Organizar código como https://github.com/graykode/nlp-tutorial
Post with usful links: transformers are gnns
- 🛠 Pipeline
- 🔤 Tokenization
- 🔮 Models
- 👨🏻🏫 Transfer Learning
- 📉 Losses
- 📏 Metrics
- Preprocess
- Tokenization: Split the text into sentences and the sentences into words.
- Lowercasing: Usually done in Tokenization
- Punctuation removal: Remove words like
.,,,:. Usually done in Tokenization - Stopwords removal: Remove words like
and,the,him. Done in the past. - Lemmatization: Verbs to root form:
organizes,will organizeorganizing→organizeThis is better. - Stemming: Nouns to root form:
democratic,democratization→democracy. This is faster.
- Extract features
- Document features
- Word features
- Word Vectors: Unique representation for every word (independent of its context).
- Word2Vec: By Google in 2013
- GloVe: By Standford
- FastText: By Facebook
- Contextualized Word Vectors: Good for polysemic words (meaning depend of its context).
- Word Vectors: Unique representation for every word (independent of its context).
- Build model
- Bag of Embeddings
- Linear algebra/matrix decomposition
- Latent Semantic Analysis (LSA) that uses Singular Value Decomposition (SVD).
- Non-negative Matrix Factorization (NMF)
- Latent Dirichlet Allocation (LDA): Good for BoW
- Neural nets
- Recurrent NNs decoder (LSTM, GRU)
- Transformer decoder (GPT, BERT, ...) ⭐
- Hidden Markov Models
- Regular expressions: (Regex) Find patterns.
- Parse trees: Syntax od a sentence
- Character tokenization
- Subword tokenization The best, used in recent models. ⭐
- Word tokenization: Used in traditional NLP.

- Byte Pair Encoding (BPE): Used in GPT-2 (2015)
- WordPiece: Used in BERT (2016)
- Unigram Language Model: (2018)
- SentencePiece: (2018)

BPE tokenization of the word _subwords
Probability of N words together. Read this.

Toy corpus:
<start>Ilikeapples<end><start>Ilikeoranges<end><start>Idonotlikebroccoli<end>Then:
- P(
<start> I like) = P(I|<start>) * P(like|I) = 1 * 0.66 = 0.66- P(
<start> I like apples) = P(I|<start>) * P(like|I) * P(apples|like) = 1 * 0.66 * 0.5 = 0.33
- RNN: Recurrent Nets. No parallel tokens
☹️ - GRU
- LSTM
- AWD-LSTM: regular LSTM with tuned dropout hyper-parameters.
- CNN: Convolutional Nets. Parallel tokens 🙂
- Lightweight & Dynamic Convs
- QRNN: Quasi-Recurrent Net. Used in MultiFiT

- Tricks
- Teacher forcing: Feed to the decoder the correct previous word, insted of the predicted previous word (at the beggining of training)
- Attention: Learns weights to perform a weighted average of the words embeddings.
| Self-Attention (Transformer Encoder) |
Masked Self-Attention (Transformer Decoder) |
|
|---|---|---|
 |
 |
|
| Advantage | Context on both sides | Auto-Regression |
| Pretraining | Bidirectional LM (better) | Unidirectional LM |
| Examples | BERT | GPT, GPT-2 |
| Best one | ALBERT ? | T5, Meena ? |
| Applications | Clasification | Text generation |
- Auto-Regression is when the final output token becomes input.
- Original transformer combines both encoder and decoder, (is the only transformer doing this).
- Transformer-XL is a recurrent transformer decoder.
- XLNet has both Context on both sides and Auto-Regression.
- 🤗 Huggingface transformers is a package with pretrained transformers models (PyTorch & Tensorflow).
