Um projeto de demonstração usando Spark Streaming para analisar hashtags populares do Twitter. Os dados vêm da fonte da Twitter Streaming API e são fornecidos ao Kafka. O consumidor com.twitter.producer.service recebe dados do Kafka e, em seguida, os processa em um fluxo usando o Spark Streaming.
-
shangrila-producer - Realiza a consulta a api do Twitter e funciona como produtor de topico no Kafka
-
shangrila-producer - Tem a responsabilidade de implementar as regras de negocio atraves do spark streaming e salvar no Banco de Dados (Cassandra). Também tem a responsabilidade de ser o consumidor dos topicos do Kafka.
O desenho e implementação de uma arquitetura distribuída, que realize a integração com o Twitter que seja tolerante a falhas e escalável horizontalmente, que exponha através de uma aplicação web as informações sumarizadas e descritas no Case de integração.

- Apache Maven 3.x
- JVM 8
- Docker machine
- Registratar um aplicativo no Twtter.
- Em seguida, processa em um fluxo usando Sparj Streaming: Como criar uma aplicação no Twitter..
Na próxima etapa irei demonstrar como configurar o ambiente para que executar nossa aplicação.
Neste quie rápido mostrarei como configurar sua máquina para executar nosso aplicativo.
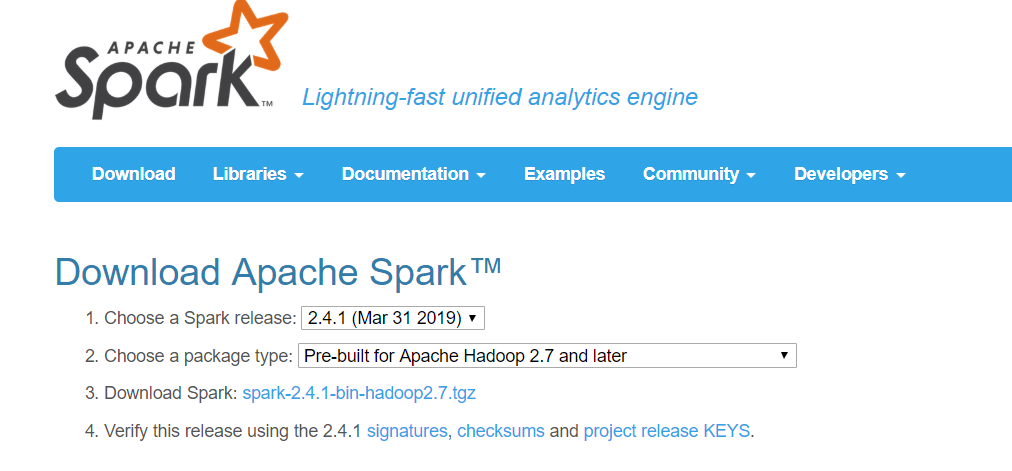
- Faça o download do Spark em https://spark.apache.org/downloads.html

-
Descompacte o arquivo spark-2.4.1-bin-hadoop2.7.tgz em um diretório.
-
Agora defina variáveis de ambiente SPARK_HOME = C:\Installations \spark-2.4.1-bin-hadoop2.7


- Instalando o binário winutils
-
Faça o download do winutils.exe do Hadoop 2.7 e coloque-o em um diretório C: \ Installations \ Hadoop \ bin
-
Agora defina variáveis de ambiente HADOOP_HOME = C: \ Installations \ Hadoop.

Agora inicie o shell do Windows; você pode receber alguns avisos, que você pode ignorar por enquanto.

-
Mude a configuração do Twtter no arquivo
\producer\src\main\resources\application.ymlcolocando suas credencias do Twtter, client Id e Secret Id. -
Execute a imagem kafka usando o docker-compose (lembre-se de que a imagem kafka também precisa extrair o zookeper):
~> docker-compose -f shangrila-producer/src/main/docker/kafka-docker-compose.yml up -d
Execute a imagem do Cassandra usando o docker-compose.
~> docker-compose -f shangrila-consumer\src\main\docker\cassandra.yml up -d
Verifique se o Cassandra, ZooKeeper e o Kafka estão em execução (no prompt de comando)
~> docker ps
- Execute o poducer e o aplicativo do consumidor com:
~> mvn spring-boot:run