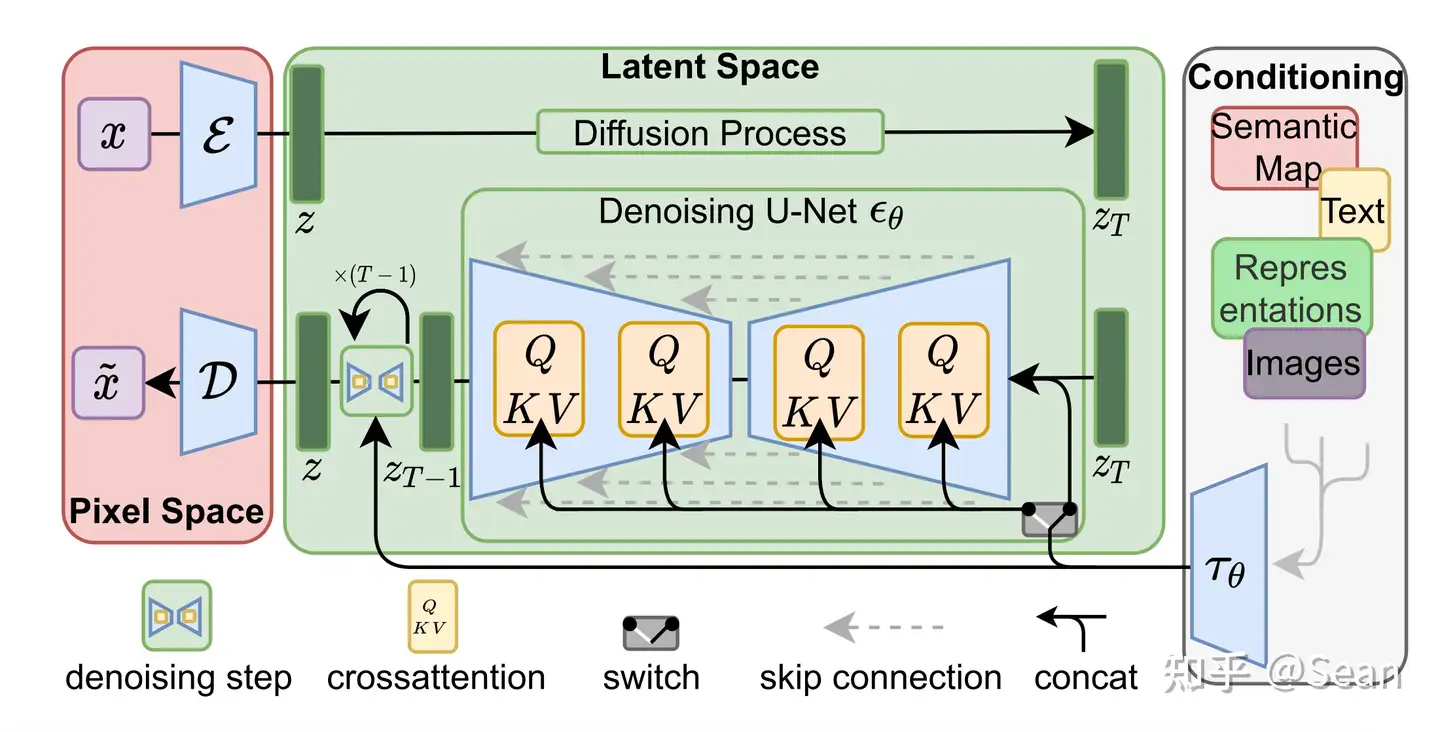
Stable Diffusion基于Latent Diffusion Models,专门用于文图生成任务。
目前,Stable Diffusion发布了v1版本,即Stable Diffusion v2.1,它是Latent Diffusion Models的一个具体实现,具体来说,它特指这样的一个模型架构设置:自动编码器下采样因子为8,UNet大小为860M,文本编码器为CLIP ViT-L/14。
-
Diffusion model相比GAN可以取得更好的图片生成效果,然而该模型是一种自回归模型,需要反复迭代计算,因此训练和推理代价都很高。论文提出一种在潜在表示空间(latent space)上进行diffusion过程的方法,从而能够大大减少计算复杂度,同时也能达到十分不错的图片生成效果。
-
相比于其它空间压缩方法(如),论文提出的方法可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。 论文将该模型在无条件图片生成(unconditional image synthesis), 图片修复(inpainting),图片超分(super-resolution)任务上进行了实验,都取得了不错的效果。
-
论文还提出了cross-attention的方法来实现多模态训练,使得条件图片生成任务也可以实现。论文中提到的条件图片生成任务包括类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。这也为日后Stable Diffusion的开发奠定了基础。
https://machinelearning.apple.com/research/neural-engine-transformers
Run Stable Diffusion on Apple Silicon with Core ML https://github.com/apple/ml-stable-diffusion
https://zhuanlan.zhihu.com/p/591136896
DECA:Learning an Animatable Detailed 3D Face Model from In-The-Wild Images
既然FLAME可微,那就直接把FLAME当作网络中间的一部分,让网络直接根据输入去预测FLAME模型的参数。下面是整体的框架:
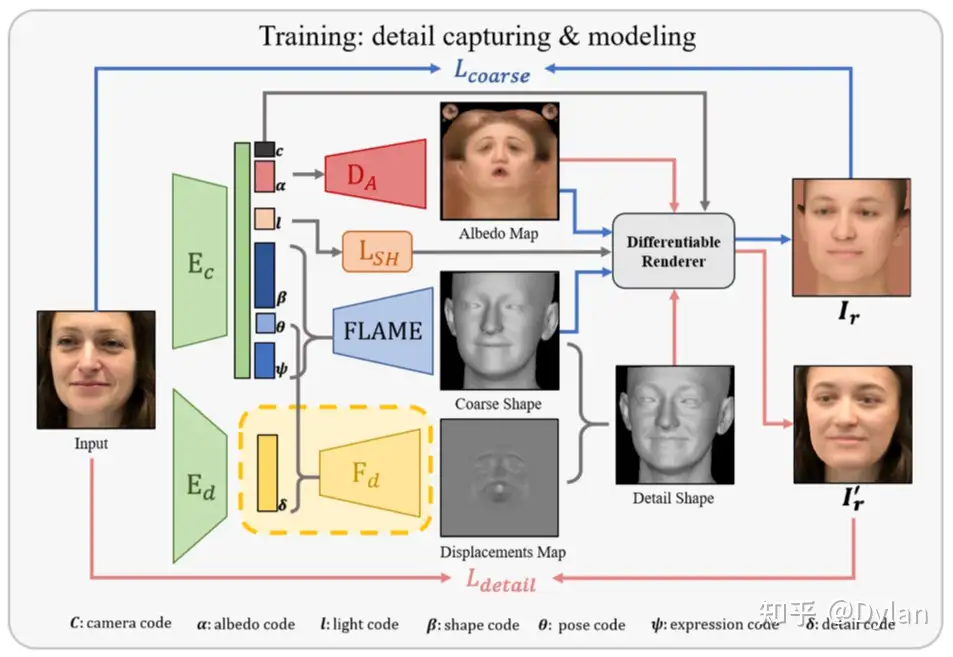
输入是单张图片:
- 经过两个不同的encoder和mapping网络,得到一系列的7个参数,包括:camera code, albedo code, light code, shape code, pose code, expression code, detail code;
- albedo code经过decoder生成texture;
- light code经过decoder得到光照系数;
- shape code, pose code, expression code经过FLAME模型得到一个粗糙的人脸mesh表示;
- detail code经过decoder得到一个更精细化的mesh偏移作用在FLAME的输出上,得到一个更精细化的人脸表示(为了建模人脸上的皱纹等细节);
- 将texture、光照系数、mesh带入进行可微渲染,得到渲染图片;
- 在渲染图片上和原始图片进行比较,计算各种loss function,包括关键点的loss、图像的loss等等;
DECA的改进:EMOCA以及MICA
