- (Unofficial) PyTorch implementation of Training Vision Transformers for Image Retrieval(El-Nouby, Alaaeldin, et al. 2021).
- I have not yet achieved exactly the same results as reported in the paper(Differential entropy regularization does not have much effect on In-shop and SOP datasets).
# Python 3.7
pip install -r requirements.txt
# CUB-200-2011
python main.py \
--model deit_small_distilled_patch16_224 \
--max-iter 2000 \
--dataset cub200 \
--data-path /data/CUB_200_2011 \
--rank 1 2 4 8 \
--lambda-reg 0.7
# Stanford Online Products
python main.py \
--model deit_small_distilled_patch16_224 \
--max-iter 35000 \
--dataset sop \
--m 2 \
--data-path /data/Stanford_Online_Products \
--rank 1 10 100 1000 \
--lambda-reg 0.7
# In-shop
python main.py \
--model deit_small_distilled_patch16_224 \
--max-iter 35000 \
--dataset inshop \
--data-path /data/In-shop \
--m 2 \
--rank 1 10 20 30 \
--memory-ratio 0.2 \
--device cuda:2 \
--encoder-momentum 0.999 \
--lambda-reg 0.7
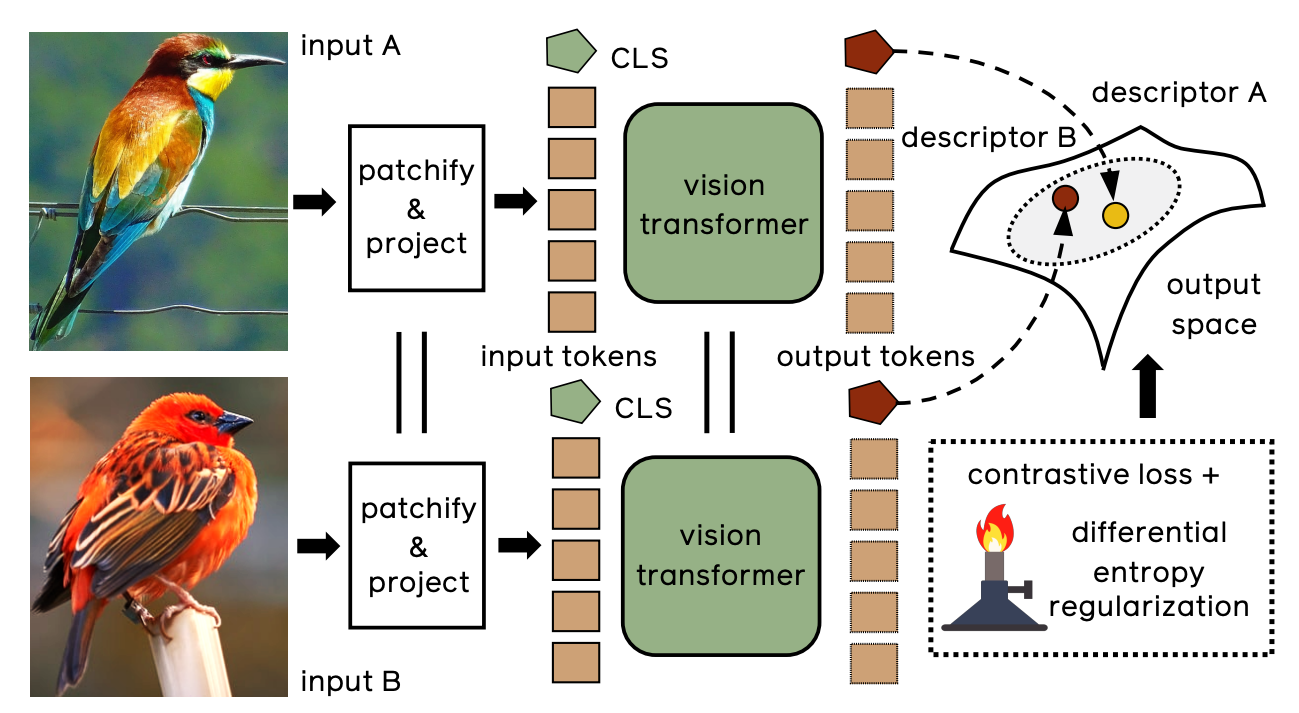
- IRTO – off-the-shelf extraction of features from a ViT backbone, pre-trained on ImageNet;
- IRTL – fine-tuning a transformer with metric learning, in particular with a contrastive loss;
- IRTR – additionally regularizing the output feature space to encourage uniformity.
- †: Models pre-trained with distillation with a convnet trained on ImageNet1k
| Method |
Backbone |
SOP |
CUB-200 |
In-Shop |
| 1 |
10 |
100 |
1000 |
1 |
2 |
4 |
8 |
1 |
10 |
20 |
30 |
| IRTO |
DeiT-S |
53.12 |
68.96 |
81.60 |
94.09 |
58.68 |
71.30 |
80.96 |
88.18 |
31.28 |
57.03 |
64.20 |
68.28 |
| IRTL |
DeiT-S |
83.56 |
93.29 |
97.23 |
99.03 |
73.68 |
82.58 |
88.77 |
92.71 |
93.09 |
98.28 |
98.74 |
99.02 |
| IRTR |
DeiT-S |
82.67 |
92.73 |
96.69 |
98.80 |
73.73 |
82.91 |
89.30 |
93.35 |
90.47 |
97.97 |
98.61 |
98.92 |
| IRTR |
DeiT-S† |
82.70 |
92.85 |
96.92 |
98.86 |
76.55 |
85.26 |
90.92 |
94.65 |
90.66 |
98.16 |
98.68 |
98.99 |
- El-Nouby, Alaaeldin, et al. "Training vision transformers for image retrieval." arXiv preprint arXiv:2102.05644 (2021).
