2019 最新更新,廖老师已经将视频内容转化成图文教程发布到自己的网站,有需要的可以自己去查看,很详细。
廖雪峰java基础课程随堂代码
- 实例创建时调用构造方法
- 构造方法用于初始化实例
- 没有定义构造方法时,编译器会自动创建默认构造方法
- 可以定义多个构造方法,编译器自动根据参数判断
- 重载方法应该完成相同的功能,参考String的indexOf()
- 重载方法主要依靠参数类型和树龄区分
- 不要去交换参数顺序
- 重载方法返回值类型应该相同
- 继承是面向对象变成的一种代码复用方式
- java只允许单继承
- protected允许子类访问弗雷的字段和方法
- 子类构造方法可以通过super()调用父类的构造方法
- 可以安全地向上转型为更抽象的类型
- 可以强制向下转型,最好借助instanceof判断
- 子类和父类的关系时is, has关系不能用继承
- 子类可以覆写父类的方法(override)
- 覆写在子类中改变了父类方法的行为
- 多态:java的方法调用总是作用于对象的世纪类型
- final修饰的方法可以阻止被覆写
- final修饰的class可以阻止被继承
- final修饰的field必须在创建对象时初始化
- 抽象方法定义了子类必须实现的接口规范
- 定义了抽象方法的类就是抽象类
- 从抽象类继承的子类必须实现抽象方法
- 如果不实现抽象方法,则该子类仍是一个抽象类
- 抽象方法不能实例化(My add)
- 如果一个抽象类没有字段,所有方法都是抽象方法,就可以吧该抽象类改为接口(interface)
- 接口定义的方法默认是public abstract(不需要写)
- 一个类可以实现多个interface
| interface | abstra class | interface |
|---|---|---|
| 继承 | 只能extends一个clas | 可以implements多个interface |
| 字段 | 可以定义实例字段 | 不能定义实例字段 |
| 抽象方法 | 可以定义抽象方法 | 可以定义抽象方法 |
| 非抽象方法 | 可以定义非抽象方法 | 可以定义default方法 |
-
一个interface可以继承自另一个interface
-
interface继承自interface使用extends
-
接口继承接口相当于扩展了接口的方法
-
接口类定义了纯抽象方法
-
类可以实现多个接口
-
接口也是数据类型,适用于向上转型和向下转型
-
接口不能定义实例字段
-
接口可以定义default方法(JDK >= 1.8)
用static修饰的字段为静态字段
- 普通字段在每个实例中都有自己的一个独立空间
- 静态字段只有一个共享空间,所有实例都共享该字段
用static修饰的方法成为静态方法
- 调用实例方法必须通过实例变量
- 调用静态方法不需要实例变量
- 静态方法不能访问this变量(this变量是实例化后实例的别名,静态方法存在于实例化之前,所以不能使用this)
- 静态方法不能访问实例字段(同样的道理)
- 静态方法可以访问静态字段
静态方法通常用于工具类
- Arrays.sort()
- Math.random()
静态方法通常用于辅助方法
Java程序入口函数main()也是静态方法
- 静态字段属于所有实例"共享"的字段,实际上是属于class的字段
- 调用静态方法不需要实例,因此无法访问this(可能是相反的原因)
- 静态方法可以访问静态字段和其他静态方法
- 静态方法常用语工具类和辅助工具
- 如果不确定是否需要public,就不声明public,即尽可能少地暴露对外方法,从private改为public很容易,但是从public改为private很容易出错。
- 尽可能把局部变量的作用域缩小
- 尽可能延后声明局部变量
- final与访问权限不冲突
- final修饰class可以阻止被继承
- final修饰方法阻止被覆写
- final修饰field可以阻止被重新赋值
- final修饰局部变量可以阻止被重新赋值
- java内建访问权限有public、protected、private和package
- java在方法内部定义的变量是局部变量
- 局部变量作用域从声明开始到块结束
- final修饰符不是访问权限,可以同访问权限一起使用
- 一个java文件只能包含一个public class, 但是可以包含多个非public class
- classpath是一个环境变量
- classpath指示JVM如何搜索class
- classpath设置的搜索路径与操作系统相关
classpath设定方法:
- 直接在系统环境中设置classpath环境变量(不推荐)
- 在启动JVM时设置classpath变量(推荐)
- java -classpath /usr/share com.feiyangedu.Hello
- java -cp /usr/share com.feiyangedu.Hello
- 没有设置环境变量也没有指定-cp参数时,默认classpath为.,即当前目录
- eclipse中运行java程序默认传入的cp参数是当前工程的bin目录和引入的jar
jar包
- jar包相当于目录
- 包含若干class文件
- 使用jar包可以避免大量的目录和class文件
- META-INF/MANIFEST.MF可以提供jar包信息,如Main-Class
- 不需要在classpath中引入包含java核心类的rt.jar
String特点:
- 内容不可变
- 可以直接使用"……"
- equals(Object)
- boolean contains(CharSequence)
- trim(),移除首位空字符(空格、\t、\r、\n),trim不改变字符串的内容,而是返回新的字符串
- subString()
- 字符串操作不改变原来字符串内容,而是返回新的字符串
- 常用字符串操作:提取字串、查找、替换、大小写转换等
- 字符串和byte[]转换时需要注意编码,建议使用UTF-8编码
- StringBuilder可以高效拼接字符串
- StringBuilder是可变对象,会预先分配缓冲区。
- 可以进行链式操作,实现链式操作的关键是返回实例本身。
StringBuffer
- StringBuffer是StringBuilder的线程安全版本,接口与StringBuilder完全相同
- 没有必要使用StringBuffer
java数据类型:
- 基本类型:int,boolean, float……
- 引用类型:所有class类型
基本类型不可以当作一个对象,要想以对象访问,就需要包装类型 JDK为每种类型都创建类对应的包装类型
| 基本类型 | 对应的引用类型 |
|---|---|
| boolean | Boolean |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
例如:
Integer n = new Integer(99);
int i = n.intValue();int i = 100;
Integer n1 = new Integer(i);
Integer n2 = Integer.valueOf(i);
Integer n3 = Integer.valueOf("100");
int x1 = n1.intValue();
int x2 = Integer.parseInt("100");
String s = n1.toString();
//注意这个getInteger,并不是从字符串中获取整数,而是从系统环境变量中获取相应的值
Integer prop = Integer.getInteger("cpus");- 编译器可以自动在int和Integer之间转型:
- 自动装箱(auto boxing):int -> Integer
- 自动拆箱(auto unboxing):Integer -> int
- 自动装箱和自动拆箱只发生在编译阶段
- 装箱和拆箱会影响执行效率
- 编译后的class代码是严格区分基本类型和引用类型的
- Integer -> int 执行时可能会报错(如果实例对象为null,则拆箱失败:NullPointException)
- java包装类型定义了一些有用的静态变量
- java包装类型全部继承自Number这个类
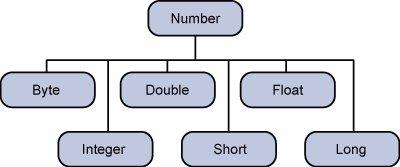
- JDK的包装类型可以把基本类型包装成class
- 自动装箱和拆箱是编译器完成的(JDK >= 1.5)
- 装箱和拆箱会影响执行效率
- 注意拆箱可能发生NullPointException
- JavaBean是一种符合命名规范的class
- JavaBean通过getter/setter来定义属性
- 属性是一种通用的叫法,并非Java语法规定
- 可以利用IDE快速生成getter和setter
- 使用Introspector.getBeanInfo获取属性列表
- enum可以定义常亮类型,它被编译器编译为:final class Xxx extends Enum {...}
- name()获取常量定义的字符串,注意不要使用toString()(toString方法可能被覆写)
- ordinal()返回常量定义的顺序(无实质意义)
- 可以为enum类编写构造方法、字段和方法
- 构造方法声明为private(不声明也可以JDK10)
Math
Math提供了数学计算的静态方法
-
abs / min / max
-
pow / sqrt / exp / log / log10
-
sin / cos / tan / asin / acos ...
