This is an end-to-end example showing how to use Kubeflow for both machine learning and model serving.
The example consists of the following steps:
- Building machine learning using Kubeflow's Jupiter The machine learning implementation is using Collaborative filtering to recommend products to the user (out of the set of products) based on his purchsing history. An implementation is first converts purchasing history to the rating matrix, based on this blog post and then uses this matrix to build a prediction model, following this repository THe actual notebook can be found here
- Once model is build, the python code is exported (see here) and is used for building TFJob. The Dockerfile is here. In addition there is a bash file.
- Model serving is based on TF-serving. Due to limitations of TF-serving I have decided to run two instances of TF-serving and alterate their usage for serving.
- KubeFlow Pipeline used to coordinate execution of steps. Notebook for creation and execution of pipeline is here. Python code
for pipeline creation is here. Once the Python code runs, it creates a file, called
pipeline.tar.gz. Following this example, the definition can be uploaded to the pipelines UI. Now we can view the pipeline there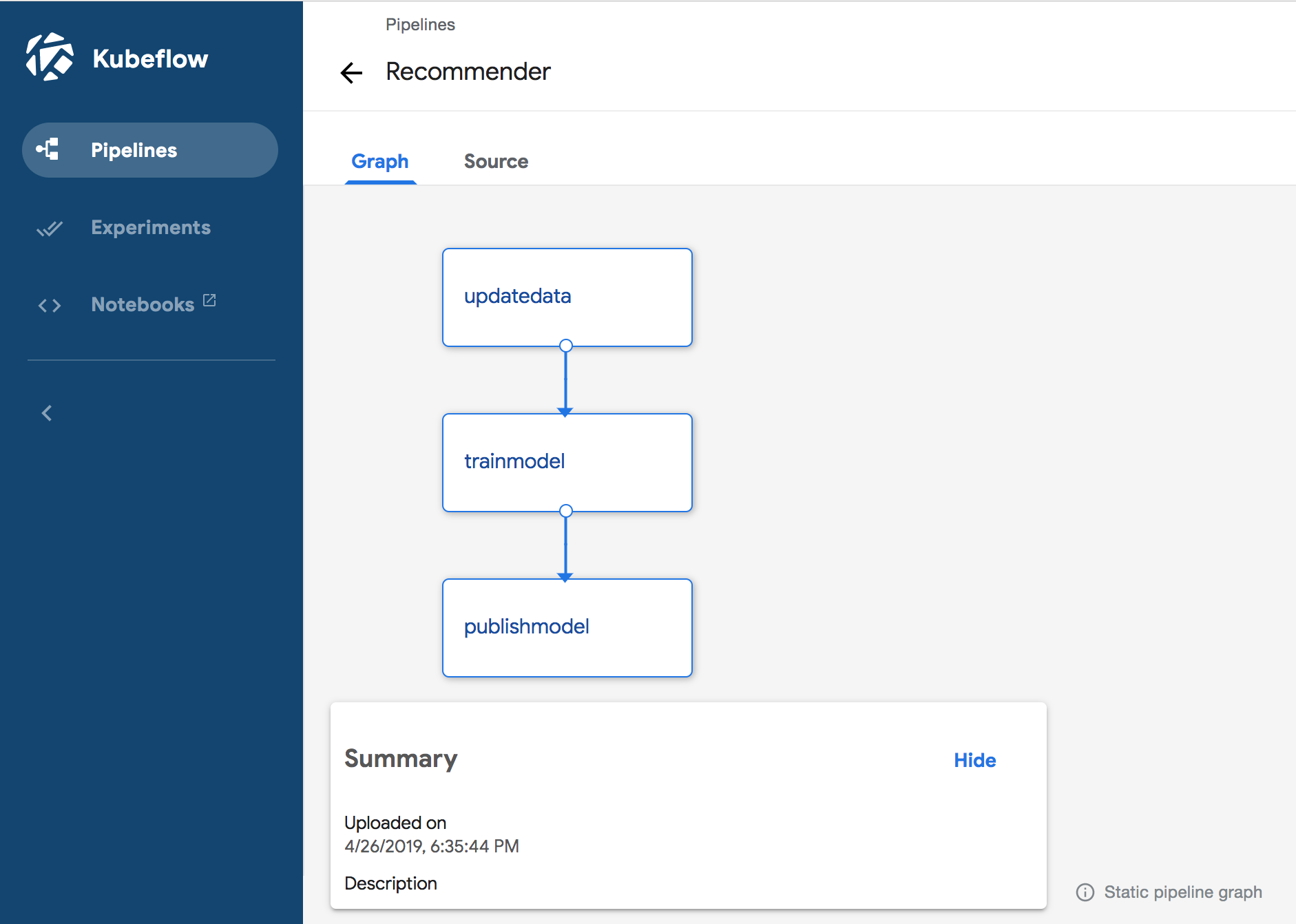 . In addition we can also run pipeline from there, that produces
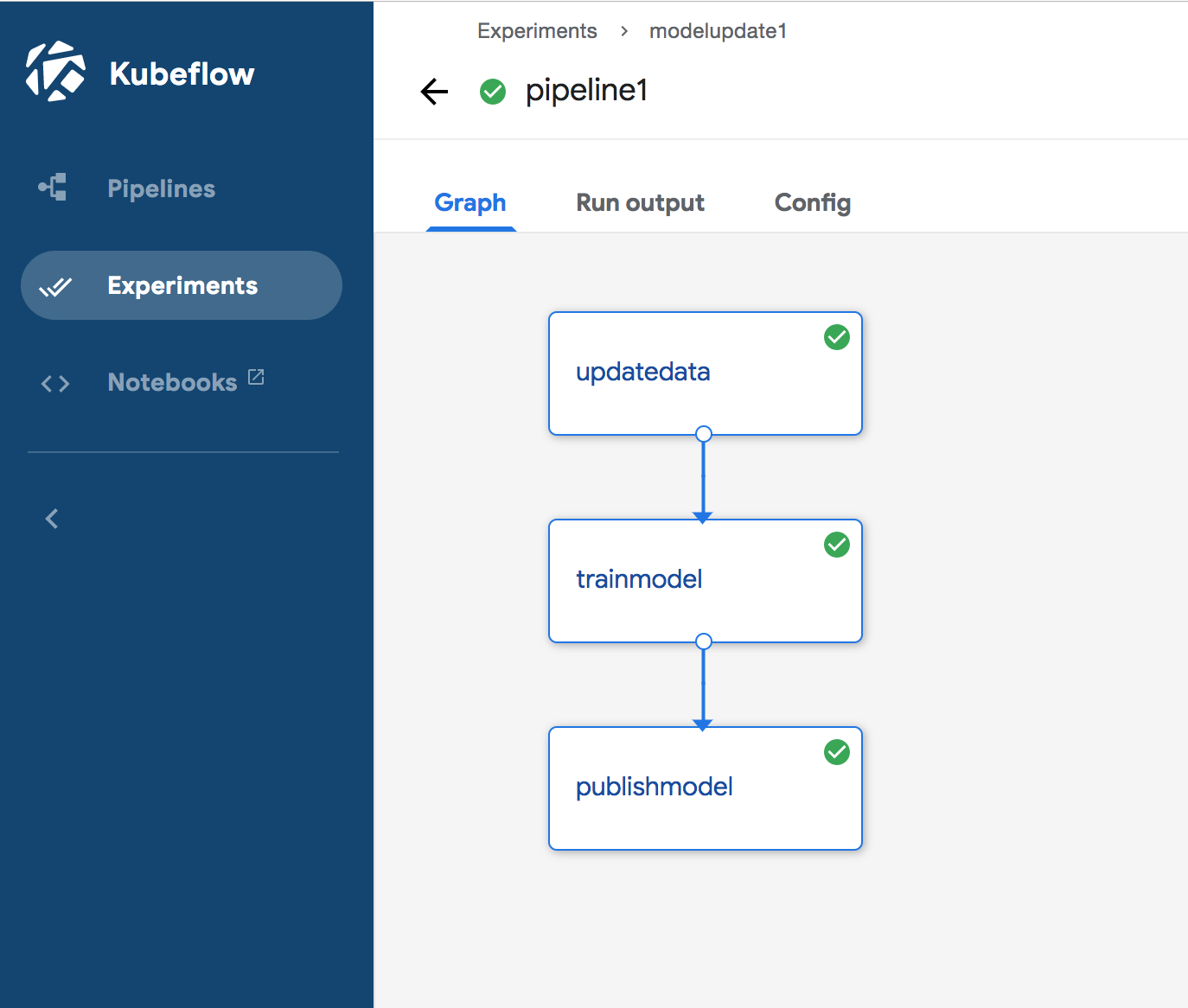
the following result:
. In addition we can also run pipeline from there, that produces
the following result:
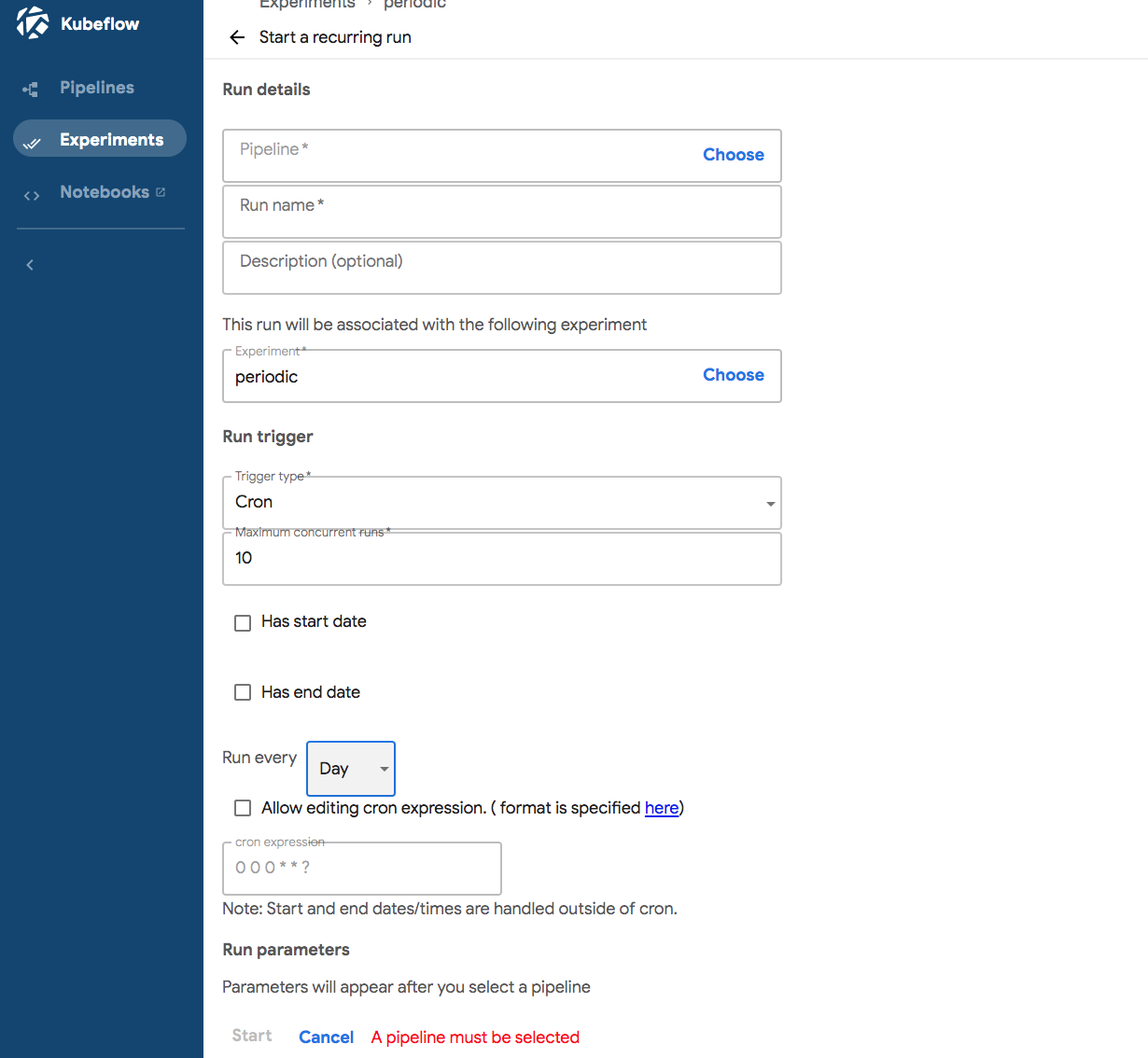
 Currectly pipelines do not allow to define periodic definition in the pipeline definition, but from UI, it is possible
to configure run as recurring and specify how often the run is executed
Currectly pipelines do not allow to define periodic definition in the pipeline definition, but from UI, it is possible
to configure run as recurring and specify how often the run is executed



Additional components included in this implementation include the following:
- Data Publister is a project used for preparing new data for machine learning. Whichever code is necessary to get the list of users and their current purchasing history goes here. For the simple implementation here I am not doing here anything - just give a code sample oh how to update data used for learning.
- Model server is a project implementing an actual model serving. It gets a stream of data and leverages TF Serving for the actual model serving. Additionally, it implements the second stream, that allows to change the URL of TF-serving based on the model update
- Model Publisher is a project responsible for updating model for Model server. It reads a current TF-server from a data file, makes sure that it is operational (by sending it HTTP request) and if it is, publishes a new model (new URL) to the model server. The acual code is here.
- Client is a project responsible for publishing recommendation requests to the model server. Code is here.
For storing data used in the project (models, data) we are using Minio, which is part of Kubeflow installation.
Finally we are using Kubeflow pipelines for organizing and scheduling overall execution.
The overall architecture of implementation is presented below:

Different pieces are build differently. Python code - recommender ML - is directly build into docker (see above) The rest of the code is is leveraging [SBT Docker plugin] and can be build using the following command:
sbt docker
that produces all images locally. These images have to be pushed into repository accessable from the cluster. I was using Docker Hub
Installation requires several steps:
- install kubeflow following the blog posts
- Install kafka as described here
- Populate minio with test data following this post
- Start Jupiter, following this blog post and test the notebook
- Try usage of TFJob for machine learning, following this blog post Ksonnet definitions for these can be found here
- Deploy model serving components recommender and recommender1 following this blog posts Ksonnet definitions for these can be found here
- Deploy Strimzi following this documentation. After the operator is installed, use this yaml file to create Kafka cluster
- Deploy model server and request provider using this chart
- Enable usage of Argo following blog post
- Enable usage of Kubeflow pipelines following blog post
- Test pipeline from the notebook
- Build pipeline definition using Python code and upload it to the pipeline UI
- Start recurring pipeline execution.
- install kubeflow following the following documentation. To run successfully on OpenShift (4.1) set the following service account to scc (this is a superset) anyuid:
system:serviceaccount:kubeflow:admission-webhook-service-account,
system:serviceaccount:kubeflow:default,
system:serviceaccount:kubeflow:katib-controller,
system:serviceaccount:kubeflow:katib-ui,
system:serviceaccount:kubeflow:ml-pipeline,
system:serviceaccount:istio-system:prometheus,
system:serviceaccount:kubeflow:argo-ui,
system:serviceaccount:istio-system:istio-citadel-service-account,
system:serviceaccount:istio-system:istio-galley-service-account,
system:serviceaccount:istio-system:istio-mixer-service-account,
system:serviceaccount:istio-system:istio-pilot-service-account,
system:serviceaccount:istio-system:istio-egressgateway-service-account,
system:serviceaccount:istio-system:istio-ingressgateway-service-account,
system:serviceaccount:istio-system:istio-sidecar-injector-service-account,
system:serviceaccount:istio-system:grafana,
system:serviceaccount:istio-system:default,
system:serviceaccount:kubeflow:jupyter,
system:serviceaccount:kubeflow:jupyter-notebook,
system:serviceaccount:kubeflow:jupyter-hub,
system:serviceaccount:boris:default-editor,
system:serviceaccount:kubeflow:tf-job-operator,
system:serviceaccount:istio-system:kiali-service-account,
system:serviceaccount:boris:strimzi-cluster-operator
set the following service account to scc (this is a superset) privileged:
system:serviceaccount:openshift-infra:build-controller,
system:serviceaccount:kubeflow:admission-webhook-service-account,
system:serviceaccount:kubeflow:default,
system:serviceaccount:kubeflow:katib-controller,
system:serviceaccount:kubeflow:katib-ui,
system:serviceaccount:kubeflow:ml-pipeline,
system:serviceaccount:istio-system:jaeger,
system:serviceaccount:bookinfo:default,
system:serviceaccount:kubeflow:jupyter-web-app-service-account,
system:serviceaccount:kubeflow:argo,
system:serviceaccount:kubeflow:pipeline-runner
- To make Kiali running, update Kiali cluster role as follows
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kiali
selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/kiali
uid: cd0de883-b9ff-11e9-bd33-023708277e46
resourceVersion: '11149746'
creationTimestamp: '2019-08-08T17:13:11Z'
labels:
app: kiali
chart: kiali
heritage: Tiller
release: istio
rules:
- verbs:
- get
- list
- watch
apiGroups:
- ''
resources:
- configmaps
- endpoints
- namespaces
- nodes
- pods
- services
- replicationcontrollers
- verbs:
- get
- list
- watch
apiGroups:
- extensions
- apps
- apps.openshift.io
resources:
- deployments
- deploymentconfigs
- statefulsets
- replicasets
- verbs:
- get
- list
- watch
apiGroups:
- project.openshift.io
resources:
- projects
- verbs:
- get
- list
- watch
apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
- verbs:
- get
- list
- watch
apiGroups:
- batch
resources:
- cronjobs
- jobs
- verbs:
- create
- delete
- get
- list
- patch
- watch
apiGroups:
- config.istio.io
resources:
- apikeys
- authorizations
- checknothings
- circonuses
- deniers
- fluentds
- handlers
- kubernetesenvs
- kuberneteses
- listcheckers
- listentries
- logentries
- memquotas
- metrics
- opas
- prometheuses
- quotas
- quotaspecbindings
- quotaspecs
- rbacs
- reportnothings
- rules
- solarwindses
- stackdrivers
- statsds
- stdios
- verbs:
- create
- delete
- get
- list
- patch
- watch
apiGroups:
- networking.istio.io
resources:
- destinationrules
- gateways
- serviceentries
- virtualservices
- verbs:
- create
- delete
- get
- list
- patch
- watch
apiGroups:
- authentication.istio.io
resources:
- policies
- meshpolicies
- verbs:
- create
- delete
- get
- list
- patch
- watch
apiGroups:
- rbac.istio.io
resources:
- clusterrbacconfigs
- rbacconfigs
- serviceroles
- servicerolebindings
- verbs:
- get
apiGroups:
- monitoring.kiali.io
resources:
- monitoringdashboards
- Populate minio with test data following using the following commands:
mc mb minio/data
mc mb minio/models
mc cp /Users/boris/Projects/Recommender/data/users.csv minio/data/recommender/users.csv
mc cp /Users/boris/Projects/Recommender/data/transactions.csv minio/data/recommender/transactions.csv
mc cp /Users/boris/Projects/Recommender/data/directory.txt minio/data/recommender/directory.txt
-
Starting Jupiter server. Had to do several things:
-
Creating TFJob. Several things:
- Without ksonet, it is necessary to create a yaml file for TFJob. Note, that container name has to be tensorflow
- tf-job-operator has to be added to anyuid
- Add tfjobs/finalizers to tf-job-operator role
- TFJob UI is not integrated yet. Go to /tfjobs/ui/
-
According to Kubeflow documentation, Tensorflow serving has not yet been converted to kustomize. So we are using a custom deployment (modeled after deployment in Kubeflow 0.4).
-
Argo. Several things:
- update argo and argo-ui role to add workflows/finalizers
- update workflow-controller-configmap to add - containerRuntimeExecutor: k8sapi
Copyright (C) 2019 Lightbend Inc. (https://www.lightbend.com).
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this project except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.