This project aims to order a potential client list by propensity score.

Insurance All is a company that provides vehicle insurance to its customers and the product team is analyzing the possibility of offering policyholders a new product: health insurance.
As with vehicle insurance, customers of this new health insurance plan need to pay an amount annually to Insurance All to obtain an amount insured by the company, intended for the costs of an eventual accident or damage to the vehicle.
Insurance All conducted a survey of about 380,000 customers about their interest in joining a new health insurance product last year. All customers expressed interest or not in purchasing health insurance and these responses were saved in a database along with other customer attributes.
The product team selected 127 thousand new customers who did not respond to the survey to participate in a campaign, in which they will receive the offer of the new health insurance product. The offer will be made by the sales team through telephone calls.
However, the sales team has the capacity to make 20 thousand calls within the campaign period.
Cross sell is a technique to offer of a product complementary to what the customer has decided to buy to increase the store's revenue. Therefore, it's important to notice 2 points: the customer and the product.
Harvard Business Review conducted a research with several companies in Europe and the United States, finding that all those that implemented cross sell strategies increased the ROI (Return on Investiment) obtained from each client.
The Cross Sell may also increase Average Ticket Price. This metric is important to find out how much each customer spends on their products and services.
My solution to solve this problem will be the development of a data science project. This project will have a machine learning model which can predict customers that may be interested in health insurance. It'll help the team to selct the best customers that may be interested in health insurance.
Step 01. Data Description: In this first section the data will be collected and studied. The missing values will be threated or removed. Finally, a initial data description will carried out to know the data. Therefore some calculations of descriptive statistics will be made, such as kurtosis, skewness, media, fashion, median and standard desviation.
Step 02. Feature Engineering: In this section, a mind map will be created to assist the creation of the hypothesis and the creation of new features. These assumptions will help in exploratory data analysis and may improve the model scores.
Step 03. Data Filtering: Data filtering is used to remove columns or rows that are not part of the business. For example, columns with customer ID, hash code or rows with age that does not consist of human age.
Step 04. Exploratory Data Analysis: The exploratory data analysis section consists of univariate analysis, bivariate analysis and multivariate analysis to assist in understanding of the database. The hypothesis created in step 02 will be tested in the bivariate analysis.
Step 05. Data Preparation: In this fifth section, the data will be prepared for machine learning modeling. Therefore, they will be transformed to improve the learning of the machine learning model, thus they can be encoded, oversampled, subsampled or rescaled.
Step 06. Feature Selection: After the data preparation in this section algorithms, like Boruta, will select the best columns to be used for the training of the machine learning model. This reduces the dimensionality of the database and decreases the chances of overfiting.
Step 07. Machine Learning Modeling: Step 07 aims to train the machine learning algorithms and how they can predict the data. For validation the model is trained, validated and applied to cross validation to know the learning capacity of the model.
Step 08. Hyparameter Fine Tuning: Firstly selected the best model to be applied in the project, it's important to make a fine tuning of the parameters to improve its scores. The same model performance methods apllied in the step 07 are used.
Step 09. Conclusions: This is a conclusion stage which the generation capacity model is tested using unseen data. In addition, some business questions are answered to show the applicability of the model in the business context.
Step 10. Model Deploy: This is the final step of the data science project. So, in this step the flask api is created and the model and the functions are saved to be implemented in the api.
-
False: People between 40 and 50 are more interested in having health insurance.
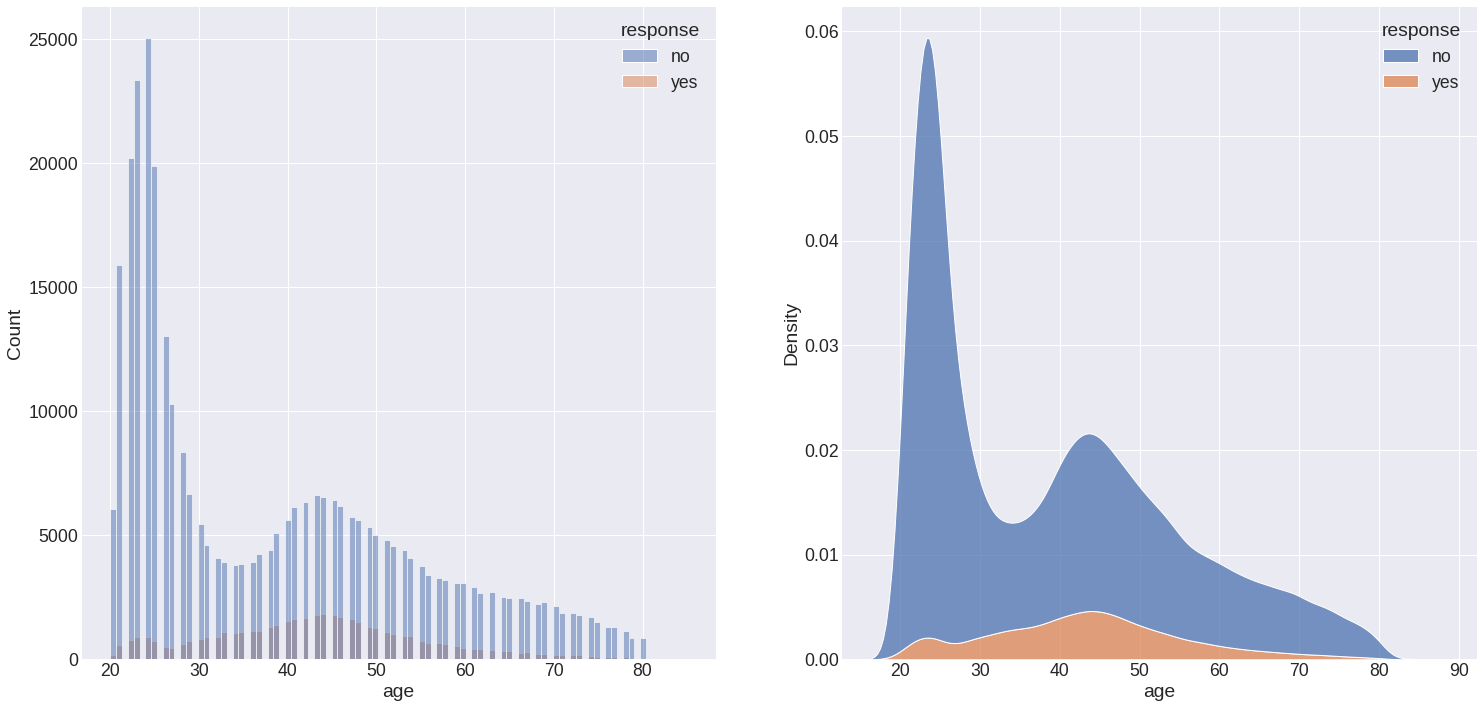
-
False: Customers without car insurance are more likely to get health insurance. In this database 99.7% of customers are previously insured.
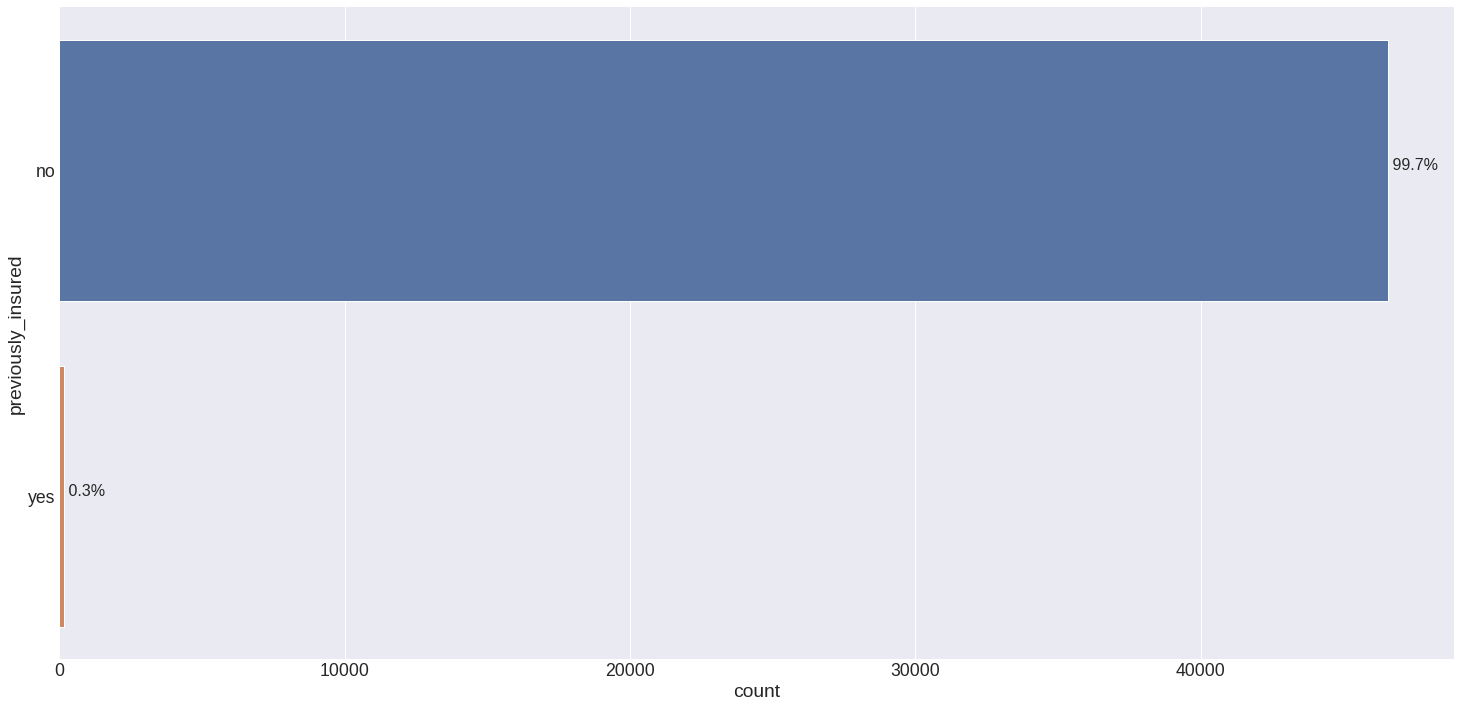
-
False: Customers who don't want the health insurance and got damaged are about 43.9%.
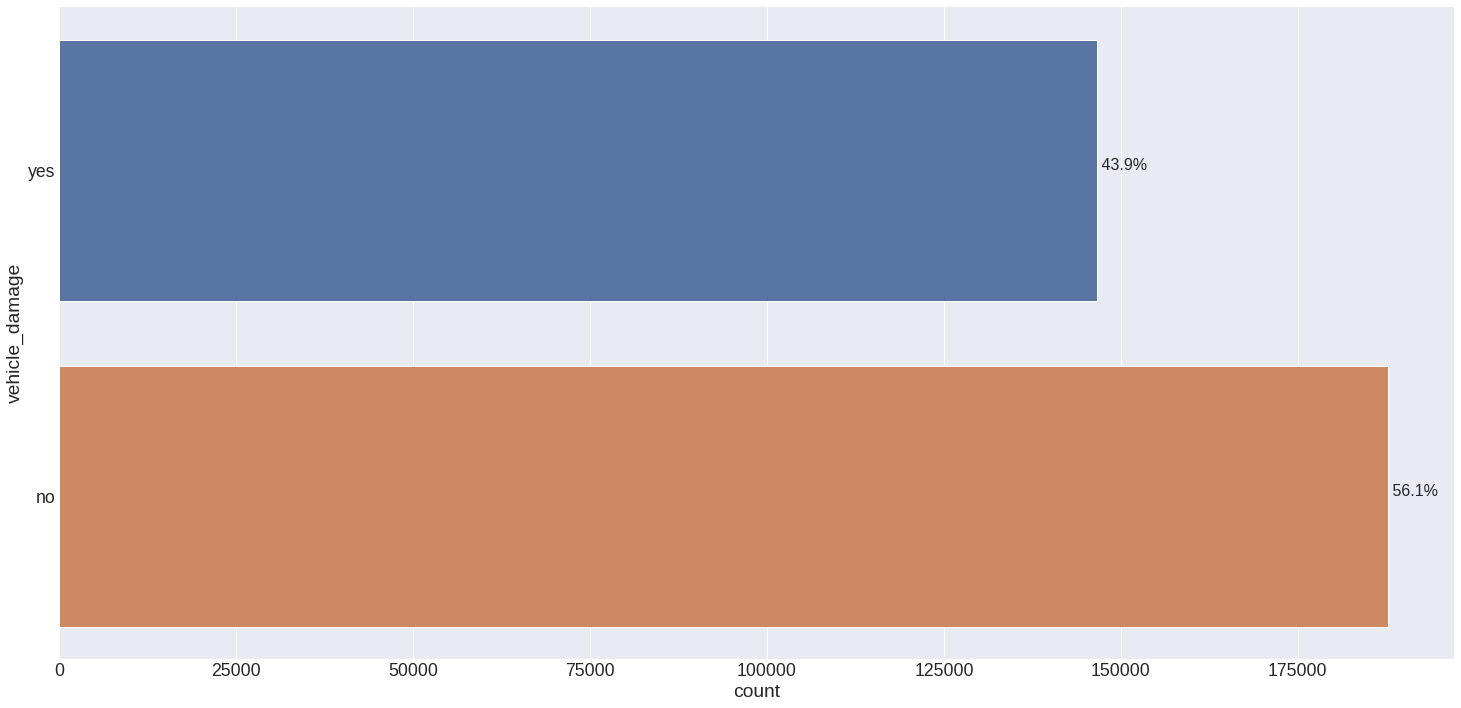



Here's all cross validation results of the machine learning models with their default parameters. These metrics corresponds to a k = 50%, up to 50% of data. The cross validation method is important to show the capacity of the model to learn.
