Megatron is a Python module for building data pipelines that encapsulate the entire machine learning process, from raw data to predictions.
The advantages of using Megatron:
- A wide array of data transformations can be applied, including:
- Built-in preprocessing transformations such as one-hot encoding, whitening, time-series windowing, etc.
- Any custom transformations you want, provided they take in Numpy arrays and output Numpy arrays.
- Sklearn preprocessors, unsupervised models (e.g. PCA), and supervised models. Basically, anything from sklearn.
- Keras models.
- To any Keras users, the API will be familiar: Megatron's API is heavily inspired by the Keras Functional API, where each data transformation (whether a simple one-hot encoding or an entire neural network) is applied as a Layer.
- Since all datasets should be versioned, Megatron allows you to name and version your pipelines and associated output data.
- Pipeline outputs can be cached and looked up easily for each pipeline and version.
- The pipeline can be elegantly visualized as a graph, showing connections between layers similar to a Keras visualization.
- Data and input layer shapes can be loaded from structured data sources including:
- Pandas dataframes.
- CSVs.
- SQL database connections and queries.
- Pipelines can either take in and produce full datasets, or take in and produce batch generators, for maximum flexibility.
- Pipelines support eager execution for immediate examination of data and simpler debugging.
To install megatron, just grab it from pip:
pip install megatron
There's also a Docker image available with all dependencies and optional dependencies installed:
docker pull ntaylor22/megatron
- Scikit-Learn
- If you'd like to use Sklearn transformations as Layers.
- Keras
- If you'd like to use Keras models as Layers.
- Pydot
- If you'd like to be able to visualize pipelines.
- Note: requires GraphViz to run.
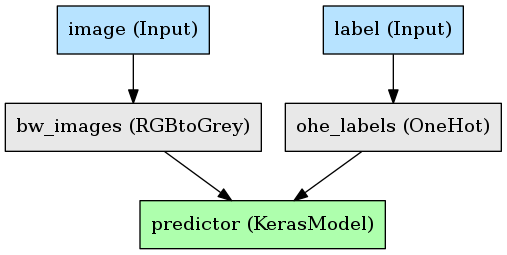
See the project documentation For an in-depth tutorial where you can build this simple example:
Also check out the example notebooks, which you can conveniently launch from Binder by clicking on the badge below.
If you have a function that takes in Numpy arrays and produces Numpy arrays, you have two possible paths to adding it as a Layer in a Pipeline:
- The function has no parameters to learn, and will always return the same output for a given input. We refer to this as a "stateless" Layer.
- The function learns parameters (i.e. needs to be "fit"). We refer to this as a "stateful" Layer.
To create a custom stateful layer, you will inherit the StatefulLayer base class, and write two methods: fit (or partial_fit), and transform. Here's an example with a Whitening Layer:
class Whiten(megatron.layers.StatefulLayer):
def fit(self, X):
self.metadata['mean'] = X.mean(axis=0)
self.metadata['std'] = X.std(axis=0)
def transform(self, X):
return (X - self.metadata['mean']) / self.metadata['std']
There's a couple things to know here:
- When you calculate parameters during the fit, you store them in the provided dictionary self.metadata. You then retrieve them from this dictionary in your transform method.
- If your Layer is one that can be fit iteratively, you can override partial_fit rather than fit. If your transformation cannot be fit iteratively, you override fit; note that Layers without a partial_fit cannot be used with data generators, and will throw an error in that situation.
- For an example of how to write a partial_fit method, see megatron.layers.shaping.OneHotRange.).
To create a custom stateless Layer, you can simply define your function and wrap it in megatron.layers.Lambda. For example:
def dot_product(X, Y):
return np.dot(X, Y)
dot_xy = megatron.layers.Lambda(dot_product)([X_node, Y_node], 'dot_product_result')
That's it, a simple wrapper.
Because the layers are data transformers!
That's... that's about it.
MIT.