This repo contains code for the following paper.
Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification,
Yichao Zhou, Jyun-Yu Jiang, Kai-Wei Chang and Wei Wang. EMNLP 2019.
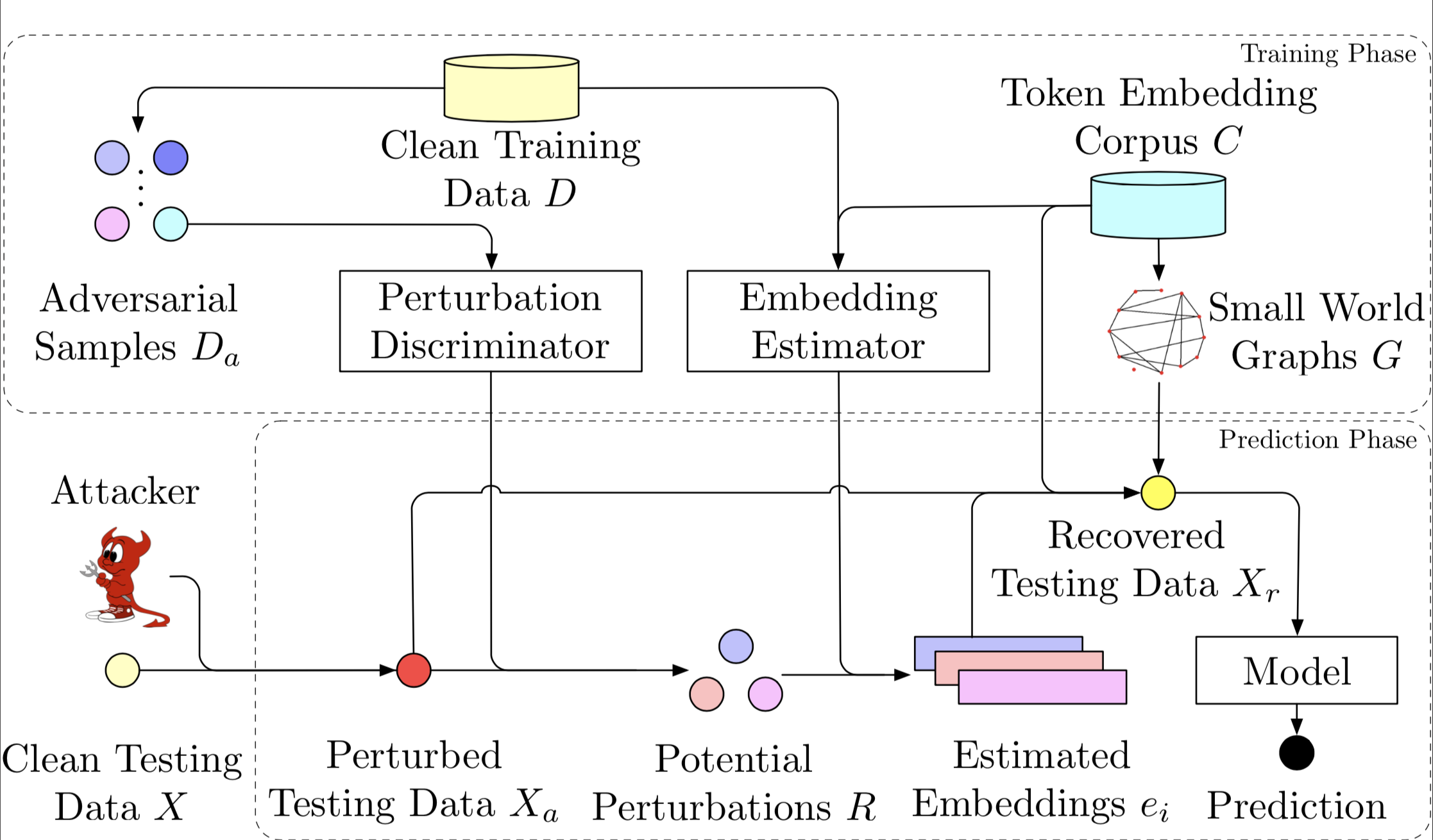
In this paper, we propose a novel framework, learning to discriminate perturbations (DISP), to identify and adjust malicious perturbations, thereby blocking adversarial attacks for text classification models.
Python 3.6
Pytorch 1.0.1+
CUDA 10.0+
numpy
hnswlib
tqdm
We first attack the training data on word level or character level. Then we pre-train a discriminator with the adversarial data.
python bert_discriminator.py
--task_name sst-2
--do_train
--do_lower_case
--data_dir data/SST-2/
--bert_model bert-base-uncased
--max_seq_length 128
--train_batch_size 8
--learning_rate 2e-5
--num_train_epochs 25
--output_dir ./tmp/disc/We build a pre-training dataset for embedding estimator by collecting the context of window size for each word in the dataset. It can also be considered as fine-tuning a bert language model using a smaller corpus. The embedding estimator is different from a language model because it only estimate the embedding for a masked token instead of using a huge softmax to pinpoint the word.
python bert_generator.py
--task_name sst-2
--do_train
--do_lower_case
--data_dir data/SST-2/
--bert_model bert-base-uncased
--max_seq_length 64
--train_batch_size 8
--learning_rate 2e-5
--num_train_epochs 25
--output_dir ./tmp/gnrt/We first attack the test data using 5 differernt methods to drop the model performance as much as possible. The codes related to attacking the test sets would be availble soon!
During inference phase, we use the pre-trained discriminator to identify the words that have been attacked.
python bert_discriminator.py
--task_name sst-2
--do_eval
--eval_batch_size 32
--do_lower_case
--data_dir data/SST-2/add_1/ # add_1 is the dataset where we use "add character" method to attack the instance and only one word was attacked.
--data_file data/SST-2/add_1/test.tsv
--bert_model bert-base-uncased
--max_seq_length 128
--train_batch_size 16
--learning_rate 2e-5
--num_eval_epochs 5
--output_dir models/
--single Then, we recover the words with a pre-trained embedding estimator. Note that we use small-world-graph to conduct a KNN-based search for closest word in the embedding space.
python bert_generator.py
--task_name sst-2
--do_eval
--do_lower_case
--data_dir data/SST-2/add_1/
--bert_model bert-base-uncased
--max_seq_length 64
--train_batch_size 8
--learning_rate 2e-5
--output_dir ./tmp/sst2-gnrt/
--num_eval_epochs 2After recovering the test instances, we can run a model to check the recovering effectiveness. The model in our settings is a sentiment classification model based on bert contextualized embeddings.