This repository contains the demo files and applications for my conference talk Build your own social media analytics with Apache Kafka.
The slides form the talk can be found on Google Slides.
-
Install the Strimzi operator. The demo is currently using Strimzi 0.29.0, but it should work also with newer versions. If needed, follow the documentation at https://strimzi.io.
-
Create a Kubernetes Secret with credentials for your container registry. It should follow the usual Kubernetes format:
apiVersion: v1 kind: Secret metadata: name: docker-credentials type: kubernetes.io/dockerconfigjson data: .dockerconfigjson: Cg==
If you are going to use the OpenShift built-in registry, please eliminate this part and refer to the comment section in
02-connect.yaml. -
Register for the Twitter API, you need to apply for elevated access for Twitter API v2. Create a Kubernetes Secret with the Twitter credentials in the following format:
apiVersion: v1 kind: Secret metadata: name: twitter-credentials type: Opaque data: consumerKey: Cg== consumerSecret: Cg== accessToken: Cg== accessTokenSecret: Cg==
-
Deploy the Kafka cluster:
kubectl apply -f 01-kafka.yaml -
Once Kafka cluster is ready, deploy the Kafka Connect cluster which will also download the Camel Kafka Connectors for Twitter
kubectl apply -f 02-connect.yaml
-
Deploy the Camel Twitter Timeline connector
kubectl apply -f 10-timeline.yamlThat should create a topic
twitter-timelineand start sending the twitter statuses to this topic. You can usekafkacatto check them:kafkacat -C -b <brokerAddress> -o beginning -t twitter-timeline | jq .text -
Deploy the Word Cloud and Tag Cloud applications:
kubectl apply -f 11-timeline-word-cloud.yaml kubectl apply -f 12-timeline-tag-cloud.yamlThey create Ingress resources to be able to access their API and UI. If needed, you might need to customize the Ingress or replace it with Route etc. The source code for both applications is part of the repository. You should see a word cloud similar to this:


-
Deploy the Camel Twitter Search connector
kubectl apply -f 20-search.yamlThat should create a topic
twitter-searchand start sending the twitter statuses to this topic. You can change the search term in the connector configuration (YAML file) You can usekafkacatto check them:kafkacat -C -b <brokerAddress> -o beginning -t twitter-search | jq .text -
Deploy the Camel Twitter Timeline connector
kubectl apply -f 21-alerts.yamlThat should create a topic
twitter-alertsand consume it. When a message is sent to this topic, it will be published to your timeline as a retweet. As an alternative, you can also uncomment the Camel Twitter DM connector and instead of your timeline send it as a direct message to the account specified in.spec.configincamel.sink.path.user(Update this to your Twitter screen name (username) before deploying the connector). You can usekafkacatto check them:kafkacat -C -b <brokerAddress> -o beginning -t twitter-alerts | jq .text -
Deploy the Sentiment Analysis applications:
kubectl apply -f 22-sentiment-analysis.yamlNow you can test the sentiment analysis by sending tweets with the hashtag specified in
.camel.source.path.keywords: "#YOURHASHTAG". It will read the tweets found by the search connector and do a sentiment analysis of them. If they are positive or negative on more than 90%, it will forward them to the alert topic. The connector will pick them up from this topic and send them as re-tweets on your Twitter account.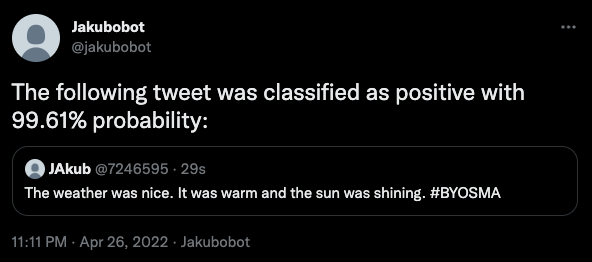

- Open the
ad-hocproject in an IDE. Check out the source code and configure it in./src/main/resources/application.properties. If you want, change the code to prepare a new experiment. Once ready, run the code usingmvn quarkus:devand watch the output.
You can use also other examples and play with them.
The files 90-kafka-search.yaml, 91-strimzi-search.yaml, and 92-avfc-search.yaml contain some other example searches as well.
These commands might be useful when playing with the demo:
-
Stop the application
-
Reset the application context
bin/kafka-streams-application-reset.sh --bootstrap-servers <brokerAddress> --application-id <applicationId> --execute -
Reset the offset
hacking/kafka/bin/kafka-consumer-groups.sh --bootstrap-server <brokerAddress> --group <applicationId> --topic <sourceTopic> --to-earliest --reset-offsets --execute
kafkacat -G <groupId> -C -b <brokerAddress> -o beginning -t <topic> | jq .text
You can also pipe the output to jq to pretty-print the JSON and use jq to for example extract the status message:
kafkacat -G <groupId> -C -b <brokerAddress> -o beginning -t <topic> | jq .text
This talk was done at DoK (Data on Kubernetes) Community meetup. You can watch the recording on YouTube. Or you can also listen to it as a podcast.

This talk was presented at MakeIT 2022 in-person conference. There is no recording, but you can have a look at the slides.
This talk was presented at DevConf.CZ 2022. You can have a look at the slides and the recording from the conference here:

This talk was presented at DataCon LA 2021. You can have a look at the slides and the recording from the conference here:
