zi2zi (DOUBLE forked):Style-transformation from hand-written characters to Chinese Calligraphy, Using CNN + CycleGAN
- 基于上一位coder的模型进行改进,将原文提及的cycleGAN引入模型中GAN的部分
- 并对各loss做出删改
初始idea来源于这个学期我进行的一门山水课的线上学习。在线上交作业的时候,老师往往让我们把作品拍照、加上毛笔字题款/电子签名后po在课程群里,但其实很多课程同学此前并没有参与过书法学习,无论用毛笔题款还是电子签名,加在作品上总有很强的违和感,一下破坏了一幅很好的作品原本的意境。这让我想起有不少人学习书法,只是为了练好自己的署名——但从书法学习的角度来说,练习是一个整体渐进的过程,不太可能针对几个字专门练习后取得较好的结果,想要练习必得投入较多的时间精力。
在社会上,人们大多忙碌着各式各样的本职工作,对于这种在有限场合下使用书法的需求,投入较多精力与时间去练习显然不太划算;可需求始终存在。如果能够利用风格迁移的方法,学习到历代大家的书法作品(如”颜筋柳骨“、褚遂良、文征明等等),将其应用在用户平平无奇(至少不能太丑,满足笔画整洁)的手写字体上,那么字体既保留了书写者自己的风格,同时在点捺顿挫上又有着大家书法作品的风范。
做到输入一张手写作品(几个字/一段文字)的照片或扫描图片,处理后输出基于照片生成的书法作品图片。
-
Image-to-Image Translation with Conditional Adversarial Networks(论文地址:https://arxiv.org/pdf/1611.07004.pdf)
该项目是加州大学伯克利视觉组的研究,实现了从草图生成真实图片,其模型主要的创新点是在Unet的基础上引入了conditional GAN来做从图片到图片的生成,并引入L1 loss使源图像与目标图像的域尽可能接近。
-
zi2zi (项目主页:https://kaonashi-tyc.github.io/2017/04/06/zi2zi.html)
如本项目作者自述,其模型主要来源于pix2pix,当然作者还基于AC-GAN、DTN网络对Discriminator鉴别器做了一些改进。该项目的主要工作是对于系统内编码字体的风格迁移——字体设计师在设计字体的时候往往只对部分字/字母进行设计,对于其他字,可以通过风格迁移的方法补充设计,以完成一种新字体的设计。
与我的目标不同处是:该项目的输入与输出都是系统内编码字体,而非手写,即,对于生成的字体没有标准答案。
-
Generating Handwritten Chinese Characters using CycleGAN (论文地址:https://arxiv.org/pdf/1801.08624.pdf)
该项目主要研究了在训练数据不配对的情况下,**手写字符的生成,学习将现有的印刷字体映射到个性化手写风格。作者特别指出:"我们的方法不仅适用于常用的汉字,而且适用于具有美学价值的书法作品。“项目中,内容准确性和样式差异作为评估指标,以评估生成的手写字符的质量。
-
数据:考虑抓取网站如”书法字典“上的图片,转化为灰度图;或者采用ttf格式的字体,转化为图片。
-
模型:模型由编码器、解码器和判别器组成,网络大的框架会沿用“zi2zi”的结构(如下图),Encoder与decoder都使用CNN。
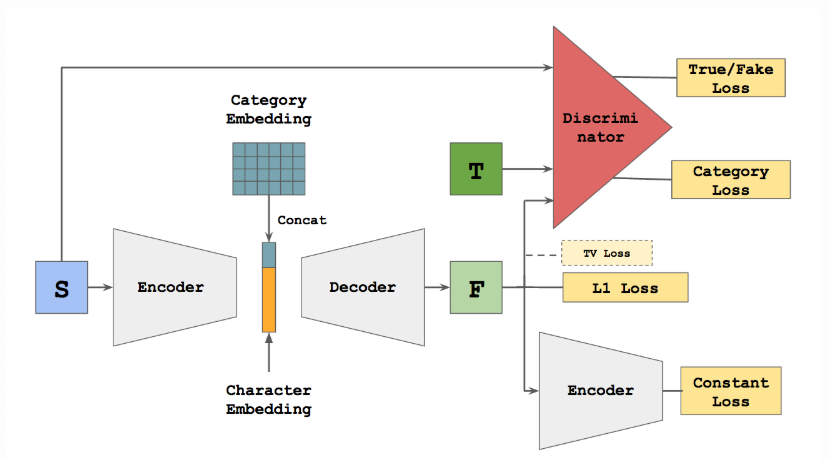
所不同的是,在GAN部分引入Cycle GAN。同样地,也会针对训练表现和具体问题,在loss等设计上进行改动,希望能在学习的同时借鉴其他网络和经典idea,就如同zi2zi的作者基于image2image所做的工作那样。(希望在有限的时间里,以我的学习速度和阅读量可以支撑这次的尝试:)
-
评价指标:以内容准确性和样式差异作为评价指标。

