

Modular Deep Reinforcement Learning framework in PyTorch.
 |
 |
 |
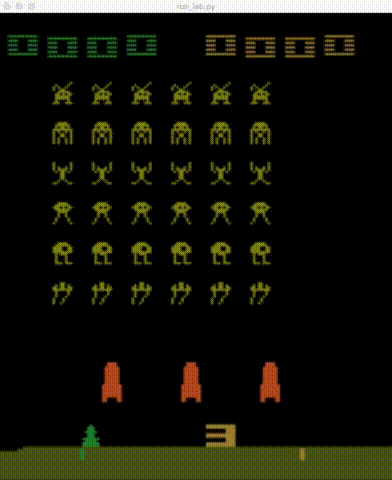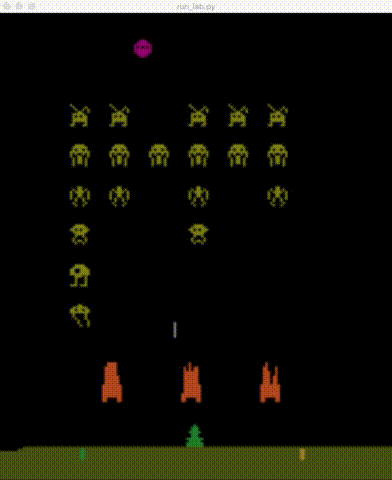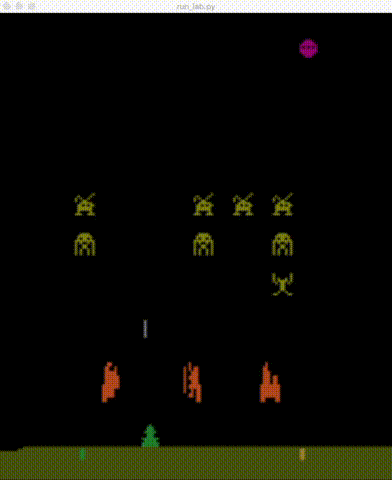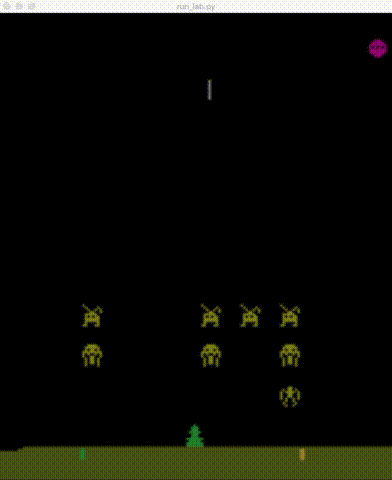 |
| Breakout | Pong | Qbert | Sp.Invaders |
| References | |
|---|---|
| Installation | How to install SLM Lab |
| Documentation | Usage documentation |
| Benchmark | Benchmark results |
| Gitter | SLM Lab user chatroom |
SLM Lab implements a number of canonical RL algorithms with reusable modular components and class-inheritance, with commitment to code quality and performance.
The benchmark results also include complete spec files to enable full reproducibility using SLM Lab.
Below shows the latest benchmark status. See the full benchmark results here.
| Algorithm\Benchmark | Atari | Roboschool |
|---|---|---|
| SARSA | - | - |
| DQN (Deep Q-Network) | ✅ | - |
| Double-DQN, Dueling-DQN, PER-DQN | ✅ | - |
| REINFORCE | - | - |
| A2C with GAE & n-step (Advantage Actor-Critic) | ✅ | |
| PPO (Proximal Policy Optimization) | ✅ | |
| SIL (Self Imitation Learning) | ||
| SAC (Soft Actor-Critic) | ✅ |
Due to their standardized design, all the algorithms can be parallelized asynchronously using Hogwild. Hence, SLM Lab also includes A3C, distributed-DQN, distributed-PPO.
This benchmark table is pulled from PR396. See the full benchmark results here.
| Env. \ Alg. | A2C (GAE) | A2C (n-step) | PPO | DQN | DDQN+PER |
|---|---|---|---|---|---|
Breakout graph  |
389.99 graph |
391.32 graph |
425.89 graph |
65.04 graph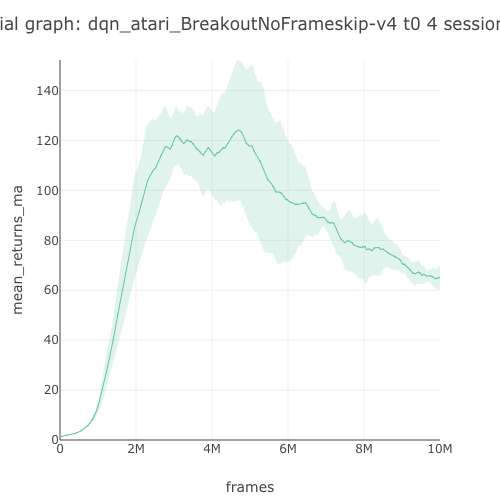 |
181.72 graph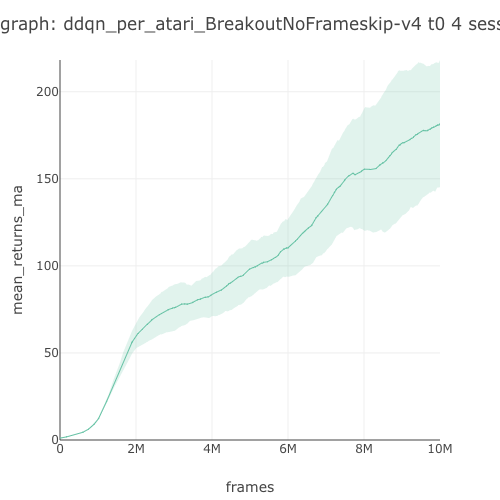 |
Pong graph  |
20.04 graph |
19.66 graph |
20.09 graph |
18.34 graph |
20.44 graph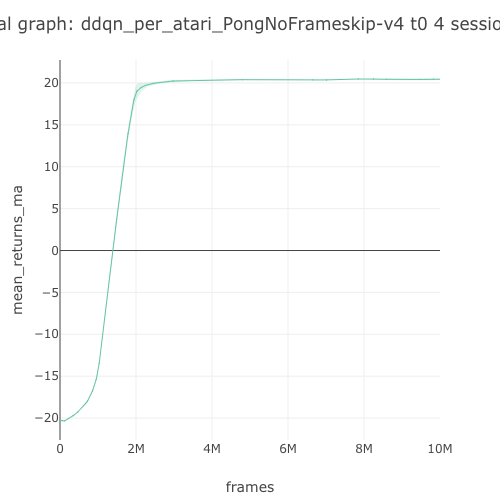 |
Qbert graph 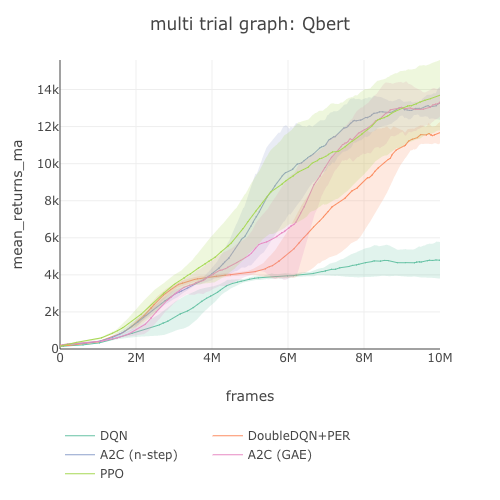 |
13,328.32 graph |
13,259.19 graph |
13,691.89 graph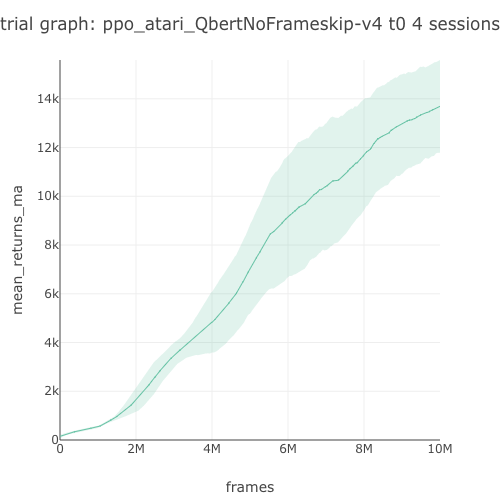 |
4,787.79 graph |
11,673.52 graph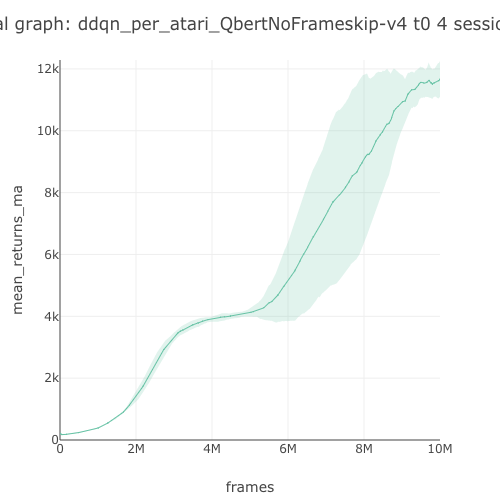 |
Seaquest graph  |
892.68 graph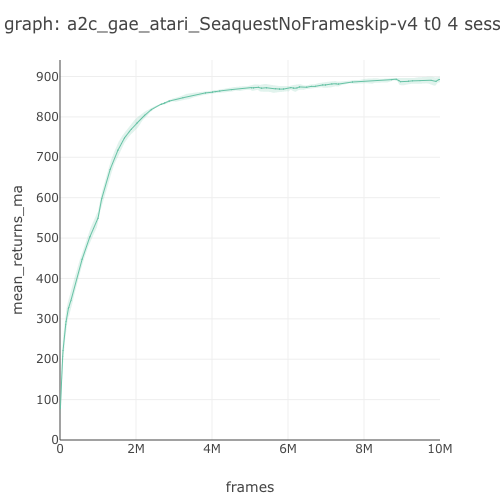 |
1,686.08 graph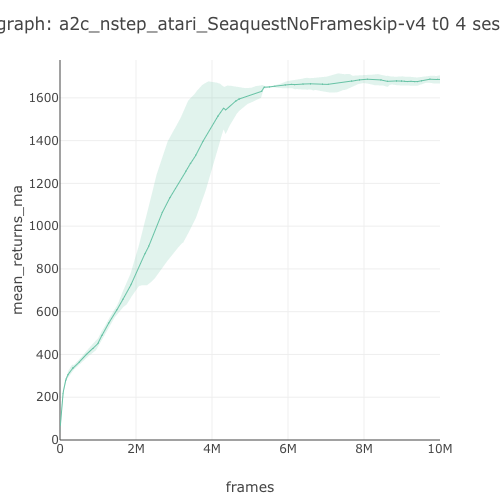 |
1,583.04 graph |
1,118.50 graph |
3,751.34 graph |
SLM Lab integrates with multiple environment offerings:
- OpenAI gym
- OpenAI Roboschool
- VizDoom (credit: joelouismarino)
- Unity environments with prebuilt binaries
Contributions are welcome to integrate more environments!
To facilitate better RL development, SLM Lab also comes with prebuilt metrics and experimentation framework:
- every run generates metrics, graphs and data for analysis, as well as spec for reproducibility
- scalable hyperparameter search using Ray tune
-
Clone the SLM Lab repo:
git clone https://github.com/kengz/SLM-Lab.git
-
Install dependencies (this uses Conda for optimality):
cd SLM-Lab/ ./bin/setup
