: horses (0.633) Question: how many people are there ? Answer: three (0.308) |
 |
Question: what is the woman carrying ? Answer: umbrella (0.867) Question: what is color of the dress the woman wearing ? Answer: white (0.589) |
 |
Question: what are the people in the background doing ? Answer: kites (0.426) Question: what is the kid wearing on the head ? Answer: hat (0.239) Question: what is the color of the tent ? Answer: green (0.326) Question: what is the color of the hat ? Answer: blue (0.197) |
 |
Question: what is the woman doing ? Answer: surfboard (0.358) Question: what is color of the outfit of the woman ? Answer: green (0.529) |
- To train patch-based / bottom-up architecture:
python train.py (--bottom-up)
- To evalualte trained model:
python evaluate.py --weight=<checkpoint path> (--bottom-up)
- VQA: Visual Question Answering (2015; Aishwarya Agrawal et al.)
- Bottom-Up and Top-Down Attention for Image Captioning (2018; Peter Anderson et. al)