Weakly supervised learning gives us an interesting insight into how deep neural network works. I recently found an interestingcd paper by Zhang et al using multiple sequetial classifiers to produce more holistic class activation map. I implemented their approach in PyTorch and added a bit of my own ideas.
Adversarial Complementary Learning for Weakly Supervised Object Localization Xiaolin Zhang, Yunchao Wei, Jiashi Feng, Yi Yang, Thomas Huang https://arxiv.org/abs/1804.06962
The model suggested by the paper consists of backbone as a feature extractor and two classifiers in a sequential order.

The two classifiers are made up of a 1x1 convolution layer that shrinks the feature channel (i.e. 2048) into the output channel of label size C (i.e. 4 or 5) and a global average pooling layer. Then the classifier produces a class activation map using the cth weight of the 1x1 conv layer.
Class activation map reveals the most discriminative region related to the target label in a given image. ACoL zeros out the areas of the feature maps where its values are higher than delta. Then the masked feature maps are fed into the second classifier that, in turn, searches for the next most discriminative regions for the label.
All in all, the second classifier complements the first classifier's decision to generate a more holistic class activation map.

delta is a cruicial hyper-parameter in training ACoL. High delta would leave most of the feature regions alive, so that the second classifier is likely to look at the regions that are already found by its predecessor. Setting delta low has a risk of forcing the second classifier to learn the mapping between irrelevant regions to the target label when all the relevant features are wiped out. For this reason, the authors carried out an abalation study to find the optimal value for their datasets. Their choice of delta is 0.6.
For my own image dataset of 4 footballers (700~900 images per class), thresholding with 0.6 was too low that it misled the second classifier and ended up with poor CAM outputs. 0.9 showed better results yet it fails to deliver the outstanding performance shown in the paper.
So I came up with an idea to turn the second classifier into an adversarial classifier. Let's say that the target label is Messi [1, 0, 0, 0]. The second classifier's loss is defined as a modified version of cross entropy loss of its output and the other labels [0, 1, 1, 1].
