这是用于 F5-TTS 项目的api
F5-TTS是由上海交通大学开源的一款基于流匹配的全非自回归文本到语音转换系统(Text-to-Speech,TTS)。它以其高效、自然和多语言支持的特点脱颖而出
- 提供api接口文件
api.py,可对接于视频翻译项目 pyvideotrans - 提供兼容 OpenAI TTS的接口
- 提供windows下整合包
整合包仅可用于 Windows10/11, 下载后解压即用
- 启动Api服务: 双击
run-api.bat,接口地址是http://127.0.0.1:5010/api
整合包默认使用 cuda11.8版本,若有英伟达显卡,并且已安装配置好CUDA/cuDNN环境,将自动使用GPU加速
- 将 api.py 和 configs 文件夹复制到三方整合包内根目录内
- 查看三方整合包集成的 python.exe 路径,例如在 py311 文件夹内,那么在根目录下文件夹地址栏内输入
cmd回车,接着执行命令.\py311\python api.py,如果提示module flask not found,则先执行.\py311\python -m pip install waitress flask
- 将 api.py 和 configs 文件夹复制到项目文件夹内
- 安装模块
pip install flask waitress - 执行
python api.py
- 模型需要从
huggingface.co网站在线下载,该站点无法在国内访问,请提前开启系统代理或全局代理,否则模型会下载失败
- 启动api服务
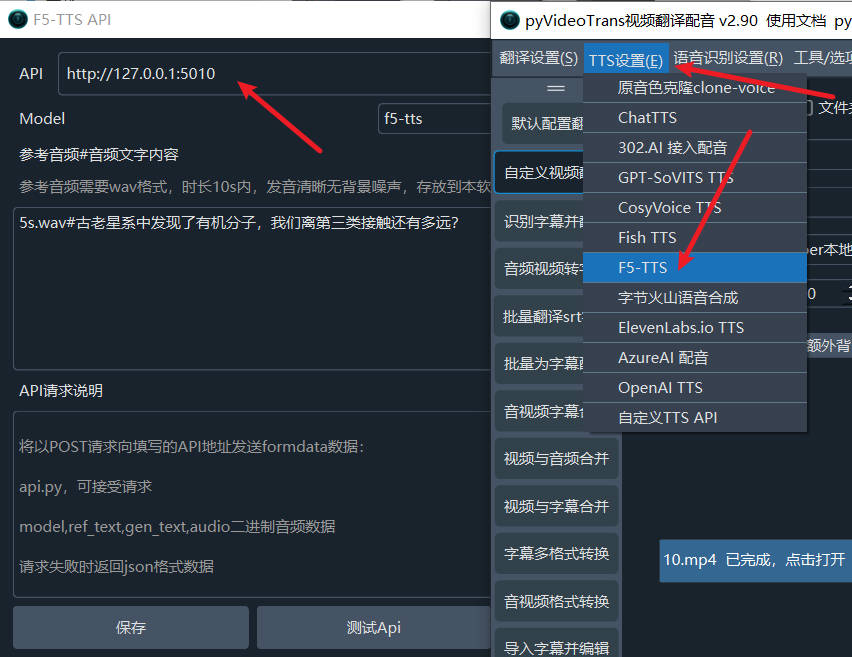
- 打开视频翻译软件,找到菜单-TTS设置-F5-TTS,填写api地址,如果未修改过地址,填写
http://127.0.0.1:5010 - 填写参考音频和音频内文本
import requests
res=requests.post('http://127.0.0.1:5010/api',data={
"ref_text": '这里填写 1.wav 中对应的文字内容',
"gen_text": '''这里填写要生成的文本。''',
"model": 'f5-tts'
},files={"audio":open('./1.wav','rb')})
if res.status_code!=200:
print(res.text)
exit()
with open("ceshi.wav",'wb') as f:
f.write(res.content)
voice 参数必须用3个#号分割参考音频和参考音频对应的文本,例如
1.wav###你说四大皆空,却为何紧闭双眼,若你睁开眼睛看看我,我不相信你,两眼空空。
表示参考音频是 1.wav 和 api.py位于同一位置,1.wav里的文本内容是 "你说四大皆空,却为何紧闭双眼,若你睁开眼睛看看我,我不相信你,两眼空空。"
返回数据固定为wav音频数据
import requests
import json
import os
import base64
import struct
from openai import OpenAI
client = OpenAI(api_key='12314', base_url='http://127.0.0.1:5010/v1')
with client.audio.speech.with_streaming_response.create(
model='f5-tts',
voice='1.wav###你说四大皆空,却为何紧闭双眼,若你睁开眼睛看看我,我不相信你,两眼空空。',
input='你好啊,亲爱的朋友们',
speed=1.0
) as response:
with open('./test.wav', 'wb') as f:
for chunk in response.iter_bytes():
f.write(chunk)