在最近的DECA、EMOCA、MICA工作上我们看到计算机通过单张图片还原人头已经达到了一个非常不错的效果,也相信后续还有更多有意思的任务可以被深度学习来解锁,比如:基于FLAME精确的face tracking;多张图片合成更精细的人头;FLAME和diffusion model的结合;等等。
https://aistudio.baidu.com/aistudio/projectdetail/3220444
- 元宇宙:元宇宙(Metaverse)是利用科技手段进行链接与创造的,与现实世界映射与交互的虚拟世界,具备新型社会体系的数字生活空间。
- 三维模型:三维模型是物体的多边形表示,通常用计算机或者其它视频设备进行显示。显示的物体可以是现实世界的实体,也可以是虚构的物体。任何物理自然界存在的东西都可以用三维模型表示。三维模型的渲染显示在元宇宙中可谓是视觉方面的重中之重。先有看的发展,才会逐步发展到听、嗅、味、触等感官出现在元宇宙中。
- 可微渲染:简单的说,可微渲染就是计算渲染过程的导数。其具体的应用可以包括解决inverse rendering以及实现将渲染过程放入神经网络中以解决更复杂的视觉问题(可导性是训练网络的必要条件)。可微代表着可以求梯度,于是可以端到端的反向推导出图片对应的三维模型。
- Mesh:三维模型的多边形网格表示。使用大量空间三角形或多边形来代表物体的各个面。这种三维模型的表示方法是比较节省资源的。其它常见的表示方法有:体素表示、点云表示。因为Mesh占用存储也比较少,所以在硬件还未跟上的情况下,最适合用于元宇宙中的三维表示。
https://aistudio.baidu.com/aistudio/projectdetail/3750977?channelType=0&channel=0
-
FLAME:一个通过参数构造的人类头部三维Mesh模型生成器,可控制五官、表情、Pose等。
-
人脸三维模型重建:一个相当经典的图形学、计算机视觉任务,从一张或多张照片中重建人脸的三维模型。
-
为什么用三维建模而不是类似于stylegan之类的模型生成人脸? 因为三维模型的解耦程度高且可供其它软件查看和使用。通过GAN生成的人脸则实际上没有所谓空间属性之类的东西,无法直接使用。
DECA: Detailed Expression Capture and Animation 简介 本项目使用的便是深度学习领域当前效果最好的三维人脸重建神经网络DECA,捕获单张图片中人像对应的纹理和表情,转换为与FLAME匹配的参数,通过调节FLAME参数实现重建出对应人像的三维模型,并且可以改变其姿态和表情。
而DECA训练的背后原理并不复杂:
-
先使用人脸检测把照片中的人脸检测裁剪出来;
-
通过Resnet提取人脸的特征并转为FLAME参数和纹理潜变量以及光照;
-
FLAME参数本身可微,并且可通过运算得到Mesh网格点;
-
纹理潜变量通过可训练的生成器生成人脸的纹理;
-
将网格点和纹理、光照输入可微渲染器进行光栅化,最后渲染得到人脸图片;
-
将这张渲染图和原人脸图像做loss计算,由优化器改变参数降低loss实现端到端的训练。
将重建人脸的表情从另一个人脸上迁移过来 重建过程中产生的FLAME参数包含有姿态和表情,那么替换为他者的参数,便可以实现表情迁移啦。
https://aistudio.baidu.com/aistudio/projectdetail/3955253?channelType=0&channel=0
https://aistudio.baidu.com/aistudio/projectdetail/4596296?channelType=0&channel=0