-
常量
- PI = 3.14159...
- E = 2.71828...
-
Math.random()方法生成一个随机数:
- 0 <= Math.random() < 1
- 可用于生成某个区间的随机数
long MIN = 1000;
long MAX = 9000;
double x2 = Math.random() * (MAX - MIN) + MIN;
double r = (long) x2;Random
Random用来创建伪随机数
- nextInt / nextLong / nextFloat...
- nextInt(N)生成不大于N的随机数
- 什么是伪随机数?
- 给定种子后伪随机数算法会生成完全相同的序列
- 不给定种子时Random使用系统当前时间戳作为种子
SecureRandom
SecureRandom用于创建安全的随机数,缺点是比较慢
BigInteger
BigInteger用任意多个int[]来表示非常大的整数。
BigDecimnal
BigDecimal表示任意精度的浮点数。
BigInteger和BigDecimnal多用于财务计算中。
- 计算机运行过程中错误是不可避免的
Java异常体系:
- Java规定必须捕获的异常是Exception及其子类,但不包括RuntimeException及其子类
- Java使用异常来表示错误,通过try{...} catch {...}捕获异常
- Java的异常是class,并且从Throwable集成
- Error是无需捕获的严重错误
- Exception是应该捕获的可处理的错误
- RuntimeException无需强制捕获,非RuntimeException(CheckedException)需要强制捕获,或者用throws声明。
- 断言是一种调试方式,断言失败会抛出AssertionError
- 只能在开发和测试阶段启动断言
- 对可恢复的错误不能使用断言,而应该抛出异常
- 断言很好被使用,更好的方法是编写单元测试。
- 日志是为了替代System.out.println(),可以定义格式,重定向到文件。
- 日志可以存档,便于问题追踪
- 日志可以按级别分类,便于打开和关闭某些级别
- 可以根据配置文件调整日志,无需修改代码
- JDK提供了Logging:java.util.logging
-
Commons Logging定义了6个日志级别:
- FATAL
- ERROR
- WARNING
- INFO <---------------默认级别
- DEBUG
- TRACE
-
Commons Logging 是使用最广泛的日志模块
-
Commons Logging 的API非常简单
-
Commons Logging 可以自动使用其他日志模块
- 目前最流行的日志框架:
- 1.x: Log4j
- 2.x: Log4j2
- 始终使用Commons Logging接口来写入日志
- 开发阶段无需引入Log4j
- 使用Log4j只需要把正确的配置文件和相关的jar包放入classpath
- 使用配置文件可以灵活修改日志,无需修改代码
- 如果要更换Log4j,只需要移除log4j.xml和相关jar包
- 只有扩展log4j时,才需要引入Log4j的接口
- JVM为每个class创建对应的Class实例来保存class的所有信息
- 获取一个class对应的Class实例后,就可以获取该class的所有信息
- 通过class实例获取class信息的方法称为反射Reflection
- JVM总是动态加载class,可以在运行期根据条件控制加载class
- Field字段封装了字段的所有信息
- 通过Class实例的方法可以获取Filed实例:getField / getFields / getDeclaredField / getDeclaredFields
- 通过Field实例可以获取字段信息:getName / getType / getModifiers
- 通过Field实例可以读取或设置某个对象的字段: get(Object name) / set(Object instance, Object fieldValue)
- 通过设置setAccessible(true)来访问非public字段,但是注意:setAccessible(true)可能会失败,如果jvm定义来SecurityManager,并且SecurityManager的规则阻止对该Field设置accessible,就会导致失败
- Method对象封装了方法的所有信息
- 通过class实例的方法可以获取Method实例:getMethod / getMethods / getDeclaredMethod / getDeclaredMehtods
- 通过Method实例可以获取方法信息:getName / getReturnType / getParameterTypes / getModifiers
- 通过Method实例可以调用某个对象的方法:Object invoke(Object instance, Object... parameters)
- 通过设置setAccessible(true)来访问非public方法
- Constructor对象封装来构造函数的所有信息
- 通过Class实例的方法可以获取Constructor实例: getConstructor / getConstructors / getDeclaredConstructor / getDeclaredConstructors
- 通过Constructor实例可以创建一个实例对象:newInstance(Object... parameters)
- 通过设置setAccessible(true)来访问非public构造方法
- 通过Class对象获取继承关系:
- getSuperclass()
- getInterfaces()
- 通过Class对象的isAssignableFrom()方法可以判断一个向上转型是否正确。
- 泛型就是编写模板代码来适应任意类型
- 不必对类型进行强制转换
- 编译器将对类型进行检查
- 注意泛型的继承关系:
- 可以把ArrayList向上转型为list(T不能变)
- 不能把ArrayList向上转型为ArrayList
- 使用泛型时,把泛型参数替换为需要的class类型:List list = new ArrayList()
- 可以省略编译器能自动推断出的类型:List list = new ArrayList<>()
- 不指定泛型参数类型时,编译器会给出警告,且只能将视为Object类型
- 编写泛型事,需要定义泛型类型
public class Pair<T> {...}- 静态方法不能引用泛型类型,必须定义其他类型来实现“泛型”
public static <K> Pair<K> create(K first, K last) {...}- 泛型可以同事定义多种类型<T, K>
public class Pair<T, K> {...}- Java的范型采用擦拭法实现
- 擦拭法决定来范型:
- 不能是基本类型,例如int
- 不能获取带范型类型的Class,如:Pair.class
- 不能判断带范型类型的类型, 如:x instanceof Pair
- 不能实例化T类型,如:new T()
- 范型方法要防止重复定义方法,例如:public boolean equals(T obj)
- 子类可以获取父类的范型类型
- 部分反射API是范型:
- Class
- Constructor
- 可以声明带泛型的数组,但是不能直接创建带泛型的数组,必须潜质转型
- 可以通过Array.newInstance(Class, int)创建T[]数组,需要强制转型
- java集合定义在java.util包中
- 常用的集合类包括List、Set、Map等
- Java集合使用统一的Iterator遍历集合
- 尽量不要使用遗留接口
- ArrayList VS LinkedList:
| ArrayList | LinkedList | |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加删除元素 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
list的特点
- 按照索引顺序访问的长度可变的链表
- 优先使用ArrayList而不是LinkedList
- 可以直接使用for……each遍历
- 可以和Array相互转换
如果在List中查找元素:
- List的实现类通过元素的equals方法比较两个元素
- 放入的元素必须正确覆写equlals方法, JDK提供类的String,Integer等已经覆写类eauqls方法
- 编写equals方法可借助Object.equals()判断
如果不在List中查找元素:
- 不必覆写equals方法
- Map<K, V>是一种映射表,可以通过Key快速查找Value
- 可以通过for……each遍历KeySet()
- 可以通过for……each遍历entryset()
- 需要对Key排序时使用TreeMap
- 通常使用HashMap
- 作为Key的对象必须正确覆写equals和hashCode
- 一个类如果覆写类equals,就必须覆写hashCode
- hashCode可以通过Objects.hashCode()辅助实现
- Set用于存储不重复的元素集合
- 放入set的元素与作为Map的Key的要求相同,正确实现equals方法和hashCode方法。
- 利用set可以取出重复元素
- 遍历SortedSet按照元素的排序顺序遍历,也可以自定义排序算法。
- Queue是一个先进先出的队列
- LinkedList实现了Queue接口
- 获取队列长度:size()
- 添加元素到队列:boolean add(E e) / boolean offer(E e)
- 获取队列头部元素病删除: E remove() / E poll()
- 获取队列头部元素但不删除:E element() / E peek() 操作队列时都提供了两种方法的原因是,获取失败时:
| throw Exception | 返回false或null | |
|---|---|---|
| 添加元素到队列 | add(E e) | boolean offer(E e) |
| 取队首元素并删除 | E remove() | E poll() |
| 取队首元素但不删除 | E element() | E peek() |
-避免把null添加到队列
- PriorityQueue的出队顺序与元素的优先级相关:remove()/poll()总是取优先级最高的元素
- PriorityQueue具有Queue的接口:操作与Queue相同(参考上面的使用Queue)
- PriorityQueue实现一个优先队列
- 从队首后去元素时,总是获取优先级最高的元素
- 默认按元素比较的顺序排序(必须实现Comparable接口)
- 可以通过Comparator自定义排序算法(不必实现Comparable接口)
- Deque实现了一个双端队列(Double Ended Queue):既可以添加到队尾,也可以添加到队首;既可以从队首获取,又可以从队尾获取
| Queue | Deque | |
|---|---|---|
| 添加元素到队尾 | add(E e)/offer(E e) | addLast(E e)/offerLast(E e) |
| 取队首元素并删除 | E remove()/E poll() | E removeFirst()/E pollFirst() |
| 取队首元素但不删除 | E element()/E peek() | E getFirst()/E peekFirst() |
Deque特有方法:
| Queue | |
|---|---|
| 添加元素到队首 | addFirst(E e)/offerFirst(E e) |
| 取队尾元素并删除 | E removeLast()/E pollLast() |
| 取队尾元素但不删除 | E getLast()/E peekLast() |
- 栈是一种后进先出的数据结构。
- 使用Deque实现Stack的功能
- 操作栈的元素的方法:
- push(E e):压栈
- pop():出栈
- peek():取出栈顶元素但不出栈
- Java使用Deque实现栈的功能,注意只调用push/pop/peek,避免使用Deque的其他方法
- 不要使用遗留类Stack
- Java的集合类可以实现for……each循环:List、Set、Queue、Deque。
- 如何让自己编写的集合类使用for……each循环:
- 实现Iterable接口
- 返回Iterator对象
- 用Iterator对象迭代
- 使用Iterator的好处:
- 对任何集合都采用同一种访问模型
- 调用者对集合内部结构一无所知
- 集合返回的Iterator对象知道如何迭代
- Iterator是一种抽象的数据访问模型
- Collections是JDK提供的工具类:
-
创建空集合
- List emptyList()
- Map(K, V) emptyMap()
- Set emptySet()
-
对List排序(必须传入可变List)
- void sort(List list)
- void sort(List list, Comparator<? super T> c)
-
随机重置List元素
- void shuffle(List<?> list)
-
创建单元素集合
- Set singleton(T o)
- List singletonList(T o)
- Map<K, V> singletonMap(K key, V value)
-
创建不可变集合
- List unmodifiableList(List<? extends T> list)
- Set unmodifiableSet(Set<? extends T> set)
- Map<K, V> unmodifiableMap(Map<? extends K, ? extends V> m)
-
排序/洗牌
-
……
-
- IO指输入输出:
- 输入是指从外部读数据到内存,例如,读文件,从网络读取数据等。
- 输出是把数据从内存输出到外部,比如写文件,输出到网络
- IO流是一种顺序读写数据的模式
- 单向流动
- 以byte为最小单位(字节流)
- 如果字符不是单字节表示的ASCII:
- Java提供了Reader/Writer表示字符流
- 字符流传输的最小数据单位是char
- 字符流输出的byte取决于编码方式
- Reader/Writer本质上是一个能自动编解码的InputStream/OutputStream
- 同步IO
- 读写IO时代码等待数据返回后才继续执行后续的代码
- 代码编写简单,CPU执行效率地
- 异步IO
- 读写IO时仅发出请求,然后立刻执行后续代码
- 代码编写复杂,CPU执行效率高
- JDK提供的java.io是同步IO
- JDK提供的java.nio是异步IO
| 抽象类 | InputStream | OutputStream | Reader | Writer |
|---|---|---|---|---|
| 实现类 | FileInputStream | FileOutputStream | FileReader | FileWriter |
- Java的IO流的接口和实现是分离的:
- 字节流接口:InputStream / OutputStream
- 字符流接口:Reader/ Writer
- java.io.File表示文件系统一个文件或者目录
- 创建File对象本身不涉及IO操作
- 获取路径/绝对路径/规范路径:getPath() / getAbsolutePath() / getCanonicalPath()
- 可以获取目录的文件和子目录
- 通过File对象可以创建或删除文件和目录
- java.io.InputStream是所有输入流的超类
- abstract int read():读取下一个字节,并返回字节(0-255),如果读到末尾,返回-1
- int read(byte[] b):读取若干字节病填充到byte[]数组,返回读取的字节数
- int read(byte[] , int off, int len):指定byte[]数组的偏移量和最大填充数
- void close():关闭输入流
- InputStream定义了所有输入流的超类
- FileInputStream实现了文件流输入
- ByteArrayInputStream在内存中模拟一个字节流输入
- 使用try(resource)保证InputStream正确关闭
- java.io.OutputStream是所有输出流的超类
- abstract write(int b):吸入一个字节
- void write(byte[] b):写入byte[]数组的所有字节
- void write(byte[] b, int off, int len):写入byte[]数组指定范围的字节
- void close():关闭输出流
- void flush():将缓冲区内容输出(像磁盘网络设备并不是输出一个字节就立即写入,而是先把输出的字节放到内存的缓冲区中,等待缓冲区满后再一次性写入设备)
- OutputStream定义了所有输出流的超类
- FileOutputStream实现了文件流输出
- ByteArrayOutputStream在内存中模拟一个字节流输出
- 使用try(resource)保证OutputStream正确关闭
- JDK提供的InputStream包括:
- FileOutputStream:从文件中读取数据
- ServletInputStream:从HTTP请求读取数据
- Socket.getInputStream:从TCP连接读取数据
- ……
- Java IO使用Filter模式为InputStream和OutputStream增加功能
- 可以把一个InputStream和任意FilterInputStream组合
- 可以把一个OutputStream和任意的FilterOutputStream组合
- Filter模式可以在运行期间动态增加功能(又称Decorator模式)
- ZipInputStream是一种FilterInputStream:
- JarInputStream --> ZipInputStream --> InflaterInputStream --> FilterInputStream --> InputStream
- 可以直接读取Zip的内容
- ZipOutputStream是一种OutputStream:可以直接写入Zip文件内容
- ZipInputStream和ZipOutputStream都是FilterInputStream和FilterOutputStream
- 配合FileInputStream和FileOutputStream就可以读写Zip文件
- Java存放.class或jar包的目录也可以包含任意其他类型的文件
- 从classpath读取文件可以避免不同环境下文件路径不一致的问题
- 把资源存储在classpath中可以避免文件路径依赖
- Class对象的GetResourceAsStream()可以从classpath读取资源
- 需要检查返回的InputStream是否为null
- 序列化是指把一个java对象边城二进制内容(byte[])
- 序列化后可以把byte[]保存到文件中
- 序列化后可以把byte[]通过网络传输
- 一个Java要能序列化,必须实现Serializable接口:
- Serializable接口没有定义任何方法
- 空接口被称为“标记接口”(Marker Interface)
- 反序列化是指一个二进制内容(byte[])变成Java对象
- 反序列化后可以从文件读取byte[]并变为Java对象
- 反序列化后可以从网络读取byte[]并变为Java对象
- 反序列化时不调用构造方法
- 可设置serialVersionUID作为版本号(非必须)
- Java序列化机制仅适用于Java,如果需要与其他语言交换数据,必须使用通用的序列化方法,比如JSON
java.io.Reader和java.io.InputStream的区别:
| InputStream | Reader |
|---|---|
| 字节流,以byte为单位 | 字符流,以char为单位 |
| 读取字节(-1,0-255):int read() | 读取字符(-1, 0-65535):int read() |
| 读到字节数组:int read(byte[] b) | 读到字符数组:int read(char[] c) |
| int read(byte[] b, int offset, int len) | int read(char[] c, int offset, int len) |
- java.io.Reader是所有字符输入流的超类:
- int read():读取一个字符,并返回字符(0-65535),如果已读到末尾,返回-1
- int read(char[] c):读取若干字符并填充到char[]数组,返回读取的字符数
- int read(char[] c, int off, int len):指定char[]数组的偏移量和最大填充数
- void close():关闭Reader
- Reader定义了所有字符输入流的超类
- FileReader实现了文件字符流输入
- CharArrayReader在内存中模拟一个字符流输入
- Reader是给予InputStream构造的
- FileReader使用系统默认编码,无法指定编码
- 可以通过InputStreamReader指定编码
- 使用try(resource)保证Reader正确关闭
java.io.Writer和java.io.OutputStream的区别:
| OutputStream | Writer |
|---|---|
| 字节流,以byte为单位 | 字符流,以char为单位 |
| 写入字节(0-255):void write(int b) | 写入字符(0-65535):int write() |
| 写入字节数组:int write(byte[] b) | 写入字符数组:int write(char[] c) |
| int write(byte[] b, int offset, int len) | int write(char[] c, int offset, int len) |
| void write(String s) |
- java.io.Writer是所有字符输入流的超类:
- int write(int c):写入一个字符(0-65535)
- int write(char[] c):写入若干字符数组的所有字符
- int write(char[] c, int off, int len):写入数组指定范围的字符
- void write(String s):写入String表示的所有字符
- FileWriter实现了文件字符流输出
- CharArrayWriter在内存模拟一个字符流输出
- Writer基于OutputStream构造
- FileWriter使用系统默认编码,无法指定编码,可以通过OutputStreamWriter指定编码
- 使用try(resource)保证Writer正确关闭
- 理解日期、时间和时刻
- 理解时区的概念
- 理解夏令时,同一地区使用GMT/UTC和城市表示的时区可能导致时间不同
- GTM-05:00
- America/New_York
- 理解locale用来针对当地用户习惯格式化日期、时间、数字、货币等。
java.util.date的问题:
- 不能转换时区
- 日志和时间的加减不方便
- 两个日期相差多少天不好计算
- 计算某个月第一个星期一不方便
- ……
总结
- 理解epoch time
- Java有两套日期和时间的API
- java.util.Date/Calendar
- java.time
- 正确使用java.util.Date
- Date和long的转换
- Date和String的转换:SimpleDateFormat
- Calendar和Date、long可以相互转换
- Calendar可以用set/get设置和获取指定字段
- Calendar可以实现:
- 设置特定的日期和时间
- 设置时区并获得转换后的时间
- 加减日期和时间
- TimeZone表示时区,getAvailableDs()可以美剧所有有效的时区ID
- LocalDateTime无法与long进行转换
- 因为LocalDateTime没有时区,无法确定某一时刻
- ZonedDateTime有时区,可以与Long进行转换 LocalDate、LocalTime、LocalDateTime
- 不变类
- 默认按照ISO 8601标准格式化和解析
- 使用DateTimeFormatter自定义格式化和解析
- 使用plusDays()/minusHours()等方法对日期和时间进行加减,返回新对象
- 使用withDayOfMonth()/with()等方法调整日期和时间,返回新对象
- 使用isBefore()/isAfter()/equals()判断日期和时间的先后
ZonedDateTime = LocalDateTime + Zoneld
- ZonedDateTime:带时区的日期和时间
- Zoneld:新的时区对象(取代旧的java.util.TimeZone)
- Instant:时刻对象(epoch seconds)
| 数据库 | 对应Java类(旧) | 对应Java类(新) |
|---|---|---|
| DATETIME | java.util.Date | LocalDateTime |
| Date | java.sql.Date | LocalDate |
| TIME | java.sql.Time | LocalTime |
| TIMESTAMP | java.sql.Timestamp | LocalDateTime |
- 尽量使用java.time提供的API处理日期和时间
- 存储到数据库:
- 日期:LocalDate -> DATE
- 时间:LocalTime -> TIME
- 日期 + 时间: LocalDateTime -> DATETIME
- 时刻:long -> BIGINT
- 显示日期和时间:long -> String
- 让JDK处理时区
- 不要手动调整时差
String epochToString(long epoch, Local lo, String zoneId) {
Instant ins = Instant.ofEpochMilli(epoch);
DateTimeFormatter f = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.MEDIUM, FormatStyle.SHORT);
return f.withLocale(lo).format(ZonedDateTime.ofInstant(ins, ZoneId.of(zoneId)));
}
输入:
epoch = 1480468500000L
Locale.CHINA, "Asia/Shanghai"
Locale.US, "America/New_York"
输出:
2016-11-30 上午9:15
Nov 29, 2016 8:15 PM-
什么是单元测试?
