This repository contains submission for the 2020 Facebook developers circle community challenge. We will be discussing about privacy preserving machine learning tools built on top of pytorch alongside tutorials for technical implementations.
The exponential growth of data is overwhelming and data nowadays is basically ubiquitous. Considering the ground-breaking achievements and breakthrough in Artificial intelligence such as deep learning due to the rise and access to compute instances in order to run large training jobs of deep neural networks on the cloud, now is the time to take a look into how AI systems are being developed and how privacy-preserving these systems are. Deep learning is a form of machine learning which is an exciting domain with a very huge potential, it is fast-growing with wide-array of cutting edge applications in self-driving cars, cancer detection, NLP and speech recognition. The heart of an optimized model is 'data', your model is as good as the data it's being trained on and as ML is hungry for data, we currently do not have a data lake/bank that contains accurate set of data that can utilized for training effective ML models, as such data are often collected from users of a product which often contain sensitive information of these users thereby invading privacy. What if we could train models and perform statistical analysis on distributed data without compromising privacy?
Data privacy has been a major concern for tech companies and individuals since the GDPR legislation in may 2018. Therefore, it's imperative for data scientists, machine learning engineers researchers and tech companies to be aware of user's privacy while going about collecting data in the ML pipeline either for analysis, training or some other business oriented reasons.
This lesson we will tackle lowering some of the potential implications and challenges posed by training Deep neural network on distributed data and AI as well as principles for building responsible AI that is secure to avoid harming others amd protecting privacy of data.
Knowledge of the following are required in order to follow along with the tutorial
- Python
- Pytorch
You need to have the following software installed on your machine
- Anaconda/conda
- Pytorch 1.4 or later
- Syft 0.2.9
Steps
- Install anaconda
- Add conda to your system PATH
- Check the INSTALLATION.md here on a comprehensive guide on how to install and run the tutorials.
$ git clone https://github.com/Boluwatifeh/Secure-AI.git
$ cd tutorials
$ jupyter notebookRun the code cells in the note book
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change. if you're familiar with the PySyft framework and would love to contribute by writing beginner-friendly tutorials you can always send a PR. i'd also highly recommend contributions to the open source Openmined community which is a group of developers working on making the world more privacy preserving, check out the openmined repo here https://github.com/OpenMined. Check out the CONTRIBUTING.md over here

What is federated learning and why is it important ? Federated learning is a machine learning technique used in training models on distributed data in a decentralized manner, this tutorial would cover how to leverage pytorch and pysyft for federated learning. At the end, readers would train a federated neural network on the official MNIST dataset.
Federated learning is a machine learning technique that enables training of machine learning models on decentralized data by sending copies of a model to edge devices where data lives in order to perform training and preserve privacy of users data. Brendan Mcmahan of Google pioneered Federated learning and it eliminates moving of data to a central server for training purposes. The idea Federated learning proposes is to leave data at edge devices also known as workers, these workers might be mobile devices, IOT devices etc
- Edge devices receives a copy of a global model from a central server.
- The model is being trained locally on the data residing on the edge devices
- The global model weights are updated during training on each worker
- A local copy is sent back to the central server
- The server receives various updated model and aggregate the updates thereby improving the global model and also preserving privacy of data in which it was being trained on.