| Top K Precision | Top K Recall | Top K F1-Score |
|---|---|---|
| 0.1231 +/- 0.0015 | 0.5021 +/- 0.0059 | 0.1977 +/- 0.0023 |
| Top K Precision | Top K Recall | Top K F1-Score |
|---|---|---|
| 0.242 +/- 0.0002 | 0.9874 +/- 0.0009 | 0.3888 +/- 0.0003 |
| Top K Precision | Top K Recall | Top K F1-Score |
|---|---|---|
| 0.2406 +/- 0.0003 | 0.9816 +/- 0.0014 | 0.3865 +/- 0.0005 |
| Top K Precision | Top K Recall | Top K F1-Score |
|---|---|---|
| 0.2406 +/- 0.0004 | 0.9815 +/- 0.0017 | 0.3864 +/- 0.0006 |
| Top K Precision | Top K Recall | Top K F1-Score |
|---|---|---|
| 0.2415 +/- 0.0006 | 0.9851 +/- 0.0024 | 0.3879 +/- 0.001 |
| Top K Precision | Top K Recall | Top K F1-Score |
|---|---|---|
| 0.2417 +/- 0.0002 | 0.9861 +/- 0.0009 | 0.3883 +/- 0.0003 |
The chosen model was Logistic Regression and it was tuned to improve their parameters and scores. Below there's a table with the capacity of the model to learn.
| Top K Precision | Top K Recall | Top K F1-Score |
|---|---|---|
| 0.241 +/- 0.0004 | 0.9831 +/- 0.0016 | 0.3871 +/- 0.0006 |
It's possible to determinize the capacity of the model to generalize using unseen data. In other words, capcity of the model to classify new data as shown.
| Top K Precision | Top K Recall | Top K F1-Score |
|---|---|---|
| 0.2793 | 0.9115 | 0.4275 |
These graphs below show the accumulative gain and lift curve.


-
What percentage of customers are interested in purchasing auto insurance? Will the sales team be able to reach them by making 20,000 calls?
-
The database is based on 46,876 (12.3%) of customers interessed in health insurance and 334,232 (87.7%) of no interested.
-
The model results have shown that the model has the precision of 24.10% (24.14% for a excellent performance or 24.06% for a poor performance). So, using the model it's possible to contact 4,820 (4,828 for a excellent performance or 4,812 for a poor performance) customers interested in health insurance of 20,000 calls. However the recall is about 98.31% (+/- 0.0016).
-
-
If the sales team's capacity increases to 40,000 calls, what percentage of customers interested in purchasing auto insurance will the sales team be able to contact?
Increasing to 40,000 calls the model may help the sales team to contact 9,640 (9,656 for a excellent performance or 9,624 for a poor performance) the customers interested in health insurance.
-
How many calls does the sales team need to make to contact 80% of customers interested in purchasing auto insurance?
The model sorted 98.31% (46,084 customers) of the customer interested in 50% of the database with 381,109 customers. Using the model, it's possible to contact 80% of customers interested in health insurance in 155,064 (155,064 for a excellent performance or 155,064 for a poor performance) calls.
The random model classified correctly just 12.31% (+/- 0.15%) of the interested customer. The final model has the ability to differentiate the classes and managed to correctly classify 24.1% (+/- 0.04%). The lift curve also shows that the model manages to have a gain 3 times greater than the random choice of customers.
The model was able to organize that almost all interested customers (98.31% +/- 0.16%) stay on up to 50% of the sorted list. This makes it possible to save half of the expenses incurred for calls. So if each call costs R$ 15.00 in 20,000.00 there is an expense of R$ 300,000.00. Using the model it is possible to spend only R$ 150,000.00.
-
It's important to interpret correctly the results and how they can help the business problems.
-
Even if the model's score is small it can make a difference to the company's business problem.
-
I have to learn to about top K scores.
-
Improvement of the model's metrics, espeacilly the precision.
-
Test other hypothesis to get new insights from the database.