- 单元测试是针对最小的功能单元编写测试代码
- Java程序最小功能单元是方法
- 单元测试就是针对单个Java方法的测试
-
测试驱动开发(TDD):
- 编写接口 -> 编写测试 -> 编写实现 <-N-> 运行测试 -Y-> 任务完成
-
单元测试的好处
- 确保单个方法运行正常
- 如果修改了方法代码,只需要确保其对应的单元测试通过
- 测试代码本身就可以作为示例代码
- 可以自动化运行所有测试病获得测试报告
-
JUnit是一个开源的Java语言的单元测试框架
- 专门针对Java语言设计,使用最广泛
- JUnit是事实上的标准单元测试框架
- JUnit使用断言(Assertion)测试期望结果
- 可以方便地组织和运行测试
- 可以方便地查看测试结果
- 常用IDE都集成了JUnit
- 可以方便地集成到Maven
-
JUnit设计:
- TestCase: 一个TestCase便是一个测试
- TestSuite: 一个TestSuite包含一组TestCase,表示一组测试
- TestFixture: 一个TestFixture表示一个测试环境
- TestResult: 用于收集测试结果
- TestRunner: 用于运行测试
- TestListener: 用于监听测试过程, 收集测试数据
- Assert: 用于断言测试结果是否正确
-
JUnit目前的版本 3.x/4.x/5.x
| 版本 | JUnit 3.x | JUnit 4 | JUnit 5 |
|---|---|---|---|
| JDK | JDK < 1.5 | JDK >= 1.5 | JDK >= 1.8 |
| class | class MyTest extends TestCase{} | class MyTest{} | class MyTest{} |
| method | public testAbc(){} | @Test public abc(){} | @Test public abc(){} |
- 使用Assert断言:
- 断言相等:assertEquals(100, x)
- 断言数组相等:assertArrayEquals({1,2,3}, x)
- 断言浮点数相等:assertEquals(4.2353, x, 0.0001)
- 断言为null:assertNull(x)
- 断言为true/false:assertTrue(x>0) assertFalse(x<0)
- 其他:assertNotEquals/assertNotNull
- 一个TestCase包含一组相关的测试方法
- 使用Assert断言测试结果(注意指定浮点数assertEquals要指定delta)
- 每个测试方法必须完全独立
- 测试代码必须非常简单
- 不能为测试代码再编写测试
- 测试需要覆盖各种输入条件,特别是边界条件
##使用JUnit
- 理解JUnit执行测试生命周期
- @Before用于初始化测试对象,测试对象以实例变量存放
- @After用于清理@Before创建的对象
- @BeforeClass用于初始化耗时资源,以静态变量存放
- @AfterClass用于清理@BeforeClass创建的资源
- 测试异常可以使用@Test(excepted = Exception.class)
- 对可能发生的每种类型的异常进行测试
- @Test(timeout=1000)可以设置超时
- timeout单位是毫秒
- 超时测试不能取代性能测试和压力测试
- 正则表达式是一个字符串
- 正则表达式用字符串描述一个匹配规则
- 使用正则表达式可以快速判断给定的字符串是否符合匹配规则
- Java内建正则表达式引擎是java.util.regex
正则表达式匹配规则:
| 正则表达式 | 规则 | 可以匹配 |
|---|---|---|
| A | 指定字符 | A |
| \u548c | 指定Unicode字符 | 和 |
| . | 任意字符 | a, b, &, 0 |
| \d | 0-9 | 0, 1, 2, ..., 9 |
| \w | a-z, A-Z, 0-9, _ | a, A, 0, _, ... |
| \s | 空格,Tab键 | ' ', ' ' |
| \D | 非数字 | a, A, &, _, ... |
| \W | 非\w | &, @, 中, ... |
| \S | 非\s | a, A, @, _, ... |
| AB* | 匹配任意个数字符 | A,AB, ABB, ABBB, ... |
| AB+ | 至少一个字符 | AB, ABB, ABBB, ... |
| AB? | 0个或1个字符 | A,AB |
| AB{3} | 指定个数字符 | ABBB |
| AB{1, 3} | 指定范围个数字符 | AB, ABB, ABBB |
| AB{2, } | 至少n个字符 | ABB, ABBB, ... |
| AB{0, 3} | 最多n个字符 | A, AB, ABB, ABBB |
复杂规则:
| 正则表达式 | 规则 | 可以匹配 |
|---|---|---|
| ^ | 开头 | 字符串开头 |
| $ | 结尾 | 字符串结束 |
| [ABC] | [...] 内任意字符 | A, B, C |
| [A-F0-9xy] | 指定范围的字符 | A, ..., F, 0, ..., 9, x, y |
| [^A-F] | 指定范围外的任意字符 | 非A, ..., F |
| AB|CD | AB或CD | AB, CD |
| AB|CD|EFG | AB或CD或EFG | AB, CD, EFG |
- 使用'()'可以分组匹配,比如"(\d{4})-(\d{1,2})-(\d{1,2})"
- 反复使用一个正则表达式字符串匹配效率比较低,可以把正则表达式字符串编译为Pattern对象
- 使用Matcher.group(n)可以快速提取子串
- group(0)表示匹配整个字符串
- group(1)表示匹配第一个字符串
- group(2)表示匹配第二个字符串
^(\d+)(0*)$
期望结果:
| input | \d+ | 0* |
|---|---|---|
| 123000 | "123" | "000" |
| 10100 | "101" | "00" |
| 1001 | "1001" | "" |
实际结果:
| input | \d+ | 0* |
|---|---|---|
| 123000 | "123000" | "" |
| 10100 | "10100" | "" |
| 1001 | "1001" | "" |
因为正则表达式默认使用贪婪匹配,会尽可能多地向后匹配,使用?实现费贪婪匹配,^(\d+?)(0*)$
^(\d+??)(9*)$ :第一个?表示匹配0个或1个9,第二个?表示费贪婪匹配,所以会尽可能少地匹配9。 如果待匹配字符串是'9999',则匹配0个9
-
使用正则表达式分割字符串:
String[] String.split(String regex)
"a b c".split("\\s") //{"a", "b", "c"}
"a b c".split("\\s") //{"a", "b", "", "c"}
"a b c".split("\\s+") //{"a", "b", "c"}
"a, b ;; c".split("[\\,\\;\\s]+") //{"a", "b", "c"}-
使用正则表达式搜索字符串:
Matcher.find() -
使用正则表达式替换字符串 String.replaceAll()
-
数据安全的方式
- 防窃听
- 防篡改
- 防伪造
-
古代加密方式:
- 移位密码: HELLO -> IFMMP
- 替代密码: HELLO -> p12,5,3
-
设计一个安全的加密算法非常困难
-
验证一个加密算法是否安全更加困难
-
当前被认为安全的加密算法仅仅是迄今为止尚未被攻破
-
不要自己设计加密算法
-
不要自己实现加密算法
-
不要自己修改已有的加密算法 (可能是认为我们自己设计或修改的不够好吧)
- URL编码是编码算法,不是加密算法
- URL编码的目的是把任意文本数据编码为%为前缀表示的文本,编码后的文本仅包含A-Z, a-z, 0-9, -_.*, %, 便于浏览器和服务器处理
- 是一种把二进制数据用文本表示的编码算法
- 使用Base64的目的是什么?