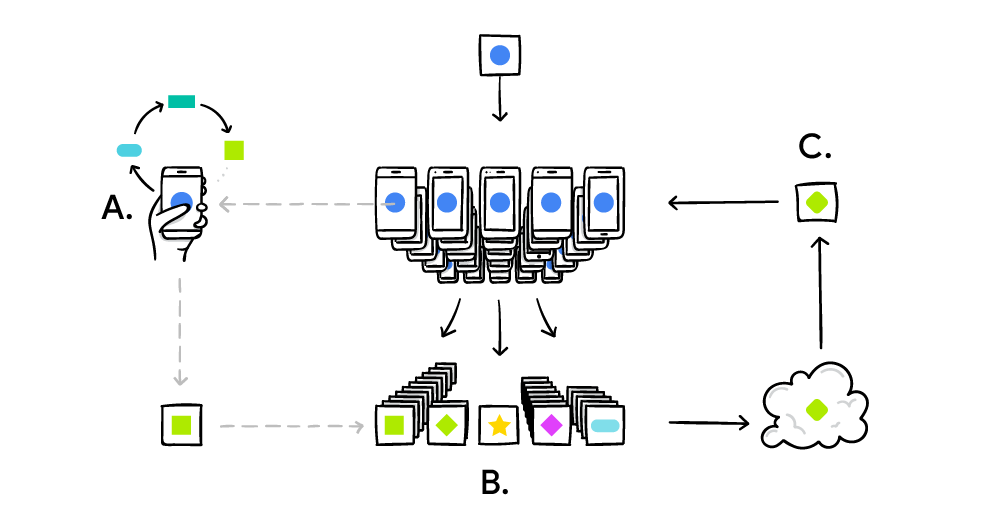
Federated learning workflow
-
Next word prediction: Federated learning is used to improve word prediction in mobile devices without uploading users data to the cloud for training. Google Gboard implements FL by using on-device data to train and improve the Gboard next word prediction model for it's users, watch this video to better understand how google uses federated learning at scale. You can also read this online comic from Google AI to get a better grasp of federated learning.
-
Voice recognition: FL is also used in voice recognition technologies, an example is in apple Siri and recently Google introduced the audio recognition technology on Google assistant to train and better improve users experience with the Google assistant. Watch a demonstration of FL on audio recording for speech systems here. In every of these use cases, the data doesn't leave the edge devices thereby keeping the data private, safe and secure while still improving these technologies and making products smarter over time.
To run the tutorial and follow along, you need to be familiar with python, basics of pytorch, jupyter notebooks and basics of pysyft for remote execution (this can be found in the part 1 notebook of the tutorials directory on github). Head over to this github repository and make sure your machine meets the following requirements
- Anaconda/conda 4.8+
- Python 3.6
- Pytorch 1.4 or later
- Syft 0.2.9
Option-1: Run notebook online
You can run the notebook for this tutorial(Part-2-federated-learning-with-pysyft-and-pytorch) on jovian without installing any dependencies by visiting this link and click on the run button > run on binder
option-2: Run locally
- Create and activate an environment with python version 3.6
$ Conda create -n my_env python=3.6
$ Conda activate my_env - After activating the environment, the next thing is to install jupyter notebook and syft which basically install every other packages required for the tutorial.
$ conda install jupyter notebook
$ Pip install syft- Clone this repository
$ git clone https://github.com/boluwatifeh/Secure-AI.git - Cd into the tutorials folder and run the notebook
$ Cd tutorials
$ Jupyter notebookOver this tutorial, we're going to look into one of the features of pysyft by training a neutral network on MNIST for federated learning.
Pysyft is an open source python library for computing on data you do not own or have access to. It is built on top of the popular deep learning framework (pytorch and tensorflow) and allows for computations on decentralized data, it also provides room for privacy preserving tools such as secure multiple party computation and differential privacy. Jump over to the github repository to learn more.
Pip install syft
Lets import torch, torchvision, and other modules
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transformsimport syft as sy # import the syft library
hook = sy.TorchHook(torch) # attach the pytorch hook
joe = sy.VirtualWorker(hook, id="joe") # remote worker joe
jane = sy.VirtualWorker(hook, id="jane") # remote worker janeLet's load in the data and transform it into a federated dataset by implementing the federate() method.