以下是原作者们的说明。
- We all know GAN can generate printed fonts very well based on original repo, so we are curious how well can GAN learn on handwritten fonts. And whether it can learn our handwriting styles via finetuning.
- Use Grayscale images which largely improves the training speed
- Provide training data and preprocess script to prepare them
- Generate handwritten Chinese characters based on your own handwritings!!! An OCR toolkit based on Tesseract and jTessBoxEditor, which allows you to take a picture of your handwritings and use it as finetuning data
- Script to finetune handwritings and learn the style within few shots
Below are the screenshot of GAN-generated samples at Step 9000. The left side is the ground truth, and the right side is the GAN-generated samples for a given font. You can tell the conditional GAN did learn some stylistic features of a given font.


After model starts training, you can see samples and logs under experiments/ folder.
Here is a screenshot of the tensorboard, and according to validation error, Step 9000 is the recommended stop point for given training data. (You can add more hand-written fonts as training data, so as to train the model longer, but one recommendation is: don't overfit, otherwise the finetuning won't work).

- Python 3
- Tensorflow 1.8
You can follow the steps below or simply run run.sh
##########################
## PreProcess
##########################
# Sample draw the fonts and save to paired_images, about 10-20 mins
PYTHONPATH=. python font2img.py
##########################
## Train and Infer
##########################
# Train the model
PYTHONPATH=. python train.py --experiment_dir=experiments \
--experiment_id=0 \
--batch_size=64 \
--lr=0.001 \
--epoch=40 \
--sample_steps=50 \
--schedule=20 \
--L1_penalty=100 \
--Lconst_penalty=15
# Infer
PYTHONPATH=. python infer.py --model_dir=experiments/checkpoint/experiment_0_batch_32 \
--batch_size=32 \
--source_obj=experiments/data/val.obj \
--embedding_ids=0 \
--save_dir=save_dir/
To see how to prepare the your handwrittings, please take a look at handwriting_preparation/README.md, which introduces how to use tesseract and jTessBoxEditor for details.

##########################
## Finetune
##########################
# Generate paired images for finetune
PYTHONPATH=. python font2img_finetune.py
# Train/Finetune the model
PYTHONPATH=. python train.py --experiment_dir=experiments_finetune \
--experiment_id=0 \
--batch_size=16 \
--lr=0.001 \
--epoch=10 \
--sample_steps=1 \
--schedule=20 \
--L1_penalty=100 \
--Lconst_penalty=15 \
--freeze_encoder_decoder=1 \
--optimizer=sgd \
--fine_tune=67 \
--flip_labels=1
PYTHONPATH=. python infer.py --model_dir=experiments_finetune/checkpoint/experiment_0 \
--batch_size=32 \
--source_obj=experiments_finetune/data/val.obj \
--embedding_id=67 \
--save_dir=save_dir/
PYTHONPATH=. python infer_by_text.py --model_dir=experiments_finetune/checkpoint/experiment_0 \
--batch_size=32 \
--embedding_id=67 \
--save_dir=save_dir/
My feeling is CycleGan will perform better, as it doesn't require pairwise data, and supposedly can learn more abstractive structural features of fonts. You can take a look at Generating Handwritten Chinese Characters using CycleGAN and its implementation at https://github.com/changebo/HCCG-CycleGAN
#################################################################### ######### Below are the README from original repo author ######## ###################################################################
Learning eastern asian language typefaces with GAN. zi2zi(字到字, meaning from character to character) is an application and extension of the recent popular pix2pix model to Chinese characters.
Details could be found in this blog post.

