Self-distillation Regularized Connectionist Temporal Classification Loss for Text Recognition: A Simple Yet Effective Approach
Paper: https://arxiv.org/abs/2308.08806
This an implementation based on PyTorch only. In the paper, we implemented dctc using cuda based on PaddleOCR. As you can see below, DCTC can achieve better performance and converge much faster than ctc.
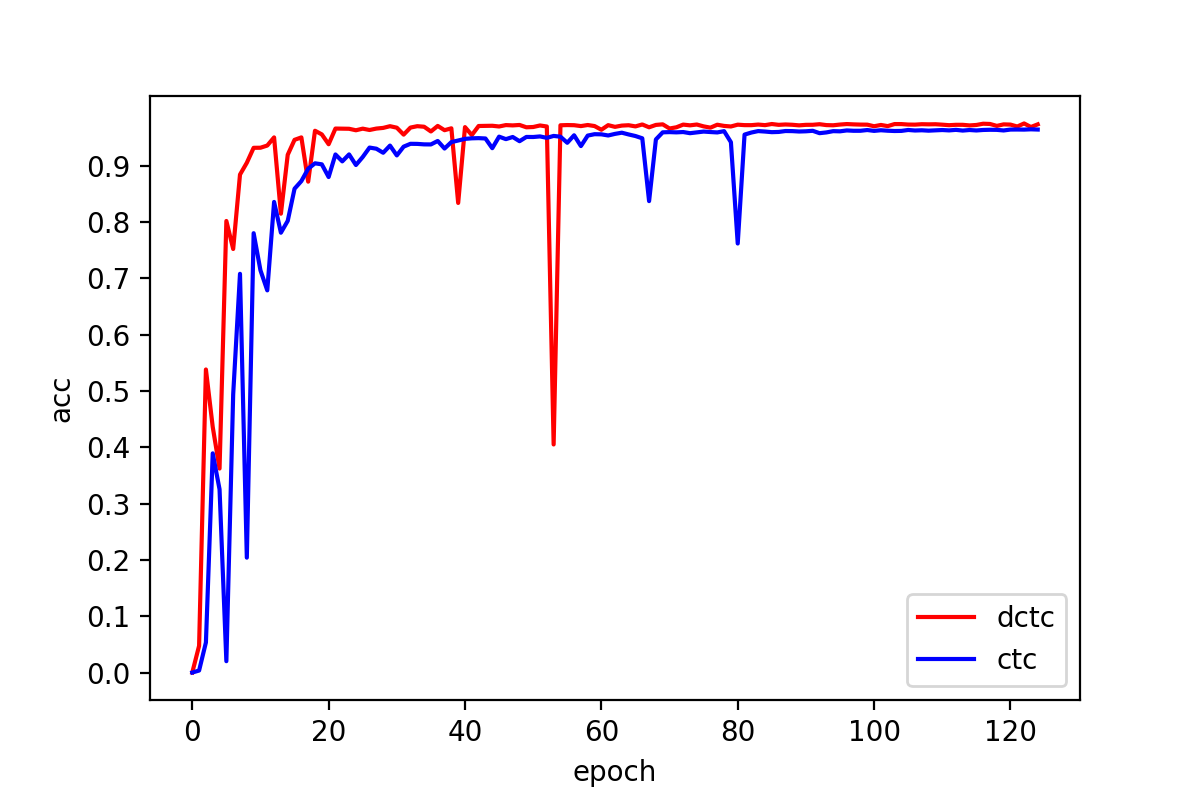
In this repo, we only train the CRNN on the Document split of Chinese Benchmark Dataset and use its codebase. We use one Nvidia A6000 with batch size 512 and 125 epochs. All the logs and ckpts are here.
| Model | Document |
|---|---|
| CRNN (CTC) | 96.474% |
| CRNN (DCTC) | 97.516% |
import dctc
criterion = dctc.DCTC(use_il=False, alpha=0.01)
...
...
targets_dict = {
'targets': text,
'target_lengths': length
}
cost = criterion(logits=preds,
targets_dict=targets_dict)- perpare Chinese Benchmark Dataset
cd benchmarking-chinese-text-recognition\model\CRNN- modify dataset path in the
train.sh
If you find it uesful, please cite our paper.
@misc{zhang2023selfdistillation,
title={Self-distillation Regularized Connectionist Temporal Classification Loss for Text Recognition: A Simple Yet Effective Approach},
author={Ziyin Zhang and Ning Lu and Minghui Liao and Yongshuai Huang and Cheng Li and Min Wang and Wei Peng},
year={2023},
eprint={2308.08806},
archivePrefix={arXiv},
primaryClass={cs.CV}
}