






Key Features • Installation • Credits • Related • License
The watsonNLU R wrapper package integrates with the IBM Watson Natural Language Understanding service to produce a variety of outputs including:
- sentiment
- emotions
- categories
- relevance
Natural language processing analyses semantic features of the text while the Watson API cleans the HTML content so that the information can be handled by the R wrapper to produce a neat data frame output for each of the functions.
This section provides an overview of each of the functions. Please refer to Installation for more usage details.
More information and examples can be found here:
The authentication function will take the credentials generated here (you must be signed into your account).
# Authenticate using Watson NLU API Credentials
auth_NLU(username, password)
As credential expire, you will have to create new ones following the steps delineated in the Installation Manual. Before you create new credentials, try re-running auth_NLU.
Using the keyword_sentiment function is a useful tool for measuring the tone of a body of text. It could be used to assess the subjectivity of certain articles for instance by setting a threshold for neutral/objective text and comparing the polarization of articles on a similar topic.
# Find the keywords and related sentiment score in the given text input.
sentiments <- keyword_sentiment(input = IBMtext, input_type='text')
head(sentiments)
A standard example of a use case for keyword_emotions would be for expanding on the positive versus negative sentiments.
# Find the keywords and related emotions in the given text input.
emotions <- keyword_emotions(input = IBMtext, input_type='text')
head(emotions)
Relevance of specific keywords can be useful for determining what are the most recurring and pertinent terms of a document. To facilitate use, the limit argument can be set to return up to a specific number of keywords.
# Top 5 keywords from the text input.
keyword_relevance(input = IBMtext, input_type='text', limit = 5)
# Top 5 keywords from the URL input.
keyword_relevance(input = 'http://www.nytimes.com/guides/well/how-to-be-happy', input_type='url', limit = 5)
The results here display keywords that are locations and adventure related terms.
User's may be interested in gathering the general topics of a text or the contents of a site very quickly.
# Find 5 categories that describe the text input.
text_categories(input = IBMtext, input_type='text')
The results will return a variable number of themes that can be drilled down into category levels. The hierarchy will go from general topics to more specific subject matter as the level number increases.
To use the Watson NLU API you must create an account with the IBM developper cloud.
-
Follow the link to the Natural Language Understand page and follow the Sign in to IBM Cloud link or click "Get Started Free". Check your inbox to complete registration.

-
Use your credentials to log in and add the Natural Language Understanding services and click "Create".
-
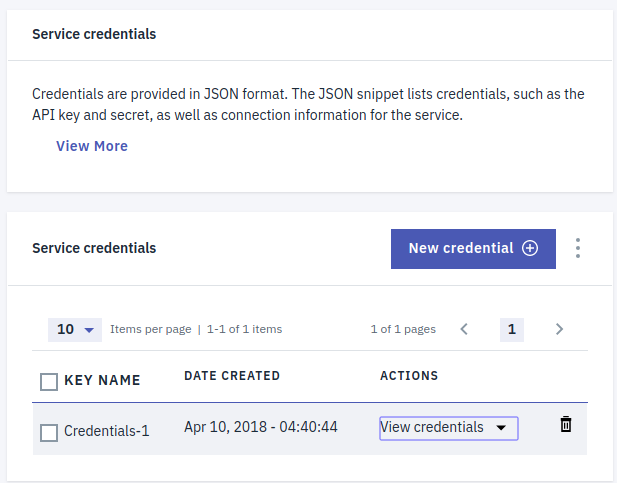
Go to Service credentials and create "New credentials".

-
Use these credentials as the username and password within the R wrapper authentication function {INSERT FUNCTION NAME HERE}



You can install watsonNLU in R from GitHub with:
# install.packages("devtools")
devtools::install_github("johannesharmse/watsonNLU")The output provides a wealth of information that needs to be wrangled to display the highlights. We make use of the dplyr package to gather the emotions per keyword and display their score. This facilitates the plotting process with ggplot2. First off, let's summarize the emotions of the whole document weighing each keyword's emotions by its relevance:
library(dplyr)
library(ggplot2)
library(tidyr)
# wrangle the keywords to display a mean score proportional to the relevance
weighed_relevance <- emotions %>%
gather(key = emotion, value = score, sadness, joy, fear, disgust, anger) %>%
group_by(emotion) %>%
summarize(mean.score= mean(score*key_relevance)) %>%
mutate(mean.score = mean.score/sum(mean.score))
# display the results
ggplot(weighed_relevance, aes(x = emotion, y=mean.score, fill=emotion)) +
geom_bar(stat = 'identity', position = "dodge") +
labs(x = 'Emotions', y ='Emotion Score', title = 'Emotions of IBMtext', subtitle = "Word relevance weighed average") +
scale_fill_discrete('Emotion') +
guides(fill=FALSE)
theme(axis.text.x = element_text(angle = 25, hjust = 0.7, vjust = 0.8))

# gather and summarize the data grouped by most relevant keywords
emotions_long <- emotions %>%
arrange(desc(key_relevance)) %>%
head(5) %>%
gather( key = emotion, value = score, sadness, joy, fear, disgust, anger) %>%
group_by(keyword, emotion) %>% arrange(desc(score)) %>%
summarize(mean.score=mean(score))
# display the 5 most relevant keywords and their emotion scores
ggplot(emotions_long, aes(x = keyword, y=mean.score, fill=emotion)) +
geom_bar(stat = 'identity', position = "dodge") +
labs(x = '5 Most Relevant Keywords', y ='Emotion Score', title = 'Emotions of IBMtext Keywords', subtitle = "Filtered for the 5 most relevant keyword") +
scale_fill_discrete('Emotion') +
theme(axis.text.x = element_text(angle = 25, hjust = 0.7, vjust = 0.8))

- Adapted from an API wrapper project by Johannes Harmse
- README structure borrowed from other R package project (ptoolkit)
- formatting inspiration from Markdownify
- Contributing conventions inspired from @simrnsethi's other R package (regscoreR)
- Badges by Shields IO
- Logo by IBM Watson
We found this package WatsonR to be another relevant API wrapper around IBM Watson API.
Interested in contributing?
See our Contributing Guidelines and Code of Conduct.