The network structure is based off pix2pix with the addition of category embedding and two other losses, category loss and constant loss, from AC-GAN and DTN respectively.

After sufficient training, d_loss will drop to near zero, and the model's performance plateaued. Label Shuffling mitigate this problem by presenting new challenges to the model.
Specifically, within a given minibatch, for the same set of source characters, we generate two sets of target characters: one with correct embedding labels, the other with the shuffled labels. The shuffled set likely will not have the corresponding target images to compute L1_Loss, but can be used as a good source for all other losses, forcing the model to further generalize beyond the limited set of provided examples. Empirically, label shuffling improves the model's generalization on unseen data with better details, and decrease the required number of characters.
You can enable label shuffling by setting flip_labels=1 option in train.py script. It is recommended that you enable this after d_loss flatlines around zero, for further tuning.









Download tons of fonts as you please
- Python 2.7
- CUDA
- cudnn
- Tensorflow >= 1.0.1
- Pillow(PIL)
- numpy >= 1.12.1
- scipy >= 0.18.1
- imageio
To avoid IO bottleneck, preprocessing is necessary to pickle your data into binary and persist in memory during training.
First run the below command to get the font images:
python font2img.py --src_font=src.ttf
--dst_font=tgt.otf
--charset=CN
--sample_count=1000
--sample_dir=dir
--label=0
--filter=1
--shuffle=1Four default charsets are offered: CN, CN_T(traditional), JP, KR. You can also point it to a one line file, it will generate the images of the characters in it. Note, filter option is highly recommended, it will pre sample some characters and filter all the images that have the same hash, usually indicating that character is missing. label indicating index in the category embeddings that this font associated with, default to 0.
After obtaining all images, run package.py to pickle the images and their corresponding labels into binary format:
python package.py --dir=image_directories
--save_dir=binary_save_directory
--split_ratio=[0,1]After running this, you will find two objects train.obj and val.obj under the save_dir for training and validation, respectively.
experiment/
└── data
├── train.obj
└── val.objCreate a experiment directory under the root of the project, and a data directory within it to place the two binaries. Assuming a directory layout enforce bettet data isolation, especially if you have multiple experiments running.
To start training run the following command
python train.py --experiment_dir=experiment
--experiment_id=0
--batch_size=16
--lr=0.001
--epoch=40
--sample_steps=50
--schedule=20
--L1_penalty=100
--Lconst_penalty=15schedule here means in between how many epochs, the learning rate will decay by half. The train command will create sample,logs,checkpoint directory under experiment_dir if non-existed, where you can check and manage the progress of your training.
After training is done, run the below command to infer test data:
python infer.py --model_dir=checkpoint_dir/
--batch_size=16
--source_obj=binary_obj_path
--embedding_ids=label[s] of the font, separate by comma
--save_dir=save_dir/Also you can do interpolation with this command:
python infer.py --model_dir= checkpoint_dir/
--batch_size=10
--source_obj=obj_path
--embedding_ids=label[s] of the font, separate by comma
--save_dir=frames/
--output_gif=gif_path
--interpolate=1
--steps=10
--uroboros=1It will run through all the pairs of fonts specified in embedding_ids and interpolate the number of steps as specified.
Pretained model can be downloaded here which is trained with 27 fonts, only generator is saved to reduce the model size. You can use encoder in the this pretrained model to accelerate the training process.
Code derived and rehashed from:
- pix2pix-tensorflow by yenchenlin
- Domain Transfer Network by yunjey
- ac-gan by buriburisuri
- dc-gan by carpedm20
- origianl pix2pix torch code by phillipi
Apache 2.0