- 一种用文本(A-Z, a-z, 0-9, +/=)表示二进制内容的方式
- 适用于文本协议
- 效率下降
- 应用
- 电子邮件协议
- Base64是一种编码算法,不是加密算法
- Base64编码的目的是把任意二进制数据编码为文本(长度增加1/3)
- 其他编码:Base32, Base48, Base58
- 摘要算法(哈希算法/Hash/Digest/数字指纹)
- 计算任意长度数据的摘要(固定长度)
- 相同的输入数据始终得到相同的输出
- 不同的输入数据尽量得到不同的输出
- 目的:
- 验证原始数据是否被篡改
- MD5是一种常用的哈希算法,输出128bits / 16bytes
- 常用于验证数据的完整性
- 用于存储口令时需要考虑彩虹表攻击
SHA-1算法:
- 一种哈希算法
- 输出160 bits / 20 bytes
- 美国国家安全局开发
SHA-0/ SHA-1 / SHA-256 / SHA-512- SHA-1算法是比MD5更加安全的哈希算法
- 第三方提供的一组加密/哈希算法
- 提供JDK没有提供的算法
- RipeMDL60哈希算法
- 使用第三方算法前需要通过Security.addProvider()注册
- Hmac:Hash-based Message Authentication Code
- 基于密钥的消息认证码算法
- 更安全的消息摘要算法
- Hmac是把Key混入摘要的算法
- 可以配合MD5、SHA-1等摘要算法
- 摘要长度和原摘要长度算法相同
- 对称加密算法使用同一个密钥进行加密和解密
- 常用算法:DES/AES/IDEA等
- 密钥长度由算法设计决定,AES的密钥长度是128/192/256
- 使用256位加密需要修改JDK的policy文件
- 使用对称加密算法需要指定:算法名称/工作模式/填充模式
PBE:Password Based Encryption
- 由用户输入口令,采用随机数杂凑计算出密钥再进行加密
- Password:用户口令,例如"hello123"
- Salt:随机生成的byte[]
- key:generate(byte[] salt, String password)
- PBE算法通过用户口令和随机salt计算key然后加密
- key通过口令和随机salt计算得出,提高了安全性
- PBE算法内部使用的仍然是标准对称加密算法(例如AES)
- DH算法是一种密钥交换协议,通信双方通过不安全的信道协商密钥,然后进行对称加密传输
- DH算法没有解决中间人攻击
-
优点
- 对称加密需要协商密钥,而非对称加密可以安全地公开各自的公钥
- N个人之间的通信
- 使用非对称加密只需要N个密钥对, 每个人只管理自己的密钥对
- 使用对称加密需要N*(N-1)/2个密钥, 每个人需要管理N-1个密钥
-
缺点:
- 运算速度慢
- 只使用非对称加密不能防止中间人攻击
-
非对称加密就是加密和解密使用的不是相同的密钥
-
只有一个公钥/私钥对才能正常加密/解密
-
只使用非对称加密算法不能防止中间人攻击
- 数字签名就是用发送方的私钥对原始数据进行签名
- 只有用发送方公钥才能通过签名验证
- 防止伪造发送方
- 防止抵赖发送过信息
- 防止信息在传输过程中被修改
- 常用算法:MD5withRSA/SH1withRSA/SHA256withRSA
- 数字证书就是集合了多种密码学算法,用于实现数据加解密、身份认证、签名等多种功能的一种网络安全标准
- 数字整数采用链式签名管理,顶级CA整数已内置在操作系统中
- 常用算法:MD5/SHA1/SHA256/RSA/DSA
进程和线程的关系
- 一个进程可以包含一个或多个线程(至少一个线程)
- 线程是操作系统调度的最小人物单位
- 如何调度线程完全有操作系统决定
实现多任务的方法:
- 多进程模式(每个进程只有一个线程)
- 多线程模式(一个进程有多个线程)
- 多进程+多线程模式(复杂度最高)
多进程 VS 多线程
- 创建进程比创建线程开销大
- 进程间通信比线程见通信慢
- 多进程稳定性比多线程高
Java语言内置多线程支持:
- 一个Java程序实际上是一个JVM进程
- JVM用一个主线程来执行main()方法
- 在main()方法中又可以启动多个线程
多线程编程的特点:
- 多线程需要读写共享数据
- 多线程经常需要同步
- 多线程编程的复杂度高,调试更困难
Java多线程编程的特点:
- 多线程模型是Java编程最基本的并发模型
- 网络、数据库、Web等都依赖多线程模型
- 必须掌握Java多线程编程才能继续深入学习
java语言内置多线程支持:
- 一个java程序实际上是一个JVM进程
- JVM用一个主线程来执行main()方法
- 在main()方法中又可以启动多个线程
创建一个线程对象,并启动一个线程
Thread t = new Thread();
t.start();- Java用Thread对象表示一个线程,通过调用start()启动一个线程
- 一个线程对象只能调用一次start()
- 线程的执行代码是run()方法
- 线程调度由操作系统决定,程序本身无法决定
- Thread.sleep()可以把当前线程暂停一段时间
- 线程的状态
- New
- Runnable
- Blocked
- Waiting
- Timed Waiting
- Terminated
- 线程终止的原因:
- run()方法执行到return语句返回(线程正常终止)
- 因为未捕获异常导致的终止(线程意外终止)
- 对某个线程对Thread实例调用stop()方法强制终止(不推荐)
- 一个线程可以等待另一个线程直到运行结束(join)
- 通过对另一线程对象调用join()放回可以等待其执行结束
- 可以指定等待时间,超过等待时间线程任然没有结束就不睬等待
- 对已经运行结束的线程调用join()方法会立刻返回
- 调用interrupted()方法可以中断一个线程
- 通过检测isInterrupted()标志获取当前线程是否已经中断
- 如果线程处于等待状态,该线程会捕获InterruptedException
- isInterrupted()为true或这捕获来InterruptedException都应该立刻结束
- 通过标志位判断需要争取使用volatile关键字
- volatile关键字解决了共享变量在线程间的可见性问题
- Java程序入口就是由JVM启动main线程
- main线程又可以启动其他线程
- 当所有线程都运行结束时,JVM退出,进程结束
- 守护线程是为其他线程服务的线程
- 所有非守护线程都执行完毕后,虚拟机退出
- 守护线程不能持有资源(如打开文件等)
-
对共享变量进行写入时,必须保证是原子操作
-
原子操作是指不能被中断的一个或一系列操作
-
synchronized会导致性能下降的问题
-
多线程同时修改变量,会造成逻辑错误
- 需要使用synchronized同步
- 同步的本质就是给指定对象加锁
- 注意加锁对象必须是同一个实例
-
对JVM定义的单个原子操作不需要同步
- 添加synchronized块时:
- 锁住哪个对象?