def restCrossEtropyLoss(X, y, device):
_base = torch.ones(X.size()).to(device)
_one_hot = _base.scatter(1, y.view(-1, 1), 0)
C = _one_hot[0].sum()
denom = torch.exp(X).sum(1)
numer = torch.exp((X * _one_hot).sum(1) / C)
loss = -torch.log(numer / denom).mean()
return lossThe lower the classifier output for the target label is, the lower the loss of the second classifier becomes. As ACoL updates its parameters with the first and second classifier loss, I speculated that the second adversarial classifier would guide the backbone and the first classifier to find the discriminative region as wide as possible to lower the second loss.
In my own PyTorch implementation in this repo, 'p' refers to the normal classifier and 'n' to the adversarial one. The model in the original paper is 'pp' according to my model definition.
I ran my own experiments with various hyper parameters like pretrained models (resent50, 101, 152), weight decay, delta, etc, and here's what I found.
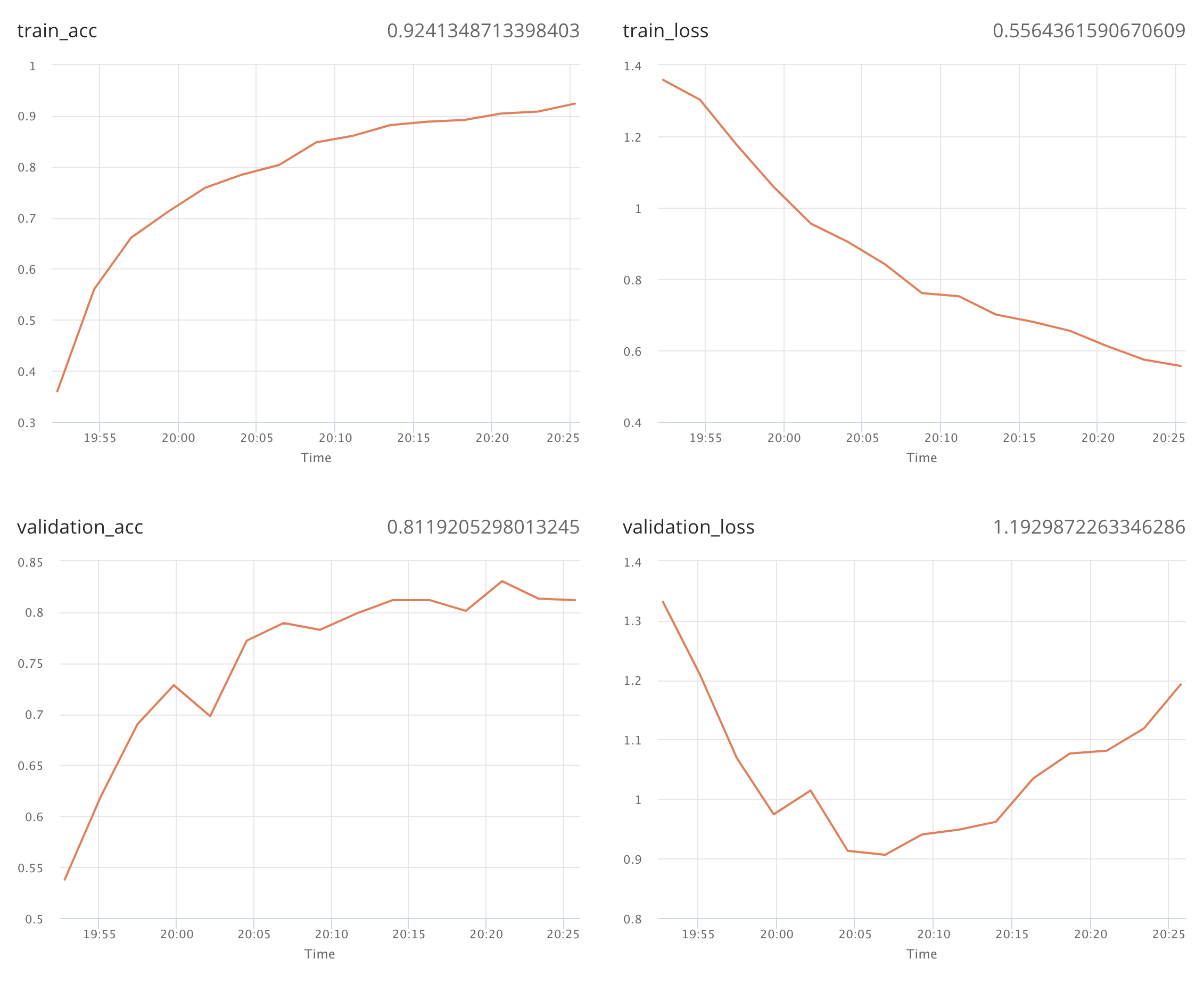
- p and pn converged well when pp's val loss exploded in the later epochs. The validation losses of p and pn were nearly the same as their training losses.
- pp with delta 0.6 generated poor heat maps that cover most of the image.
- p (basic resnet + 1x1 conv + GAP) produced good CAM but the first classifier result was not as accurate as pn 0.9.
- In terms of classification accuracy, the best p, pn, pp models were more or less the same level (77~79%)
- From my own point of view, pn with delta 0.9 produces the best CAM output. The below is some of the cherry picked results from the validation images.


To train your own ACoL, clone this repo, ready your own dataset and run the following command.
python train_acol.py --input-path '../input/' --batch-size 64 --epochs 10 --model resnet101 --cls-recipe pp --delta-list 0.9--image-path: training / validation dataset path--batch-size: batch size for training and validation--epochs: number of epochs to run--model: torchvision pretrained model name--cls-recipe: recipe sequence for classifiers (ex. pp or pn or p)- p: complementary classifier that looks for other clues for the given label
- n: adversarial classifier that links the rest of the feature maps to the other labels