| Model | Creator | Date | Breif description | 🤗 |
|---|---|---|---|---|
| 1st Transfor. | Jun. 2017 | Transforer encoder & decoder | ||
| ULMFiT | Fast.ai | Jan. 2018 | Regular LSTM | |
| ELMo | AllenNLP | Feb. 2018 | Bidirectional LSTM | |
| GPT | OpenAI | Jun. 2018 | Transformer decoder on LM | ✔ |
| BERT | Oct. 2018 | Transformer encoder on MLM (& NSP) | ✔ | |
| TransformerXL | Jan. 2019 | Recurrent transformer decoder | ✔ | |
| XLM/mBERT | Jan. 2019 | Multilingual LM | ✔ | |
| Transf. ELMo | AllenNLP | Jan. 2019 | ||
| GPT-2 | OpenAI | Feb. 2019 | Good text generation | ✔ |
| ERNIE | Baidu | Apr. 2019 | ||
| ERNIE | Tsinghua | May. 2019 | Transformer with Knowledge Graph | |
| XLNet | Jun. 2019 | BERT + Transformer-XL | ✔ | |
| RoBERTa | Jul. 2019 | BERT without NSP | ✔ | |
| DistilBERT | Hug. Face | Aug. 2019 | Compressed BERT | ✔ |
| MiniBERT | Aug. 2019 | Compressed BERT | ||
| MultiFiT | Fast.ai | Sep. 2019 | Multi-lingual ULMFiT (QRNN) post | |
| CTRL | Salesforce | Sep. 2019 | Controllable text generation | ✔ |
| MegatronLM | Nvidia | Sep. 2019 | Big models with parallel training | |
| ALBERT | Sep. 2019 | Reduce BERT params (param sharing) | ✔ | |
| DistilGPT-2 | Hug. Face | Oct. 2019 | Compressed GPT-2 | ✔ |
| T5 | Oct. 2019 | Text-to-Text Transfer Transformer | ✔ | |
| ELECTRA | ? | Dec. 2019 | An efficient LM pretraining | |
| Reformer | Jan. 2020 | The Efficient Transformer | ||
| Meena | Jan. 2020 | A Human-like Open-Domain Chatbot |
| Model | 2L | 3L | 6L | 12L | 18L | 24L | 36L | 48L | 54L | 72L |
|---|---|---|---|---|---|---|---|---|---|---|
| 1st Transformer | yes | |||||||||
| ULMFiT | yes | |||||||||
| ELMo | yes | |||||||||
| GPT | 110M | |||||||||
| BERT | 110M | 340M | ||||||||
| Transformer-XL | 257M | |||||||||
| XLM/mBERT | Yes | Yes | ||||||||
| Transf. ELMo | ||||||||||
| GPT-2 | 117M | 345M | 762M | 1542M | ||||||
| ERNIE | Yes | |||||||||
| XLNet: | 110M | 340M | ||||||||
| RoBERTa | 125M | 355M | ||||||||
| MegatronLM | 355M | 2500M | 8300M | |||||||
| DistilBERT | 66M | |||||||||
| MiniBERT | Yes | |||||||||
| ALBERT | ||||||||||
| CTRL | 1630M | |||||||||
| DistilGPT-2 | 82M |
- Attention: (Aug 2015)
- Allows the network to refer back to the input sequence, instead of forcing it to encode all information into ane fixed-lenght vector.
- Paper: Effective Approaches to Attention-based Neural Machine Translation
- blog
- attention and memory
- 1st Transformer: (Google AI, jun. 2017)
- Introduces the transformer architecture: Encoder with self-attention, and decoder with attention.
- Surpassed RNN's State of the Art
- Paper: Attention Is All You Need
- blog.
- ULMFiT: (Fast.ai, Jan. 2018)
- Regular LSTM Encoder-Decoder architecture with no attention.
- Introduces the idea of transfer-learning in NLP:
- Take a trained tanguge model: Predict wich word comes next. Trained with Wikipedia corpus for example (Wikitext 103).
- Retrain it with your corpus data
- Train your task (classification, etc.)
- Paper: Universal Language Model Fine-tuning for Text Classification
- ELMo: (AllenNLP, Feb. 2018)
- Context-aware embedding = better representation. Useful for synonyms.
- Made with bidirectional LSTMs trained on a language modeling (LM) objective.
- Parameters: 94 millions
- Paper: Deep contextualized word representations
- site.
- GPT: (OpenAI, Jun. 2018)
- Made with transformer trained on a language modeling (LM) objective.
- Same as transformer, but with transfer-learning for ther NLP tasks.
- First train the decoder for language modelling with unsupervised text, and then train other NLP task.
- Parameters: 110 millions
- Paper: Improving Language Understanding by Generative Pre-Training
- site, code.
- BERT: (Google AI, oct. 2018)
- Bi-directional training of transformer:
- Replaces language modeling objective with "masked language modeling".
- Words in a sentence are randomly erased and replaced with a special token ("masked").
- Then, a transformer is used to generate a prediction for the masked word based on the unmasked words surrounding it, both to the left and right.
- Parameters:
- BERT-Base: 110 millions
- BERT-Large: 340 millions
- Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Official code
- blog
- fastai alumn blog
- blog3
- slides
- Bi-directional training of transformer:
- Transformer-XL: (Google/CMU, Jan. 2019)
- Learning long-term dependencies
- Resolved Transformer's Context-Fragmentation
- Outperforms BERT in LM
- Paper: Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- blog
- google blog
- code.
- XLM/mBERT: (Facebook, Jan. 2019)
- Multilingual Language Model (100 languages)
- SOTA on cross-lingual classification and machine translation
- Parameters: 665 millions
- Paper: Cross-lingual Language Model Pretraining
- code
- blog
- Transformer ELMo: (AllenNLP, Jan. 2019)
- Parameters: 465 millions
- GPT-2: (OpenAI, Feb. 2019)
- Zero-Shot task learning
- Coherent paragraphs of generated text
- Parameters: 1500 millions
- Site
- Paper: Language Models are Unsupervised Multitask Learners
- ERNIE (Baidu research, Apr. 2019)
- World-aware, Structure-aware, and Semantic-aware tasks
- Continual pre-training
- Paper: ERNIE: Enhanced Representation through Knowledge Integration
- XLNet: (Google/CMU, Jun. 2019)
- Auto-Regressive methods for LM
- Best both BERT + Transformer-XL
- Parameters: 340 millions
- Paper: XLNet: Generalized Autoregressive Pretraining for Language Understanding
- code
- RoBERTa (Facebook, Jul. 2019)
- Facebook's improvement over BERT
- Optimized BERT's training process and hyperparameters
- Parameters:
- RoBERTa-Base: 125 millions
- RoBERTa-Large: 355 millions
- Trained on 160GB of text
- Paper RoBERTa: A Robustly Optimized BERT Pretraining Approach
- Reformer: The Efficient Transformer
- https://openreview.net/forum?id=rkgNKkHtvB
- Aims to improve the complexity from O(L^2) to O(L).
- Useful when sequences tend to be quiet long.
- Facebook: Making Transformer networks simpler and more efficient
- Adaptive Attention Span: Make Transformers more efficient for longer sentences (over 8000 tokens)
- Only attention layer: Simpler & more efficient architecture
- Sharing Attention Weights for Fast Transformer
- Tokenizer: Create subword tokens. Methods: BPE...
- Embedding: Create vectors for each token. Sum of:
- Token Embedding
- Positional Encoding: Information about tokens order (e.g. sinusoidal function).
- Dropout
- Normalization
- Multi-head attention layer (with a left-to-right attention mask)
- Each attention head uses self attention to process each token input conditioned on the other input tokens.
- Left-to-right attention mask ensures that only attends to the positions that precede it to the left.
- Normalization
- Feed forward layers:
- Linear H→4H
- GeLU activation func
- Linear 4H→H
- Normalization
- Output embedding
- Softmax
- Label smothing: Ground truth -> 90% the correct word, and the rest 10% divided on the other words.
- Lowest layers: morphology
- Middle layers: syntax
- Highest layers: Task-specific semantics
| Step | Task | Data | Who do this? |
|---|---|---|---|
| 1 | Language Model Pretraining | 📚 Lot of text corpus (eg. Wikipedia) | 🏭 Google or Facebook |
| 2 | Language Model Finetunning | 📗 Only you domain text corpus | 💻 You |
| 3 | Your supervised task | 📗🏷️ You labeled domain text | 💻 You |
![]()
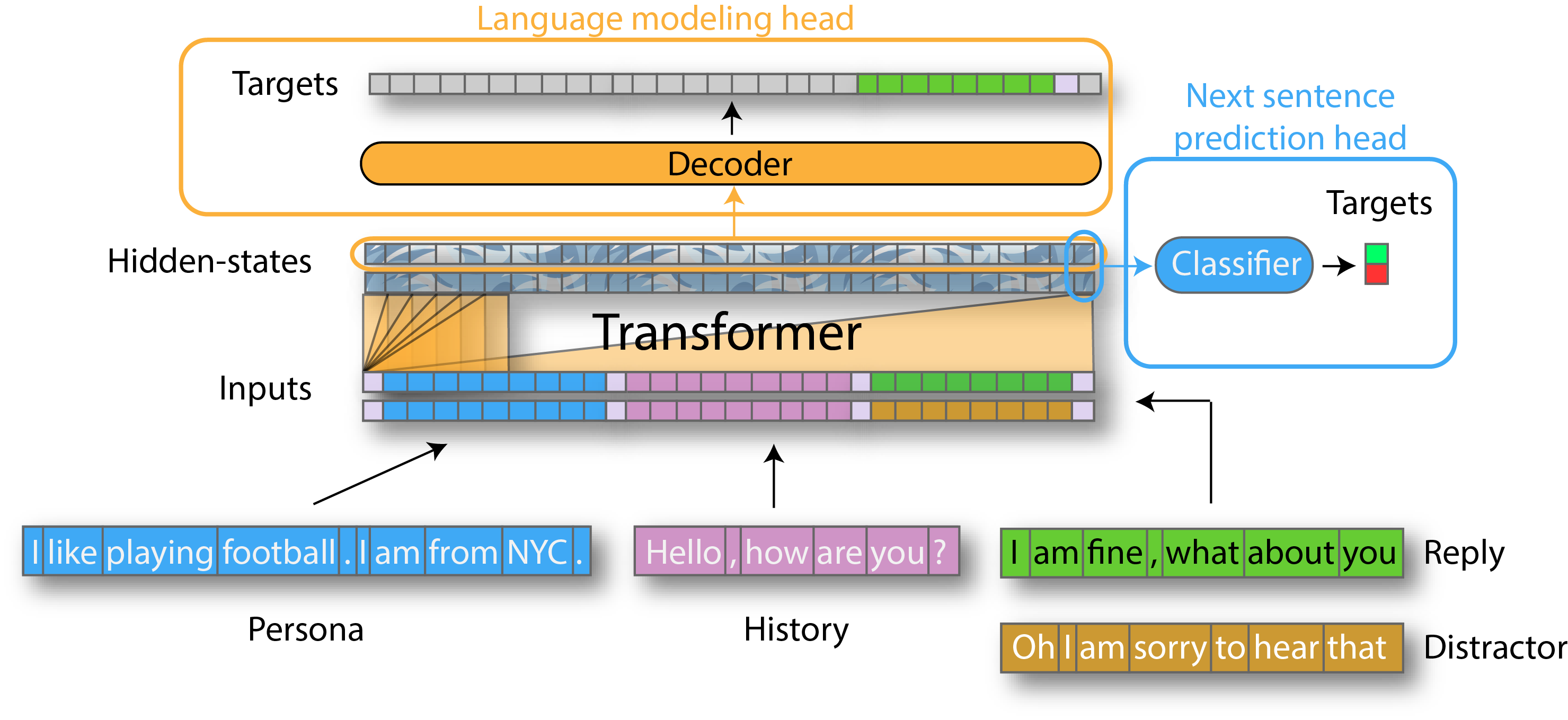
- Language modeling: we project the hidden-state on the word embedding matrix to get logits and apply a cross-entropy loss on the portion of the target corresponding to the gold reply.
- Next-sentence prediction: we pass the hidden-state of the last token (the end-of-sequence token) through a linear layer to get a score and apply a cross-entropy loss to classify correctly a gold answer among distractors.
| Score | Description | Interpretation |
|---|---|---|
| Perplexity | LM | The lower the better. |
| GLUE | An avergae of different scores for NLU | |
| BLEU | For Translation. Compare generated with reference sentences (N-gram) | The higher the better. |
| RACE | ReAding Comprehension dataset collected from English Examinations | The higher the better. |
| SQuAD | Stanford Question Answering Dataset | The higher the better. |
"He ate the apple" & "He ate the potato" has the same BLEU score.