- 数据封装,把同步逻辑封装到持有数据的实例中
- 线程安全的类:
- 不变类:String,Integer,LocalDat
- 没有成员变量的类,Math
- 正确使用了synchronized的类:StringBuffer
- 非线程安全的类:
- 不能在多线程**享实例并修改:ArrayList
- 可以在多想城中以只读方式共享
- 使用synchronized修饰方法可以把整个方法变为同步代码块
- synchronized方法加锁对象是this
- 通过合理的设计和数据封装可以让一个类变为线程安全
- 一个类没有特殊说明默认不是线程安全
- 多线程能否某个非线程安全的实例,需要具体问题具体分析
- 死锁形成的条件
- 两个线程各自持有不同的所
- 两个线程各自试图获取对方已持有的锁
- 双方无限等待下去:导致死锁
- 死锁发生后:
- 没有任何机制能够解除死锁
- 只能强制结束JVM进程
- 如何避免死锁
- 线程获取锁的顺序要完全一致
- wait/notify用于多线程协调运行
- 多线程协调运行:当条件不满足时,线程进入等待状态
- 在synchronized内部可以调用wait使线程进入等待状态
- 必须在已获得的锁对象上调用wait方法
- 在synchronized内部可以调用notify和notifyAll方法唤醒其他等待线程
- 必须在已获得的锁上调用notify和notifyAll方法
- ReentrantLock可以替代synchronized
- ReentrantLock获取锁更安全
- 必须使用try……finally保证正确获取和释放锁
- 使用ReadWriteLock可以解决:
- 只允许一个线程写入(其他线程既不能写入也不能读取)
- 没有写入时,多个线程允许同时读(提高性能)
- ReadWriteLock适用条件:
- 同一个实例,有大量线程读取,仅有少量线程修改
- 使用ReadWriteLock可以提高读取效率
- Condition.await / signal / signalAll 原理和wait / notify / notifyAll 一致
- await会释放当前锁, 进入等待状态
- signal会唤醒某个等待的线程
- signalAll会唤醒所有等待线程
- 唤醒线程从await返回后需要重新获得锁
- java.util.concurrent提供了线程安全的Blocking集合:
| Interface | Non-thread safe | Thread safe | | :---: | :---: | :--- : | | List | ArrayList | CopyOnWriteArrayList | | Map | HashMap | ConcurrentHashMap | | Set | HashSet, TreeSet | CopyOnWriteArraySet | | Queue | ArrayDeque, LinkedList | ArrayBlockingQueue, LinkedBlockingQueue | | Deque | ArrayDeque, LinkedList | LinkedBlockingDeque |
- java.util.Collections工具类还提供了旧的线程安全集合转换器
Map unsafeMap = new HashMap();
Map threadSafeMap = Collections.synchronizedMap(unsafeMap);- 使用java.util.concurrent提供的Blocking集合可以简化多线程编程
- 多线程同时访问Blocking集合是安全的
- 尽量使用JDK提供的concurrent集合,避免自己编写同步代码
- java.util.concurrent.atomic提供了一组原子类型操作:
- atomic类可以实现无锁的线程安全访问
- 使用java.util.concurrent.atomic可以简化多线程编程
- AtomicInteger / AtomicLong / AtomicIntegerArray等
- 原子操作实现了无锁的线程安全
- 适用于计数器,累加器等
- java语言内置多线程支持:
- 创建线程需要操作系统资源(线程资源,栈空间……)
- 频繁创建和销毁线程需要消耗大量时间
- 线程池
- 线程池维护若干个线程,处于等待状态,可以高效执行大量小任务
- 如果有新任务,就分配一个空闲线程执行
- 如果所有线程都处于忙碌状态,新任务就放入队列等待
- JDK提供了ExecutorService接口表示线程池,提供线程池功能:
- FixedThreadPool:线程数固定
- CachedThreadPool:线程数根据任务动态调整
- SingleThreadExecutor:仅单线程执行
- ScheduledThreadPool,提供了静态方法创建不同类型的ExecutorService:
- 一个任务可以定期反复执行
- Fixed Rate
- Fixed Delay
- java.util.Timer也是定时器
- 一个Timer对应一个Thread
- 必须在主线程结束时调用Timer.cancel()
- 必须调用shutdown()关闭ExecutorService
- 提交Callable任务,可以获得一个Future对象
- 可以用Future在将来某个时刻获取结果
- 优点:
- 异步任务结束时,会自动调用某个对象的方法
- 异步任务出错时,会自动调用某个对象的方法
- 主线程设置好回调后,不用关心异步任务的执行
- CompletableFuture对象可以指定异步处理流程
- thenAccept()处理正常结果
- exceptional()处理异常结果
- thenApplyAsync()用于串行化另一CompletableFuture
- anyOf / allOf用于并行化两个CompletableFuture
- Fork/Join是一种基于"分治"的算法:
- 分解任务 + 合并结果
- ForkJoinPool线程池可以把一个大任务分拆成小任务并行执行
- 任务类必须继承自RecursiveTask / RecursiveAction
- 使用Fork/Join模式可以进行并行计算提高效率
- 如何在一个线程内传递状态?
- ThreadLocal可以在一个线程中传递同一个对象
- ThreadLocal表示线程的"局部变量",它确保每个线程的ThreadLocal变量都是各自独立的
- ThreadLocal适合在一个线程的处理流程中保持上下文(避免了同一个参数在所有方法中传递)
- 使用ThreadLocal要用try……finally结构
计算机网络基本概念
- 互联网:网络的网络
- IP地址:计算机在网络中的标示
- 网关:负责链接多个网络
- 协议:TCP/IP协议
- TCP协议:面向连接,可靠传输
TCP编程模型
- 客户端使用Socket(InetAddress, port)打开Sockt
- 服务端使用ServerSocket监听端口
- 服务端用accept接收连接并返回Socket
- 双方通过Socket打开InputStream/OutputStream读写数据
- flush()用于强制输出缓冲区
- 服务器端使用无限循环
- 每次accept返回后,创建新的线程来处理客户端请求
- 每个客户端请求对应一个服务线程
- 使用线程池可以提高运行效率 TCP多线程编程模型
- 服务器端使用无限循环
- 每次accept返回后,创建行的县城来处理客户端请求
- 每个客户端请求对应一个服务线程
- 使用线程池可以提高运行效率
UDP编程模型
- 客户端使用DatagramSocket.connect()指定远程地址和端口
- 服务端用DatagramSocket(port)监听端口
- 双方通过receive/send读写数据
- 没有IO流接口
SMTP协议
- Simple Mail Transport Protocol
- 标准端口25
- 加密端口465 / 587
如何发送Email
- 使用JavaMail API
- 无需关心SMTP协议原理
- HTTP协议是一个给予TCP的请求/响应协议
- 广泛应用于浏览器、手机APP与服务器的数据交互
- Java提供了HttpURLConnection实现HTTP客户端
-目的是把一个接口暴露给远程
- RMI远程调用是针对Java怨言的一种远程调用
- 远程接口必须继承自Remote
- 远程方法必须抛出RemoteException
- 客户端调用RMI方法和调用本地方法类似
- RMI方法调用被自动通过网络传输到服务端
- 服务端通过自动生成的stub类接收远程调用请求。
- XML是可扩展标记语言的缩写
- 纯文本数据
- 用于表示复杂的结构化数据
- 用于数据的存储和传输
- 数据庞大,格式复杂
- Java DOM API将XML解析为DOM
- 可在内存中完整表示XML数据结构
- 缺点是解析速度慢,内存占用大
- 一种流式解析XML的API
- 通过事件触发,速度快
- 调用方通过回调方法获得数据
- 开源的Jackson
- 使用Jackson可以快速在XML和JavaBean之间互相转换
- 可以使用Annotation定制序列化和反序列化
- JSON只允许UTF-8编码
- 必须使用双引号
- 特殊字符用\转义
- 适合表示层次结构
- 结构简单,仅支持集中类型
- {...}键值对
- [...]数组
- String字符串
- Number数值
- Boolean布尔值
- null空值
- 常用第三方库
- Jackson
- gson
- fastjson
- ...