Alternatively, instead of running
./bin/setup, copy-paste frombin/setup_macOSorbin/setup_ubuntuinto your terminal and addsudoaccordingly to run the installation commands.
Useful reference: Debugging
Non-image based environments can run on a laptop. Only image based environments such as the Atari games benefit from a GPU speedup. For these, we recommend 1 GPU and at least 4 CPUs. This can run a single Atari Trial consisting of 4 Sessions.
For desktop, a reference spec is GTX 1080 GPU, 4 CPUs above 3.0 GHz, and 32 Gb RAM.
For cloud computing, start with an affordable instance of AWS EC2 p2.xlarge with a K80 GPU and 4 CPUs. Use the Deep Learning AMI with Conda when creating an instance.
Everything in the lab is ran using a spec file, which contains all the information for the run to be reproducible. These are located in slm_lab/spec/.
Run a quick demo of DQN and CartPole:
conda activate lab
python run_lab.py slm_lab/spec/demo.json dqn_cartpole devThis will launch a Trial in development mode, which enables verbose logging and environment rendering. An example screenshot is shown below.

Next, run it in training mode. The total_reward should converge to 200 within a few minutes.
python run_lab.py slm_lab/spec/demo.json dqn_cartpole trainTip: All lab command should be ran from within a Conda environment. Run
conda activate labonce at the beginning of a new terminal session.
This will run a new Trial in training mode. At the end of it, all the metrics and graphs will be output to the data/ folder.
