-
El siguiente proyecto es un predictor de la demanda de un sistema de bikesharing. Está planteado como un proyecto final del Máster de Data Science de Nodd3r. Les comparto su web y agradezco especialmente a Christian Donaire que me ayudó mucho en todo este proceso de aprendizaje.
También cabe destacar que este proyecto ha sido inspirado en el curso de Pau Labarta Bajo en el que se contruye un predictor de demanda del servicio de taxi de Nueva York.
-
¿Que es un sistema de bikesharing? Es el sistema de bicicletas de modalidad compartidas, es decir que cada ciudadano puede usarlas y luego dejarlas en estaciones específicas para ello. Estos sistemas están presentes en distintas ciudades. En el siguiente proyecto se hará un prototipo de predicción de demanda para planificar donde deberían haber más bicicletas en determinadas horas.
Por tanto, el problema que se busca resolver es el rebalanceo de bicicletas🚲➡️🚛 en sistemas de bikesharing. Pero ¿qué es el rebalanceo? Básicamente sería mover las bicicletas de una estación a otra para que cuando vayas encuentres bicicletas para realizar tu viaje.
Para ello se plantea predecir la demanda de bicicletas de las siguientes 36 horas. ¿Para qué 36 horas? Para que la empresa que realiza ese trabajo pueda tener un tiempo considerable para preveer los picos de demanda.
-
¿Cómo? Basado en los datos de demanda de las horas anteriores se buscará predecir la demanda de las siguientes 36 horas.
Para ello utilicé el dataset del Gobierno de la Cuidad de Buenos Aires que se actualiza mensualmente para lograr este propósito.
Cabe destacar que utilicé "poetry" para crear un entorno virtual y tener más comodidad para gestionar librerías. Además utilicé un feature store llamado "hopsworks" con el que guardo los datos históricos, el modelo creado y las predicciones.
También utilicé github actions para automatizar el script de descarga de features de la web del gobierno de buenos aires y la subida a hopsworks. También hice lo mismo con las predicciones, es decir un script que cada hora predice, y sube a hopsworks esa predicción. Esto fue hecho para que el tablero sólo tenga que consumir esos datos que están guardados y sea más rápido.
-
¿Qué modelo🤖 se utilizó para ello? Los modelos basados en XGBoost son muy útiles para predecir series de tiempo (y además mucho menos complejos que una red neuronal) pero para que funcionen correctamente se le debe dar los datos de una determinada manera que le facilita el aprendizaje.
-
En el notebook 1, 2, 3, 4 y 5 básicamente lo que se hizo fue:
- Descargar los datos y descomprimirlos.
- Realizar una limpieza y convertirlos a formato parquet dado que es un formato que es útil para el propósito que buscamos y tiene varias ventajas.
- Eliminar los minutos y segundos y aproximarlos a la hora previa.
- Agregar las horas que no hubieron viajes con el valor "cero" y graficar.
- Crear una función en la que obtenemos los índices de las distintas filas para luego darle la forma más adecuada al dataset para que el modelo aprenda.
- Crear ese dataset que el modelo utilizará para aprender. (La forma en la que transformamos el dataset es que pasan de ser 3 columnas con hora, viaje y estación, a una columna por cada hora, junto con la información de la estación y la hora de referencia. Es decir del dataset original tomamos una cantidad de filas (horas previas y siguientes) y realizamos una transposición, luego bajamos una fila y repetimos el proceso. En este caso utilizamos 672 horas previas es decir 28 días y 36 horas siguientes).
- Por último, se realizó una función que grafique los registros previos y los siguientes.
-
En el notebook 6, 7, 8, 9 y 10:
- Se divieron los datos en train y test.
- Se crearon un modelos base (sin aplicar Machine Learning) sobre los que comparar luego los modelos más complejos.
- Luego se probó con XGBoost y LightGBM dando mejores resultados éste último.
- Lo siguiente fue seguir con LightGBM y aplicarle feature engineering para mejorar el modelo. Para ello se agregó: el promedio de las últimas 4 semanas, latitud y longitud, hora y día de la semana.
- Se utilizó optuna para realizar un hyperparameter tuning del modelo.
-
En el notebook 11, 12, 13 y 14:
- Se creó el proyecto en Hopsworks (feature store). Lo cual nos permite ir guardando los distintos registros que se descargan. Para ello se debe crear un feature group en el que guardarlo y luego para poder consumirlo es más cómodo mediante un feature view. Para ello se van creando este tipo de figuras para poder guardar los datos.
- El notebook 12 básicamente lo que realiza es: descarga los datos de la web del Gobierno de Bs As, realiza una limpieza y lo sube al feature store. Para automatizar esto se utilizó un github action que se ejecuta cada hora.
- En el notebook 13 se obtiene el modelo, se guarda y se sube a CometML (que luego se lo utilizará para realizar las predicciones).
- En el notebook 14 se leen los distintos datos del feature store, se carga el modelo, se crean las predicciones y se las guarda en el feature store. Para automatizarlo se creo otra github action que se ejecuta inmediatamente después de que termina la otra github action.
-
También tenemos otros archivos en las carpeta src. En ellas hay distintas funciones que se utilizan en los distintos notebooks para no tener que repetir la función. Por tanto sólo con importarla ya se puede utilizar. Además dentro de esa carpeta están los dos tableros que ahora comentaré:
- El primer tablero es el de frontend el cual consulta al feature store y carga los datos previos y las predicciones correspondientes. Además se grafica un mapa en el que se puede ver la estación que tendrá más demanda en las próximas 36 horas (en la descripción está la demanda esperada y la hora). Luego más abajo se encontrarán los gráficos que del top 10 de estaciones con la máxima demanda.
- El segundo tabledo es el de frontend monitoring en el que se puede observar el error global y el error de las estaciones con mayor demanda.
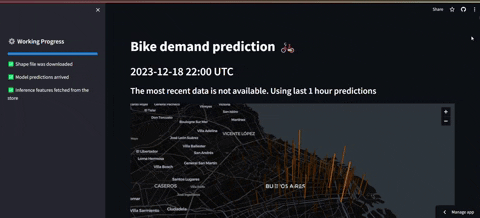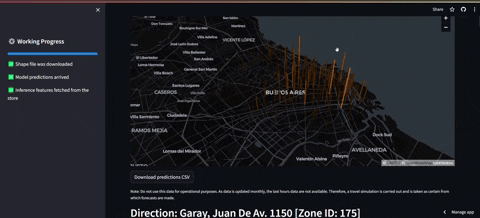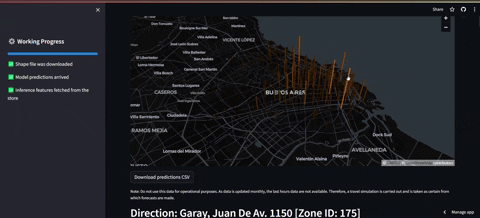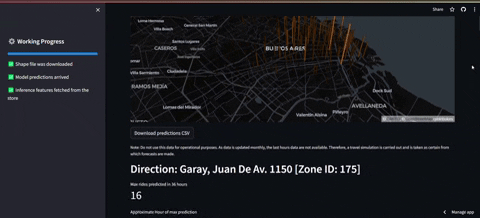
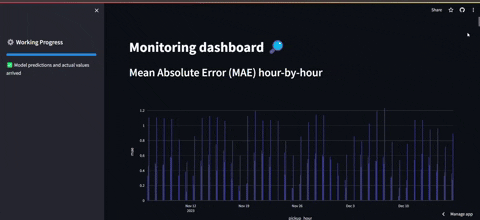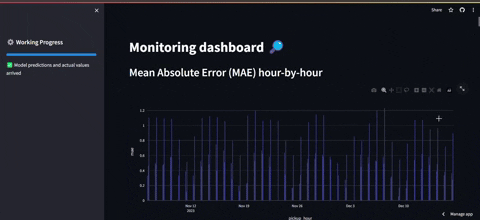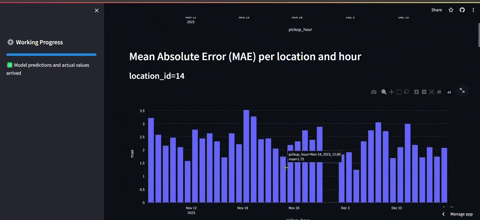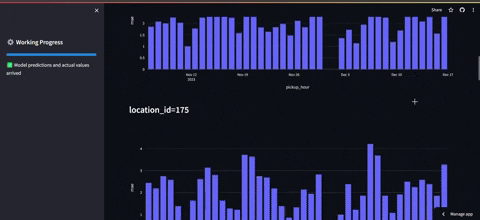
PD1: Cabe destacar que no se tiene acceso a los datos reales de la última hora. Por tanto para salvar eso, lo que se hace es una simulación de consulta en la que se obtienen datos de otro año que simulan ser la última hora, para luego incluirlos en la base de datos.
PD2: En caso de que al abrir los tableros aparezca un error, volver a cargar la página para solucionarlo.