- Json是轻量级的数据表示方式
- 格式简单
- 解析速度快
- 适合Web应用
- Jackson提供了读写JSON的API
- 实现JSON和JavaBean的互相转换
- 可使用Annotation定制序列化和反序列化
- 关系数据库是目前使用最广泛的数据库
- 建立在关系模型上
- 基本结构是表
- 主键用于唯一标识记录
- 外键用于引用其他表的主键数据
- 通过外键关联实现一对多/一对一/多对多关系
- SQL是结构化查询语言
- 针对关系型数据库设计
- 各种数据库基本一致
- 允许用户通过SQL查询数据而不必关心数据库底层存储结构
- 可以和各种编程语言继承实现访问数据库的功能
- 关键字不区分大小写
- INSERT语句可以向指定表插入一条记录
INSERT INTO 表名 (字段1, 字段2, ...) VALUES (数据1, 数据2, 数据3, ...)- 可以指定查询的列
- 可以通过WHERE条件筛选符合条件的行
- 可以使用聚合查询
- 可以多表联合查询
- 查询结果仍然是一个关系表
- 可以设置某些列的值
- 可以通过WHERE条件筛选符合条件的行
- 执行结果为符合更新条件的行数
- 可以删除指定的行
- 可以通过WHERE条件筛选符合条件的行
- 执行结果为删除的行数
-
JDBC:Java DataBase Connectivity
-
Java程序访问数据库的标准接口
-
Java App -> JDBC Interface -> JDBC Driver -> Database
-
Java App -> JDBC Interface -> MySQL Driver -> MySQL Server
-
使用JDBC的好处
- 各个数据库厂商使用相同的接口,Java代码不需要针对不同的数据库开发
- Java程序编译期仅以来java.sql.*,不依赖具体数据库的jar包
- 可以随时替换底层数据库,访问数据库的Java代码不变
-
JDK提供JDBC接口,数据库厂商提供JDBC驱动(JDBC实现)
-
Connection代表一个JDBC连接
- 始终建议使用PreparedStatement:
- 查询结果是ResultSet
- 使用PreparedStatement的executeUpdate()进行更新
- 更新操作包括UPDATE、INSERT和DELETE语句
- 更新结果是int
- 数据库事物:
- 若干个SQL语句构成的一个操作序列
- 要么全部执行成功
- 要么全部不执行
- 数据库事物具有ACID特性
- Atomicity:原子性
- Consistency:一致性
- Isolation:隔离性
- Durability:持久性
- 事物隔离级别
- 脏读:Dirty Read
- 非重复读:Non repeatable Read
- 幻读:Phantom Read
- JDBC提供了对事物的支持
- JDBC连接池接口:javax.sql.DataSource
- JDBC连接池实现:
- HikariCP
- C3P0
- BoneCP
- Druid
- 可以复用Connection,避免反复创建新连接,提高运行效率
- 可以配置连接池的详细参数
-
函数式编程(Functional Programming):
- 把函数作为基本运算单元
- 函数可以作为变量
- 函数可以接收函数
- 函数可以返回函数
-
Lambda表达式:
- 简化语法
- JDK >= 1.8
- 类型自动推断:
- Comparator接口
- 传入String,String
- 返回int
-
Java单方法接口
- Comparator
- Runnable
- Callable
-
只定义单个抽象方法的接口可以被标注为@Functinalinterface
-
但抽象方法接口被称为函数式接口
- 方法引用:如果某个方法签名和接口恰好一致:可以直接传入方法引用(String::compareTo)
- Functional Interface 可以传入:
- 接口的实现类(比较繁琐)
- Lambda表达式
- 符合方法签名的静态方法
- 符合方法签名的实例方法(实例类型被看做第一个参数类型)
- 符合方法签名的构造方法(实例类型被看做返回类型)
- java8引入Stream,在java.util.stream
- 不同于java.io的InputStream / OutputStream:
| java.io | java.util.stream | |
|---|---|---|
| 存储 | 顺序读写的byte / char | 顺序输出的任意Java对象 |
| 用途 | 序列化至文件 / 网络 | 内存计算 / 业务逻辑 |
- 不同于java.util.List:
| java.util.List | java.util.stream | |
|---|---|---|
| 元素 | 已分配并存储在内存 | 未分配,实时计算 |
| 用途 | 操作一组已存在的Java对象 | 惰性计算 |
- stream特点:
- 可以“存储”有限个或无限个元素
- 可以转换为另一个Stream
- 计算通常发生在最后结果的获取(惰性计算)
- 创建Stream:
Stream<Integer> s = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> s = Arrays.stream(theArray);
Stream<Integer> s = aList.stream();
Stream<T> s = Stream.generate(Supplier<T> s);
try(Stream<String> lines = Files.lines(Paths.get("/path/to/access.log"))){
...
}
Files的lines也可以创建一个Stream
- 基本类型的Stream有IntStream / LongStream / DoubleStream
- Stream.map是Stream的转换方法,把一个Stream转化成另一个Stream
- map()方法将一个Stream的每个元素映射成另一个元素并生成一个新的Stream
- 可以将一种元素类型转换成另一种元素类型
- filter()方法用于将一个Stream的每个元素进行测试,通过测试的元素被过滤后生成一个新的Stream
- 用于排除不满足条件的元素
- Stream.reduce()是一个Stream的聚合方法,把一个Stream的所有元素聚合成一个结果
- 将一个Stream的每个元素依次作用于BFunction,并将结果合并
- reduce是聚合方法,聚合方法会立刻对Stream进行运算
- 排序:
Stream<T> sorted() //按元素默认大小进行排序(必须实现Comparable接口)
Stream<T> sorted(Comparable<? super T> cp) //按指定Comparable比较的结果排序
- 去除重复元素
Stream<T> distinct() //返回去除重复元素的新Stream
// [1, 2, 3, 4, 5, 4, 3] -> [1, 2, 3, 4, 5]
- 截取
Stream<T> limit(long) //截取当前Stream的最多n个元素
Stream<T> skip(long) //跳过当前Stream的前N个元素
- 将两个Stream合并成一个
Stream<T> s = Stream.concat(
Stream.of(1, 2, 3)
Stream.of(4, 5, 6)
);
// 1, 2, 3, 4, 5, 6
- flatMap:把元素映射为Stream然后合并成一个新的Stream:
Stream<List<Integer>> s = Stream.of)
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9));
// 转换为Stream<Integer>
Stream<Integer> i = s.flatMap(list -> list.stream())
| 1 2 3 | 4 5 6 | 7 8 9 |:---:| :--- : | :---: | | flatMap | | | 1 2 3 4 5 6 7 8 9 |
- 把一个Stream转换为可以并行处理的Stream:
Stream<String> s = ...
String[] result = s.parallel() // 贬称一个可以并行处理的Stream
.sorted() // 可以进行并行排序
.toArray(String[]::new);
- 聚合方法
Optional<T> reduce(BinaryOperator<T> bo)
long count() //元素个数
T max(Comparator<? super T> cp) //找最大元素
T min(Comparator<? super T> cp) //找最小元素
// 针对IntStream / LongStream / DoubleStream
sum() //求和
average() //求平均数
- 测试Stream的元素是否满足一定的条件
boolean allMatch(Predicate<? super T>) //所有元素均满足条件?
boolean anyMatch(Predicate<? super T>) //至少有一个元素满足测试条件?
- 循环处理Stream的每个元素
void forEach(Consumer<? super T> action)
//示例
Stream<String> s = ...
s.forEach(str -> {
System.out.println("Hello, " + str);
});
- 把Stream转化成其他类型
Object[] toArray() //转换为Object数组
A[] toArray(IntFunction<A[]>) //转换为A[]数组
<R, A> R collect(Collector<? super T, A, R> collector) //转换为List/Set等集合类型
//示例
Stream<String> s = ...
String[] arr = s.toArray(String[]::new) //转换为String数组
List<String> list = s.collect(Collectors.toList) //转换为List