Run A2C to solve Atari Pong:
conda activate lab
python run_lab.py slm_lab/spec/benchmark/a2c/a2c_gae_pong.json a2c_gae_pong trainWhen running on a headless server, prepend a command with
xvfb-run -a, for examplexvfb-run -a python run_lab.py slm_lab/spec/benchmark/a2c/a2c_gae_pong.json a2c_gae_pong train

Atari Pong ran with
devmode to render the environment
This will run a Trial with multiple Sessions in training mode. In the beginning, the total_reward should be around -21. After about 1 million frames, it should begin to converge to around +21 (perfect score). At the end of it, all the metrics and graphs will be output to the data/ folder.
Below shows a trial graph with multiple sessions:

Once a Trial completes with a good model saved into the data/ folder, for example data/a2c_gae_pong_2019_08_01_010727, use the enjoy mode to show the trained agent playing the environment. Use the enjoy@{prename} mode to pick a saved trial-sesison, for example:
python run_lab.py data/a2c_gae_pong_2019_08_01_010727/a2c_gae_pong_spec.json a2c_gae_pong enjoy@a2c_gae_pong_t0_s0To run a full benchmark, simply pick a file and run it in train mode. For example, for A2C Atari benchmark, the spec file is slm_lab/spec/benchmark/a2c/a2c_atari.json. This file is parametrized to run on a set of environments. Run the benchmark:
python run_lab.py slm_lab/spec/benchmark/a2c/a2c_atari.json a2c_atari trainThis will spawn multiple processes to run each environment in its separate Trial, and the data is saved to data/ as usual. See the uploaded benchmark results here.
An Experiment is a hyperparameter search, which samples multiple specs from a search space. Experiment spawns a Trial for each spec, and each Trial runs multiple duplicated Sessions for averaging its results.
Given a spec file in slm_lab/spec/, if it has a search field defining a search space, then it can be ran as an Experiment. For example,
python run_lab.py slm_lab/spec/experimental/ppo/ppo_lam_search.json ppo_breakout searchDeep Reinforcement Learning is highly empirical. The lab enables rapid and massive experimentations, hence it needs a way to quickly analyze data from many trials. The experiment and analytics framework is the scientific method of the lab.
 |
 |
| Experiment graph | Experiment graph |
Segments of the experiment graph summarizing the trials in hyperparameter search.
 |
 |
| Multi-trial graph | with moving average |
The multi-trial experiment graph and its moving average version comparing the trials. These graph show the effect of different GAE λ values of PPO on the Breakout environment. λ= 0.70 performs the best, while λ values closer to 0.90 do not perform as well.
 |
 |
| Trial graph | with moving average |
A trial graph showing average from repeated sessions, and its moving average version.
 |
 |
| Session graph | with moving average |
A session graph showing the total rewards and its moving average version.
This is the end of the quick start tutorial. Continue reading the full documentation to start using SLM Lab.
Read on: Github | Documentation
SLM Lab is created for deep reinforcement learning research and applications. The design was guided by four principles
- modularity
- simplicity
- analytical clarity
- reproducibility
- makes research easier and more accessible: reuse well-tested components and only focus on the relevant work
- makes learning deep RL easier: the algorithms are complex; SLM Lab breaks them down into more manageable, digestible components
- components get reused maximally, which means less code, more tests, and fewer bugs
- the components are designed to closely correspond to the way papers or books discuss RL
- modular libraries are not necessarily simple. Simplicity balances modularity to prevent overly complex abstractions that are difficult to understand and use
- hyperparameter search results are automatically analyzed and presented hierarchically in increasingly granular detail
- it should take less than 1 minute to understand if an experiment yielded a successful result using the experiment graph
- it should take less than 5 minutes to find and review the top 3 parameter settings using the trial and session graphs
- only the spec file and a git SHA are needed to fully reproduce an experiment
- all the results are recorded in BENCHMARK.md
- experiment reproduction instructions are submitted to the Lab via
resultPull Requests - the full experiment datas contributed are public on Dropbox
If you use SLM Lab in your research, please cite below:
@misc{kenggraesser2017slmlab,
author = {Wah Loon Keng, Laura Graesser},
title = {SLM Lab},
year = {2017},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/kengz/SLM-Lab}},
}
SLM Lab is an MIT-licensed open source project. Contributions are very much welcome, no matter if it's a quick bug-fix or new feature addition. Please see CONTRIBUTING.md for more info.
If you have an idea for a new algorithm, environment support, analytics, benchmarking, or new experiment design, let us know.
If you're interested in using the lab for research, teaching or applications, please contact the authors.