| Application | Description | Type |
|---|---|---|
| 🏷️ Part-of-speech tagging (POS) | Identify nouns, verbs, adjectives, etc. (aka Parsing). | 🔤 |
| 📍 Named entity recognition (NER) | Identify names, organizations, locations, medical codes, etc. | 🔤 |
| 👦🏻❓ Coreference Resolution | Identify several ocuurences on the same person/objet like he, she | 🔤 |
| 🔍 Text categorization | Identify topics present in a text (sports, politics, etc). | 🔤 |
| ❓ Question answering | Answer questions of a given text (SQuAD, DROP dataset). | 💭 |
| 👍🏼 👎🏼 Sentiment analysis | Possitive or negative comment/review classification. | 💭 |
| 🔮 Language Modeling (LM) | Predict the next word. Unupervised. | 💭 |
| 🔮 Masked Language Modeling (MLM) | Predict the omitted words. Unupervised. | 💭 |
| 📗→📄 Summarization | Crate a short version of a text. | 💭 |
| 🈯→🆗 Translation | Translate into a different language. | 💭 |
| 🆓→🆒 Chatbot | Interact in a conversation. | 💭 |
| 💁🏻→🔠 Speech recognition | Speech to text. See AUDIO cheatsheet. | 🗣️ |
| 🔠→💁🏻 Speech generation | Text to speech. See AUDIO cheatsheet. | 🗣️ |
- 🔤: Natural Language Processing (NLP)
- 💭: Natural Language Understanding (NLU)
- 🗣️: Speech and sound (speak and listen)
![]()
Read this paper

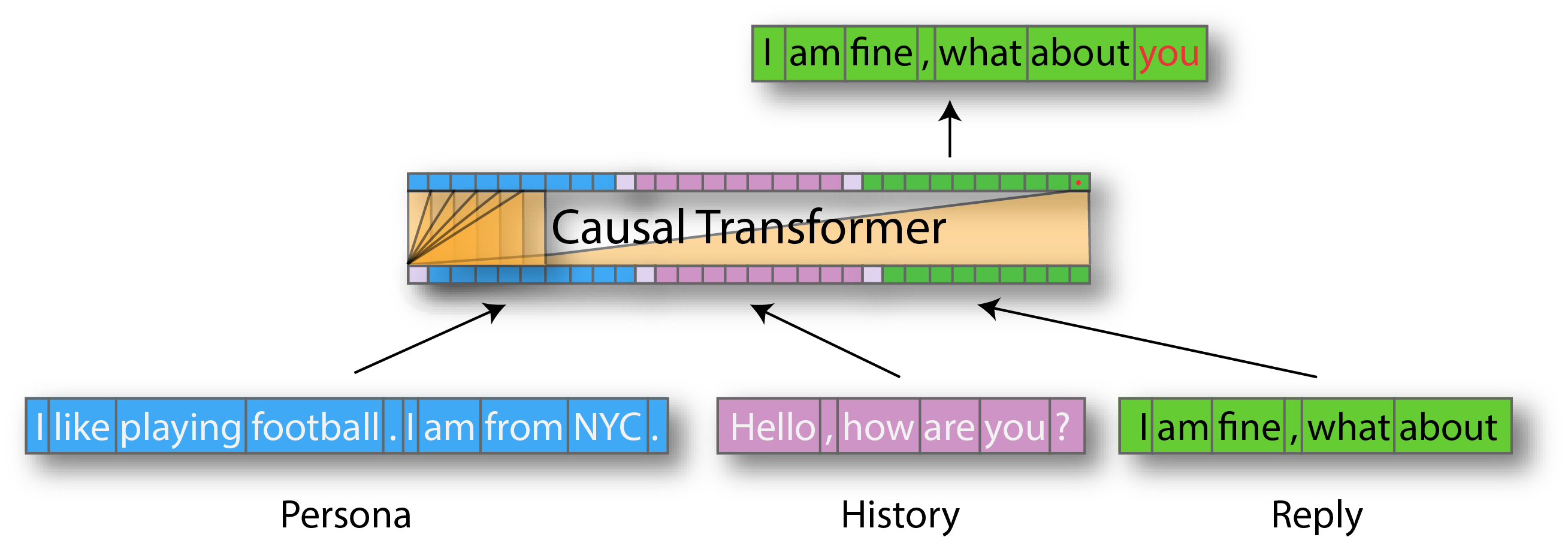
Model backbone: Transformer decoder like GPT or GPT2 (pretrained for LM).