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, )),
])
train_set = datasets.MNIST(
"~/.pytorch/MNIST_data/", train=True, download=True, transform=transform)
test_set = datasets.MNIST(
"~/.pytorch/MNIST_data/", train=False, download=True, transform=transform)
federated_train_loader = sy.FederatedDataLoader(
train_set.federate((joe, jane)), batch_size=64, shuffle=True) # the federate() method splits the data within the workers
test_loader = torch.utils.data.DataLoader(
test_set, batch_size=64, shuffle=True)The network architecture would remain the same just as the example tutorial from pytorch with an input of 784-dim tensor of pixel values for each image, and producing a tensor of length 10 which indicates the class scores for an input image,
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = x.view(-1, 784)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model = Net()
print(model)
optimizer = optim.SGD(model.parameters(), lr=0.01)Looking at the training process of this distributed approach, the data seem to be on a remote machine so therefore we would use the location attribute to get the location and send our model to that location where the data is present, we would then get back the improved model using the get() method and calculate the loss.
n_epoch = 10
for epoch in range(n_epoch):
model.train()
for batch_idx, (data, target) in enumerate(federated_train_loader):
model.send(data.location) # send the model to the client device where the data is present
optimizer.zero_grad() # training the model
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
model.get() # get back the improved model
if batch_idx % 100 == 0:
loss = loss.get() # get back the loss
print('Training Epoch: {:2d} [{:5d}/{:5d} ({:3.0f}%)]\tLoss: {:.6f}'.format(
epoch+1, batch_idx * 64,
len(federated_train_loader) * 64,
100. * batch_idx / len(federated_train_loader), loss.item()))Training Epoch: 1 [ 0/60032 ( 0%)] Loss: 2.347703
Training Epoch: 1 [ 6400/60032 ( 11%)] Loss: 1.378724
Training Epoch: 1 [12800/60032 ( 21%)] Loss: 0.804508
Training Epoch: 1 [19200/60032 ( 32%)] Loss: 0.622711
Training Epoch: 1 [25600/60032 ( 43%)] Loss: 0.551721
Training Epoch: 1 [32000/60032 ( 53%)] Loss: 0.462930
Training Epoch: 1 [38400/60032 ( 64%)] Loss: 0.465403
.......
Training Epoch: 10 [25600/60032 ( 43%)] Loss: 0.184979
Training Epoch: 10 [32000/60032 ( 53%)] Loss: 0.143992
Training Epoch: 10 [38400/60032 ( 64%)] Loss: 0.151426
Training Epoch: 10 [44800/60032 ( 75%)] Loss: 0.283537
Training Epoch: 10 [51200/60032 ( 85%)] Loss: 0.229831
Training Epoch: 10 [57600/60032 ( 96%)] Loss: 0.264431
Remember the test dataset remains unchanged as it is on our local machine compared to the train dataset which we have splitted between two virtual workers.
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += F.nll_loss(
output, target, reduction='sum').item()
pred = output.argmax(1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss,correct,
len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))Test set: Average loss: 0.1762, Accuracy: 9475/10000 (95%)
As you can see, we achieved an accuracy of 95% which is pretty good for a federated sytem as this tutorial has demonstrated. One thing you might want to ask or be curios about is how mch time does the federated learning training takes compared to normal pytorch. The federated approach takes a lttle more time than the normal pytorch but with the technique we implemented and the impact it's quite reasonable to go with this approach. Federated learning could also be implemented in the healthcare domain as health data themselves contain private information about patients. With Federated learning, developers could train their models on healthcare data from various hospitals in a safe and secure manner so as for the model to learn and generalize well from distributed data. This is not the end, federated learning is not enough to protect privacy as there are other concerns about how the models sent for training is being secured, can information about individuals be identified by reverse engineering the updated weights from the model ? Because of this pysyft supports algorithms for concepts like diffential privacy and homomorphic encryption amongst other techniques to preserve privacy on a large scale.
- Check out the Openmined open source community on github https://github.com/OpenMined
- Enroll to the udacity course developed by the openmined team to get a broader overview of privacy in the context of deep learning. Udacity..
- Star the PySyft repository on github and contribute to one of the projects (https://github.com/OpenMined/PySyft)
- Check the tutorials section of the PySyft repository
- Towards federated learning at scale arxiv paper https://arxiv.org/abs/1902.01046
- Andrew Trask pivacy preserving AIoutube video(MIT series) https://www.youtube.com/watch?v=4zrU54VIK6k
- Openmined Psyft repository https://github.com/OpenMined/PySyft