A fast key-value store (written in Java) that is optimized to handle primitive types (integer/long/double/float) in addition to json serialized objects.
You want to use count-db if you need to write and read billions of counts very efficiëntly from a Java program. Use cases are logging large amounts of user data, counting n-grams for language models or building an index to search texts. You don't want to use count-db if you require transactions or my-sql style querying.
We compared the performance of count-db to 3 other key-value stores: levelDB, kyoto cabinet and rocksDB. count-db outperforms all three, it is for example 80 times faster than levelDB when writing 256M bigram counts and 11 times faster than levelDB when reading from these counts.
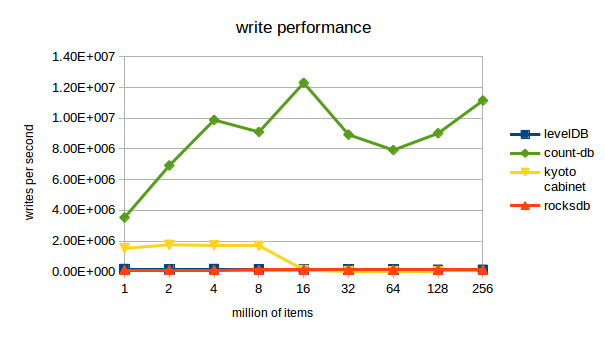
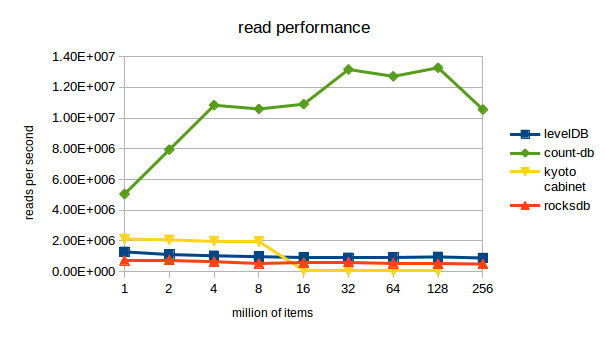
The full benchmark can be found here.
Include the following maven dependency in your project
<dependency>
<groupId>be.bagofwords</groupId>
<artifactId>count-db</artifactId>
<version>1.1.12</version>
</dependency>
Create a data interface and use it:
//create data interface factory that stores all data in /tmp/myData (This factory is wired with spring)
DataInterfaceFactory dataInterfaceFactory = new EmbeddedDBContextFactory("/tmp/myData").wireApplicationContext().getBean(DataInterfaceFactory.class);
//create data interfaces
DataInterface<Long> myLogDataInterface = dataInterfaceFactory.createCountDataInterface("myLoginCounts");
DataInterface<UserObject> myUserDataInterface = dataInterfaceFactory.createDataInterface("myUsers", UserObject.class, new OverWriteCombinator<>());
//write data
long userId = 12939;
myLogDataInterface.increaseCount("user_" + userId + "_logged_in");
myUserDataInterface.write(userId, new UserObject("koen", "deschacht", DateUtils.parseDate("1983-04-12", "yyyy-MM-dd")));
//flush data (necessary to make the written data visible on next read)
myLogDataInterface.flush();
myUserDataInterface.flush();
//read data
long numOfLogins = myLogDataInterface.readCount("user_" + userId + "_logged_in");
UserObject user = myUserDataInterface.read(userId);
System.out.println("User " + user.getFirstName() + " " + user.getLastName() + " logged in " + numOfLogins + " times.");
//iterate over all data
CloseableIterator<KeyValue<UserObject>> iterator = myUserDataInterface.iterator();
while (iterator.hasNext()) {
KeyValue<UserObject> curr = iterator.next();
UserObject currUser = curr.getValue();
long currUserId = curr.getKey();
System.out.println("User " + currUser.getFirstName() + " " + currUser.getLastName() + " with id " + currUserId);
}
iterator.close();
//drop all data
myLogDataInterface.dropAllData();
myUserDataInterface.dropAllData();For more details, see ExampleUsage.java.
If you want to use the LevelDBDataInterfaceFactory, you will need to have the snappy compression library installed on your system. For example on Ubunt 14.04 you need to run
sudo apt-get install libsnappy1