- Persona: One or several personality sentences. (BLUE)
- History: The history of the dialog. (PINK)
- Reply: The tokens of the current answer. (GREEN)

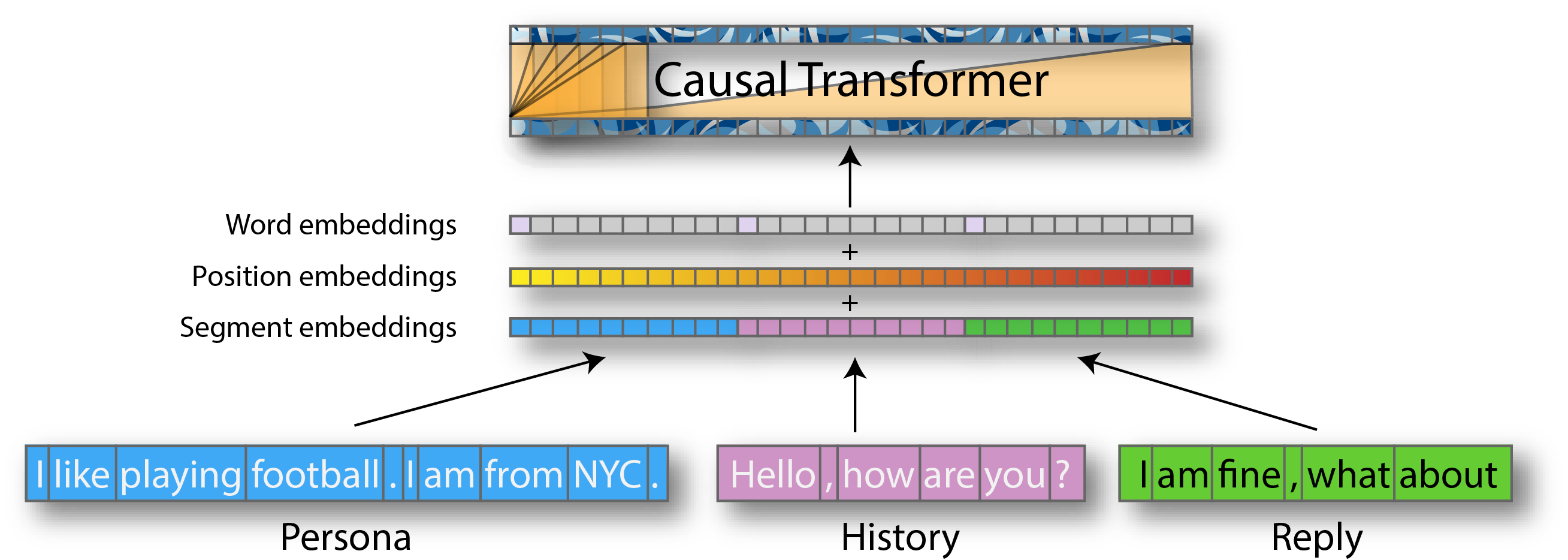
- Word embedding: Information about word semantics.
- Position embedding: Information about word order.
- Segment embedding: nformation about type (personality, history or reply).

- One head for language modeling loss.
- Other head for next-sentence classification loss.

- TO-DO read:
- NLP Year in Review — 2019 (Jan 2020) ⭐
- Read NLP, Recent Trends (August 2019) ⭐
- Read MASS: transfer learning in translation for transformers?
- Read CNNs better than attention
- Modern NLP
- Courses
- Fast.ai NLP course: playlist
- spaCy course
- 5 videos
- Transformers
- The Illustrated Transformer (June 2018)
- The Illustrated BERT & ELMo (December 2018)
- The Illustrated GPT-2 (August 2019) ⭐
- Best Transformers explanation (August 2019) ⭐
- ALL Transformers with chart
- BERT:
- From Attention in Transformers to Dynamic Routing in Capsule Nets
- DistilBERT model by huggingface
- Transfer Learning in NLP by Sebastian Ruder
- Hardvard NLP papers
- Sebastian Ruder webpage
- 7 NLP libraries
- spaCy blog
- Attention and Memory
- Fast.ai NLP Videos
- What is NLP? ✔
- Topic Modeling with SVD & NMF
- Topic Modeling & SVD revisited
- Sentiment Classification with Naive Bayes
- Sentiment Classification with Naive Bayes & Logistic Regression, contd.
- Derivation of Naive Bayes & Numerical Stability
- Revisiting Naive Bayes, and Regex
- Intro to Language Modeling
- Transfer learning
- ULMFit for non-English Languages
- Understanding RNNs
- Seq2Seq Translation
- Word embeddings quantify 100 years of gender & ethnic stereotypes
- Text generation algorithms
- Implementing a GRU
- Algorithmic Bias
- Introduction to the Transformer ✔
- The Transformer for language translation ✔
- What you need to know about Disinformation